Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning

0
Sign in to get full access
Overview
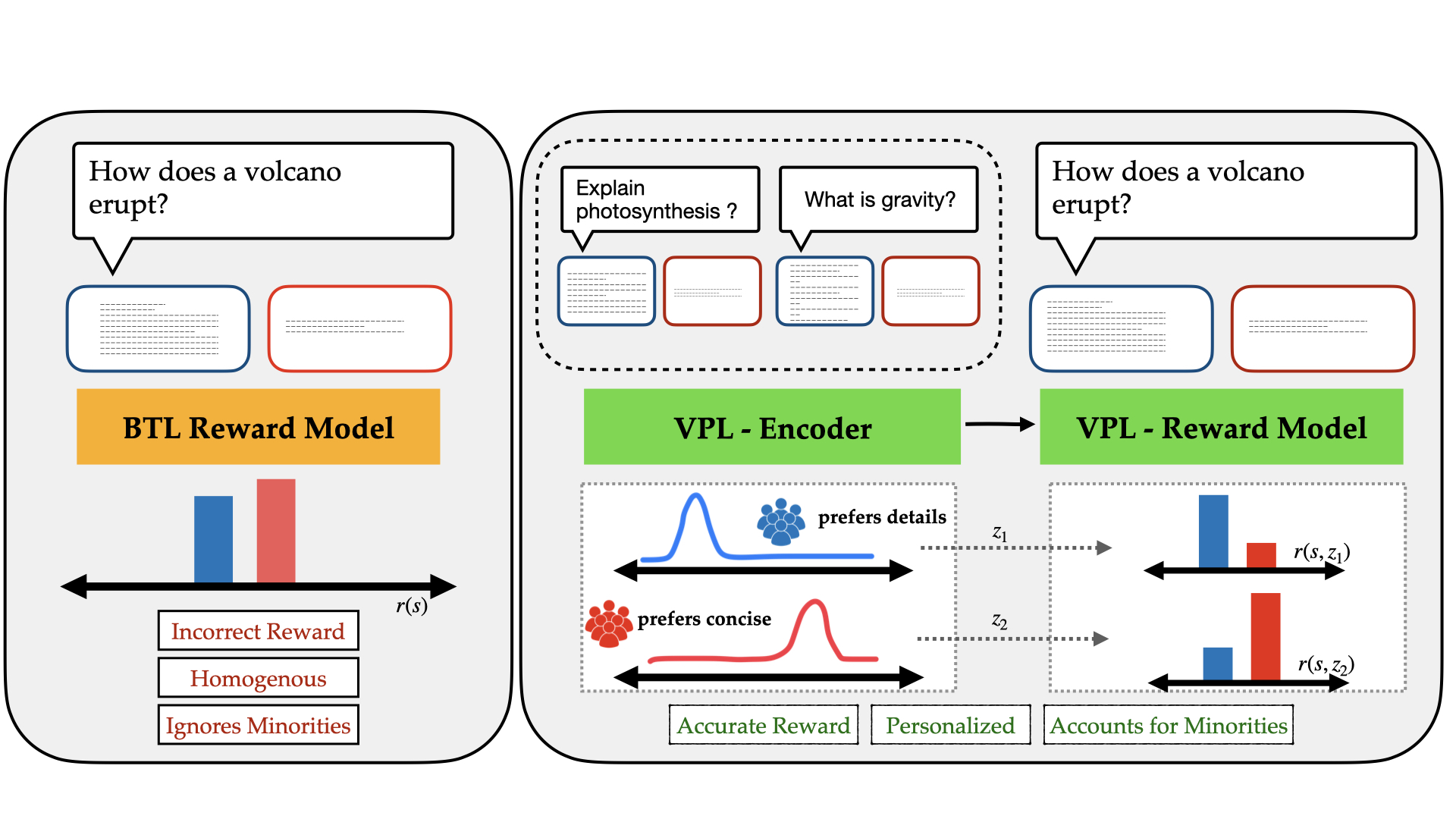
- This paper proposes a framework for personalizing reinforcement learning (RL) from human feedback using variational preference learning.
- The key idea is to learn a personalized reward function for each user based on their preferences, which are inferred from heterogeneous feedback.
- This allows the RL agent to be optimized for the user's individual preferences, rather than a one-size-fits-all approach.
Plain English Explanation
The paper introduces a new way to personalize reinforcement learning (RL) algorithms based on feedback from human users. Typically, RL systems are trained to optimize a single, general reward function that aims to capture what's best for everyone. However, different people often have different preferences and opinions about what's desirable.
This framework addresses this by learning a personalized reward function for each individual user. It does this by using variational preference learning to infer each user's preferences from the heterogeneous feedback they provide, which could include ratings, rankings, or other forms of input.
By optimizing the RL agent for this personalized reward function, rather than a one-size-fits-all approach, the system can better align with the individual user's goals and values. This allows the RL agent to behave in a way that is tailored to what each specific user finds most desirable, rather than a generic "best" behavior.
Technical Explanation
The paper proposes a framework for Personalized Reinforcement Learning from Human Feedback (PRLHF), which consists of two key components:
-
Variational Preference Learning: This module learns a personalized reward function for each user by inferring their preferences from heterogeneous feedback, such as ratings, rankings, or other forms of input. It uses a variational Bayesian approach to model the user's preferences as a distribution over possible reward functions.
-
Personalized Reinforcement Learning: The personalized reward function learned in the first step is then used to optimize the RL agent's behavior for each individual user, rather than a single, generic reward function. This allows the agent to learn a policy that is tailored to the user's specific preferences.
The framework is evaluated on a range of simulated environments, where it is shown to outperform standard RL approaches in terms of aligning the agent's behavior with the user's preferences. The authors also discuss how this approach could be extended to real-world applications, such as personalized recommender systems or assistive technologies.
Critical Analysis
The key strength of this research is its ability to personalize RL agents to individual users, rather than relying on a one-size-fits-all approach. This can lead to more satisfying and aligned behavior, as the agent is optimized for the user's specific preferences.
However, the paper does not fully address some potential limitations and challenges:
-
Scalability: The framework requires learning a separate reward function for each user, which could become computationally expensive as the number of users grows. Techniques for efficiently sharing or transferring learned preferences across users may be needed.
-
Robustness to diverse feedback: The paper primarily focuses on simulated environments with relatively simple feedback mechanisms. Handling more complex, noisy, or even adversarial human feedback in real-world settings may require additional techniques.
-
Interpretability and transparency: The learned personalized reward functions may be opaque or difficult for users to understand. Developing more interpretable models could improve user trust and engagement.
-
Ethical considerations: Personalizing RL systems to individual preferences raises important questions about privacy, fairness, and the potential for manipulation or unintended consequences. Careful consideration of these issues is crucial.
Overall, this research represents an important step towards more personalized and user-centric RL systems. However, further work is needed to address the scalability, robustness, and ethical challenges that come with deploying such technologies in the real world.
Conclusion
This paper presents a framework for Personalized Reinforcement Learning from Human Feedback (PRLHF), which aims to tailor RL agents to the individual preferences of users. By learning a personalized reward function for each user through variational preference learning, the system can optimize the agent's behavior to better align with the user's goals and values.
This approach has the potential to lead to more satisfying and engaging interactions with RL-based systems, as the agent's behavior is customized to the user's unique preferences. However, the research also highlights the need to address scalability, robustness, interpretability, and ethical considerations as this technology moves towards real-world deployment.
Overall, this work represents an important step forward in the field of personalized AI, and it will be exciting to see how future research builds upon these ideas to create even more user-centric and adaptable reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024
0
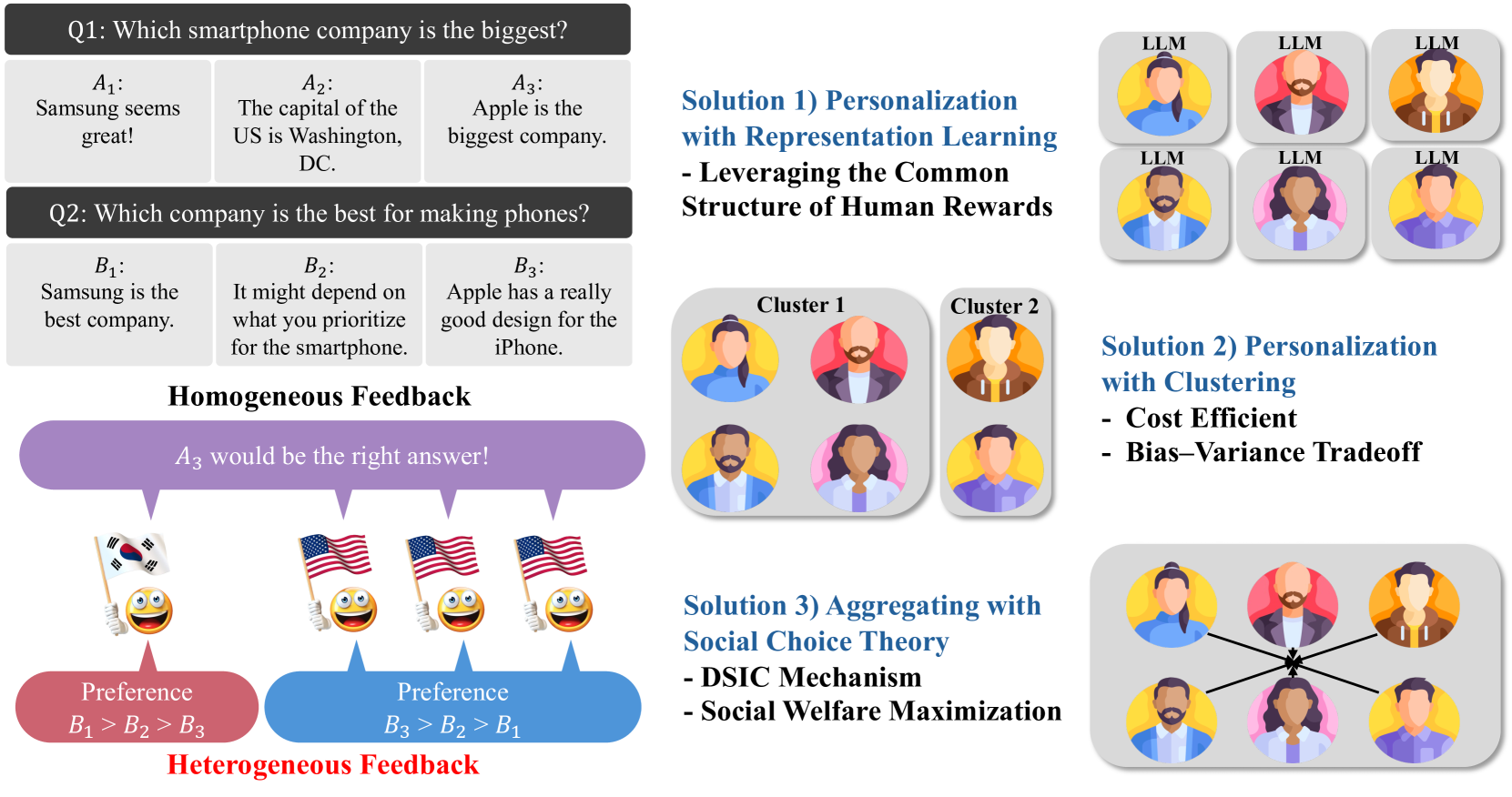
Principled RLHF from Heterogeneous Feedback via Personalization and Preference Aggregation
Chanwoo Park, Mingyang Liu, Dingwen Kong, Kaiqing Zhang, Asuman Ozdaglar
Reinforcement learning from human feedback (RLHF) has been an effective technique for aligning AI systems with human values, with remarkable successes in fine-tuning large-language models recently. Most existing RLHF paradigms make the underlying assumption that human preferences are relatively homogeneous, and can be encoded by a single reward model. In this paper, we focus on addressing the issues due to the inherent heterogeneity in human preferences, as well as their potential strategic behavior in providing feedback. Specifically, we propose two frameworks to address heterogeneous human feedback in principled ways: personalization-based one and aggregation-based one. For the former, we propose two approaches based on representation learning and clustering, respectively, for learning multiple reward models that trades off the bias (due to preference heterogeneity) and variance (due to the use of fewer data for learning each model by personalization). We then establish sample complexity guarantees for both approaches. For the latter, we aim to adhere to the single-model framework, as already deployed in the current RLHF paradigm, by carefully aggregating diverse and truthful preferences from humans. We propose two approaches based on reward and preference aggregation, respectively: the former utilizes both utilitarianism and Leximin approaches to aggregate individual reward models, with sample complexity guarantees; the latter directly aggregates the human feedback in the form of probabilistic opinions. Under the probabilistic-opinion-feedback model, we also develop an approach to handle strategic human labelers who may bias and manipulate the aggregated preferences with untruthful feedback. Based on the ideas in mechanism design, our approach ensures truthful preference reporting, with the induced aggregation rule maximizing social welfare functions.
Read more5/28/2024
🏅
0
Multi-turn Reinforcement Learning from Preference Human Feedback
Lior Shani, Aviv Rosenberg, Asaf Cassel, Oran Lang, Daniele Calandriello, Avital Zipori, Hila Noga, Orgad Keller, Bilal Piot, Idan Szpektor, Avinatan Hassidim, Yossi Matias, R'emi Munos
Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
Read more5/24/2024

0
Personalized Language Modeling from Personalized Human Feedback
Xinyu Li, Zachary C. Lipton, Liu Leqi
Reinforcement Learning from Human Feedback (RLHF) is commonly used to fine-tune large language models to better align with human preferences. However, the underlying premise of algorithms developed under this framework can be problematic when user preferences encoded in human feedback are diverse. In this work, we aim to address this problem by developing methods for building personalized language models. We first formally introduce the task of learning from personalized human feedback and explain why vanilla RLHF can be ineffective in this context. We then propose a general Personalized-RLHF (P-RLHF) framework, including a user model that maps user information to user representations and can flexibly encode our assumptions on user preferences. We develop new learning objectives to perform personalized Direct Preference Optimization that jointly learns a user model and a personalized language model. We demonstrate the efficacy of our proposed method through (1) a synthetic task where we fine-tune a GPT-J 6B model to align with users with conflicting preferences on generation length; and (2) an instruction following task where we fine-tune a Tulu-7B model to generate responses for users with diverse preferences on the style of responses. In both cases, our learned models can generate personalized responses that are better aligned with the preferences of individual users.
Read more7/9/2024