Aligning Large Language Models with Self-generated Preference Data
2406.04412
0
0
Abstract
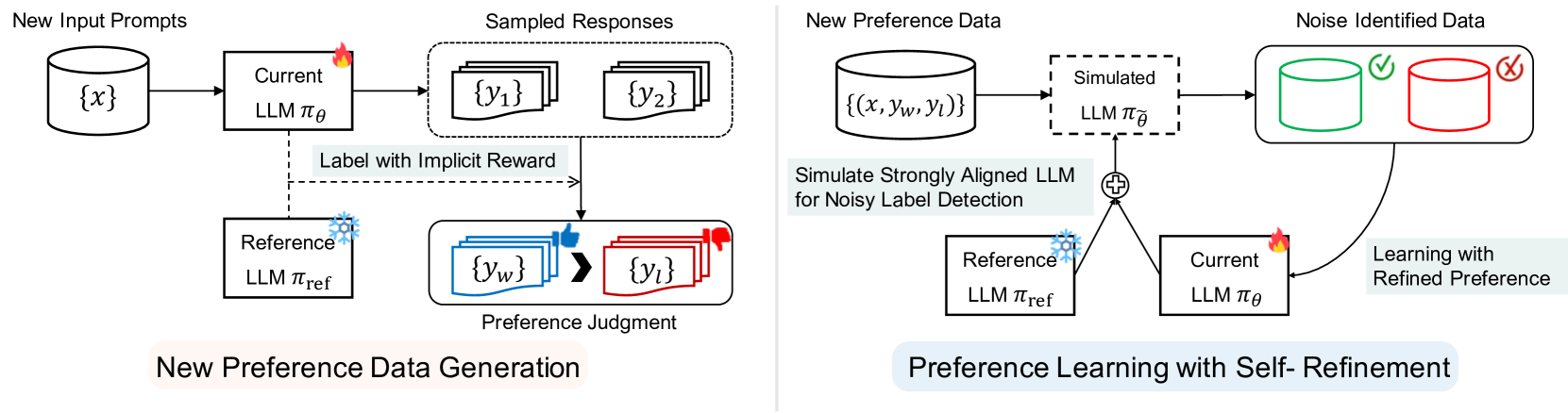
Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
Create account to get full access
Overview
- This paper explores methods for aligning large language models with human preferences by training the models on self-generated preference data.
- The researchers investigate techniques to ensure language models behave in alignment with human values and objectives, which is an important challenge as these models become more capable and influential.
- The paper covers related work, the researchers' proposed approach, technical details, experiments, and a critical analysis of the findings.
Plain English Explanation
The paper focuses on a critical challenge in the development of advanced AI systems like large language models: ensuring they behave in alignment with human preferences and values. As these models become increasingly capable, it's essential that they reliably act in ways that benefit humanity rather than causing harm.
The researchers explored methods for training language models on "self-generated preference data" - essentially, allowing the models to practice making choices and expressing preferences, which can then be used to fine-tune the models to behave more in line with human values. This builds on previous work in this area and related approaches.
In their experiments, the researchers tested different techniques for generating the preference data and incorporating it into the model training process. They found that this approach can indeed help align language models with human preferences, though there are still important limitations and challenges to address, as discussed in the critical analysis.
The core insight is that by allowing AI systems to practice making choices and expressing preferences, we can gradually shape their behavior to be more in tune with human values - a process that could be crucial as these models become increasingly powerful and influential in society.
Technical Explanation
The paper explores methods for aligning large language models with human preferences by training the models on self-generated preference data. This builds on previous work in preference learning and fine-tuning language models to instill human values.
The key idea is to have the language model itself generate preference data, which can then be used to fine-tune the model to behave more in line with those preferences. This is done by training the model to output not just text, but also a "preference score" indicating how much it values or prefers the generated text.
The researchers experimented with different techniques for generating the preference data, including:
- Having the model generate paired options (e.g. two paragraphs) and score its preference between them
- Training the model to generate a preference score directly for a given piece of text
They incorporated this preference data into the model training process using techniques like multi-task learning, where the model is trained to both generate text and predict preference scores.
Experiments showed that this approach can indeed help align language models with human preferences, as measured by human evaluation of the model's outputs. However, the paper also discusses important limitations, such as the potential for the model to "game the system" and generate preference data that doesn't truly reflect human values.
Critical Analysis
The paper makes a valuable contribution by exploring methods to align large language models with human preferences. However, it also acknowledges several important caveats and limitations that warrant further research.
One key limitation is the potential for the model to "game the system" by generating preference data that doesn't accurately reflect human values. The researchers note that more work is needed to ensure the preference data truly aligns with intended human preferences.
Additionally, the paper only evaluates the approach using relatively simple preference tasks. It's unclear how well these techniques would scale to more complex, real-world decision-making scenarios where there may be nuanced tradeoffs and competing priorities. More research is needed to understand the limitations and potential pitfalls of this approach in more realistic settings.
Another area for further exploration is the potential for self-supervised visual preference alignment, which could allow language models to learn preferences not just from text, but from richer multimodal data. This could provide a more holistic understanding of human values.
Overall, this paper represents an important step forward in the critical challenge of aligning advanced AI systems with human preferences. However, significant work remains to develop robust and scalable solutions that can reliably ensure these powerful models behave in ways that benefit humanity.
Conclusion
This paper explores methods for aligning large language models with human preferences by training the models on self-generated preference data. The key insight is that by allowing AI systems to practice making choices and expressing preferences, we can gradually shape their behavior to be more in tune with human values - a process that could be crucial as these models become increasingly powerful and influential.
While the experiments showed promise, the paper also acknowledges important limitations and areas for further research, such as ensuring the preference data truly reflects intended human values, scaling the approach to more complex real-world scenarios, and incorporating multimodal data. Addressing these challenges will be crucial as researchers and practitioners work to develop advanced AI systems that reliably behave in alignment with human interests.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey on Human Preference Learning for Large Language Models
Ruili Jiang, Kehai Chen, Xuefeng Bai, Zhixuan He, Juntao Li, Muyun Yang, Tiejun Zhao, Liqiang Nie, Min Zhang
0
0
The recent surge of versatile large language models (LLMs) largely depends on aligning increasingly capable foundation models with human intentions by preference learning, enhancing LLMs with excellent applicability and effectiveness in a wide range of contexts. Despite the numerous related studies conducted, a perspective on how human preferences are introduced into LLMs remains limited, which may prevent a deeper comprehension of the relationships between human preferences and LLMs as well as the realization of their limitations. In this survey, we review the progress in exploring human preference learning for LLMs from a preference-centered perspective, covering the sources and formats of preference feedback, the modeling and usage of preference signals, as well as the evaluation of the aligned LLMs. We first categorize the human feedback according to data sources and formats. We then summarize techniques for human preferences modeling and compare the advantages and disadvantages of different schools of models. Moreover, we present various preference usage methods sorted by the objectives to utilize human preference signals. Finally, we summarize some prevailing approaches to evaluate LLMs in terms of alignment with human intentions and discuss our outlooks on the human intention alignment for LLMs.
6/19/2024
Aligning Large Language Models from Self-Reference AI Feedback with one General Principle
Rong Bao, Rui Zheng, Shihan Dou, Xiao Wang, Enyu Zhou, Bo Wang, Qi Zhang, Liang Ding, Dacheng Tao
0
0
In aligning large language models (LLMs), utilizing feedback from existing advanced AI rather than humans is an important method to scale supervisory signals. However, it is highly challenging for AI to understand human intentions and societal values, and provide accurate preference feedback based on these. Current AI feedback methods rely on powerful LLMs, carefully designed specific principles to describe human intentions, and are easily influenced by position bias. To address these issues, we propose a self-reference-based AI feedback framework that enables a 13B Llama2-Chat to provide high-quality feedback under simple and general principles such as ``best for humanity``. Specifically, we allow the AI to first respond to the user's instructions, then generate criticism of other answers based on its own response as a reference, and finally determine which answer better fits human preferences according to the criticism. Additionally, we use a self-consistency method to further reduce the impact of position bias, and employ semantic perplexity to calculate the preference strength differences between different answers. Experimental results show that our method enables 13B and 70B Llama2-Chat annotators to provide high-quality preference feedback, and the policy models trained based on these preference data achieve significant advantages in benchmark datasets through reinforcement learning.
6/18/2024
💬
Aligning language models with human preferences
Tomasz Korbak
0
0
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
4/19/2024

Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
0
0
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
4/17/2024