Personality Alignment of Large Language Models

0

Sign in to get full access
Overview
- This paper investigates the ability of large language models to align with human personality traits.
- Researchers constructed a dataset of human personality profiles and used it to assess how well language models can reflect these traits.
- The findings provide insights into the potential and limitations of current language models in capturing complex human characteristics.
Plain English Explanation
The paper examines how well large artificial intelligence (AI) systems, called language models, can adapt their personality and behavior to match those of individual humans. The researchers created a dataset of detailed personality profiles for real people, then tested how closely the language models could mimic those unique traits and behaviors when interacting with users.
The goal was to see if these powerful AI systems, which are trained on vast amounts of text data, could learn to communicate in a way that feels natural and aligned with a user's specific personality. This could be important for creating AI assistants or chatbots that feel more personalized and relatable.
The findings suggest that current language models have some ability to capture certain personality characteristics, but also have significant limitations. They may struggle to fully reflect the nuance and complexity of human personalities. Further research is needed to improve the "personality alignment" capabilities of AI systems.
Technical Explanation
The paper describes the construction of a Personality Alignment Dataset, which contains detailed personality profiles for a large number of individuals. These profiles were generated using standard psychological assessment tools that measure traits across the Big Five personality dimensions (openness, conscientiousness, extraversion, agreeableness, and neuroticism).
The researchers then tested how well several state-of-the-art language models could generate text that aligned with these individual personality profiles. This involved prompting the models to produce responses in the style of a particular person, and evaluating how well the output matched the target personality.
The results indicate that the language models had some ability to capture certain personality traits, such as extraversion and agreeableness. However, they struggled to fully reflect the nuanced, multidimensional nature of human personality. The models also tended to regress towards the "mean" personality, failing to capture the extremes or idiosyncrasies of individual profiles.
Critical Analysis
The paper acknowledges several limitations of the research. The personality dataset, while large, may not fully represent the diversity of human personalities. Additionally, the evaluation methodology relied on automated metrics, which may not fully capture the subjective and contextual nature of personality perception.
Further research is needed to explore more advanced techniques for aligning language models with human personality. This could involve fine-tuning the models on personality-relevant data, or incorporating additional signals beyond just textual output, such as tone, facial expressions, or nonverbal behavior.
It's also important to consider the ethical implications of developing AI systems that can closely mimic human personalities. There are concerns about the potential for deception, manipulation, or the erosion of authentic human-to-human interactions.
Conclusion
This paper presents an important step towards understanding the capabilities and limitations of large language models in capturing and reflecting human personality traits. The findings suggest that while current models have some ability to align with personality characteristics, there is still significant room for improvement.
Advancing this area of research could lead to more personalized and engaging AI assistants and chatbots. However, it also raises important ethical considerations that will need to be carefully addressed as the technology continues to evolve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Personality Alignment of Large Language Models
Minjun Zhu, Linyi Yang, Yue Zhang
Current methods for aligning large language models (LLMs) typically aim to reflect general human values and behaviors, but they often fail to capture the unique characteristics and preferences of individual users. To address this gap, we introduce the concept of Personality Alignment. This approach tailors LLMs' responses and decisions to match the specific preferences of individual users or closely related groups. Inspired by psychometrics, we created the Personality Alignment with Personality Inventories (PAPI) dataset, which includes data from 300,000 real subjects, each providing behavioral preferences based on the Big Five Personality Factors. This dataset allows us to quantitatively evaluate the extent to which LLMs can align with each subject's behavioral patterns. Recognizing the challenges of personality alignments: such as limited personal data, diverse preferences, and scalability requirements: we developed an activation intervention optimization method. This method enhances LLMs' ability to efficiently align with individual behavioral preferences using minimal data and computational resources. Remarkably, our method, PAS, achieves superior performance while requiring only 1/5 of the optimization time compared to DPO, offering practical value for personality alignment. Our work paves the way for future AI systems to make decisions and reason in truly personality ways, enhancing the relevance and meaning of AI interactions for each user and advancing human-centered artificial intelligence.The code has released in url{https://github.com/zhu-minjun/PAlign}.
Read more8/22/2024
💬
0
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, Jad Kabbara
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
Read more4/3/2024
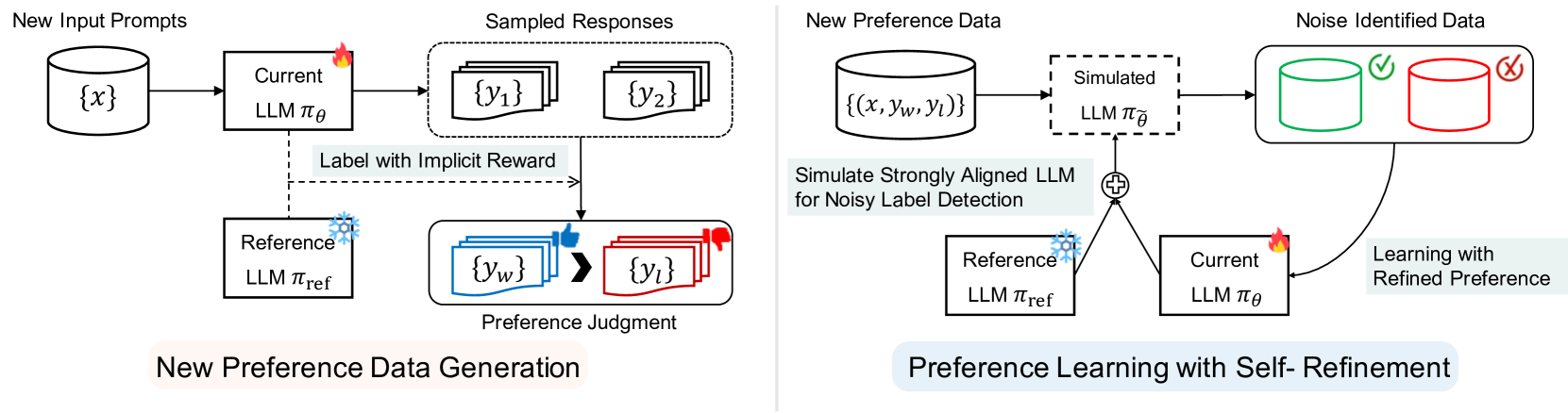
0
Aligning Large Language Models with Self-generated Preference Data
Dongyoung Kim, Kimin Lee, Jinwoo Shin, Jaehyung Kim
Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
Read more6/10/2024

0
Investigating Cultural Alignment of Large Language Models
Badr AlKhamissi, Muhammad ElNokrashy, Mai AlKhamissi, Mona Diab
The intricate relationship between language and culture has long been a subject of exploration within the realm of linguistic anthropology. Large Language Models (LLMs), promoted as repositories of collective human knowledge, raise a pivotal question: do these models genuinely encapsulate the diverse knowledge adopted by different cultures? Our study reveals that these models demonstrate greater cultural alignment along two dimensions -- firstly, when prompted with the dominant language of a specific culture, and secondly, when pretrained with a refined mixture of languages employed by that culture. We quantify cultural alignment by simulating sociological surveys, comparing model responses to those of actual survey participants as references. Specifically, we replicate a survey conducted in various regions of Egypt and the United States through prompting LLMs with different pretraining data mixtures in both Arabic and English with the personas of the real respondents and the survey questions. Further analysis reveals that misalignment becomes more pronounced for underrepresented personas and for culturally sensitive topics, such as those probing social values. Finally, we introduce Anthropological Prompting, a novel method leveraging anthropological reasoning to enhance cultural alignment. Our study emphasizes the necessity for a more balanced multilingual pretraining dataset to better represent the diversity of human experience and the plurality of different cultures with many implications on the topic of cross-lingual transfer.
Read more7/9/2024