Personalized Language Modeling from Personalized Human Feedback

0

Sign in to get full access
Overview
- This paper presents a method for personalizing language models by incorporating personalized human feedback during the training process.
- The researchers develop a framework called Personalized Language Modeling from Personalized Human Feedback (PLMPHF) that aims to align language models with individual user preferences.
- The approach uses reinforcement learning from human feedback (RLHF) to fine-tune a pre-trained language model based on personalized feedback.
- This allows the model to generate text that is tailored to the preferences and communication styles of individual users.
Plain English Explanation
The paper describes a way to create language models that are personalized to individual users. Typically, language models are trained on a large amount of general text data, which can result in outputs that don't fully match the preferences and communication styles of specific users.
The researchers developed a framework called PLMPHF that addresses this by using reinforcement learning from human feedback (RLHF). In this approach, the language model is first pre-trained on a large dataset, and then fine-tuned using personalized feedback from individual users.
This allows the model to learn the unique preferences and communication styles of each user, and generate text that is tailored to their needs. For example, the model could learn to write emails in a more formal or casual tone based on the user's feedback.
By creating personalized language models, the researchers aim to improve the user experience and the overall alignment between the model's outputs and the individual's preferences.
Technical Explanation
The paper proposes the Personalized Language Modeling from Personalized Human Feedback (PLMPHF) framework, which combines reinforcement learning from human feedback (RLHF) with personalization techniques to create language models that are tailored to individual users.
The approach first pre-trains a base language model on a large corpus of general text data. It then fine-tunes this model using personalized feedback from individual users, following the multi-turn reinforcement learning from preference human feedback paradigm.
During the fine-tuning process, the user provides feedback on the model's generated text, indicating their preferences. This feedback is used to update the model's parameters, allowing it to learn the user's unique communication style and preferences.
The researchers also explore several techniques to enhance the personalization process, such as Nash learning from human feedback and personalization from heterogeneous feedback.
By aligning the language model with human preferences, the PLMPHF framework aims to generate text that is more relevant, engaging, and tailored to the individual user's needs.
Critical Analysis
The paper presents a promising approach for personalizing language models, but it also acknowledges several caveats and areas for further research:
- The success of the personalization process may depend on the quality and consistency of the user feedback, which can be challenging to obtain in real-world settings.
- The framework's performance may be limited by the size and diversity of the pre-training dataset, as well as the specific fine-tuning techniques used.
- The researchers note that further work is needed to explore the long-term stability and generalization of the personalized models, as well as their scalability to larger and more diverse user populations.
Additionally, the potential ethical implications of highly personalized language models, such as the risk of reinforcing individual biases or creating "filter bubbles," should be carefully considered and addressed in future research.
Conclusion
The Personalized Language Modeling from Personalized Human Feedback (PLMPHF) framework presented in this paper represents a significant step towards creating language models that are tailored to individual users' preferences and communication styles.
By incorporating personalized feedback into the training process, the researchers have demonstrated the potential to improve the alignment between language model outputs and user needs. This could lead to more engaging, relevant, and effective interactions with language AI systems in a wide range of applications, from personal assistants to content creation tools.
While the paper highlights several areas for further research and development, the core ideas and techniques presented here have the potential to advance the field of personalized language modeling and contribute to the broader goal of creating AI systems that better serve the diverse needs of individual users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Personalized Language Modeling from Personalized Human Feedback
Xinyu Li, Zachary C. Lipton, Liu Leqi
Reinforcement Learning from Human Feedback (RLHF) is commonly used to fine-tune large language models to better align with human preferences. However, the underlying premise of algorithms developed under this framework can be problematic when user preferences encoded in human feedback are diverse. In this work, we aim to address this problem by developing methods for building personalized language models. We first formally introduce the task of learning from personalized human feedback and explain why vanilla RLHF can be ineffective in this context. We then propose a general Personalized-RLHF (P-RLHF) framework, including a user model that maps user information to user representations and can flexibly encode our assumptions on user preferences. We develop new learning objectives to perform personalized Direct Preference Optimization that jointly learns a user model and a personalized language model. We demonstrate the efficacy of our proposed method through (1) a synthetic task where we fine-tune a GPT-J 6B model to align with users with conflicting preferences on generation length; and (2) an instruction following task where we fine-tune a Tulu-7B model to generate responses for users with diverse preferences on the style of responses. In both cases, our learned models can generate personalized responses that are better aligned with the preferences of individual users.
Read more7/9/2024
0
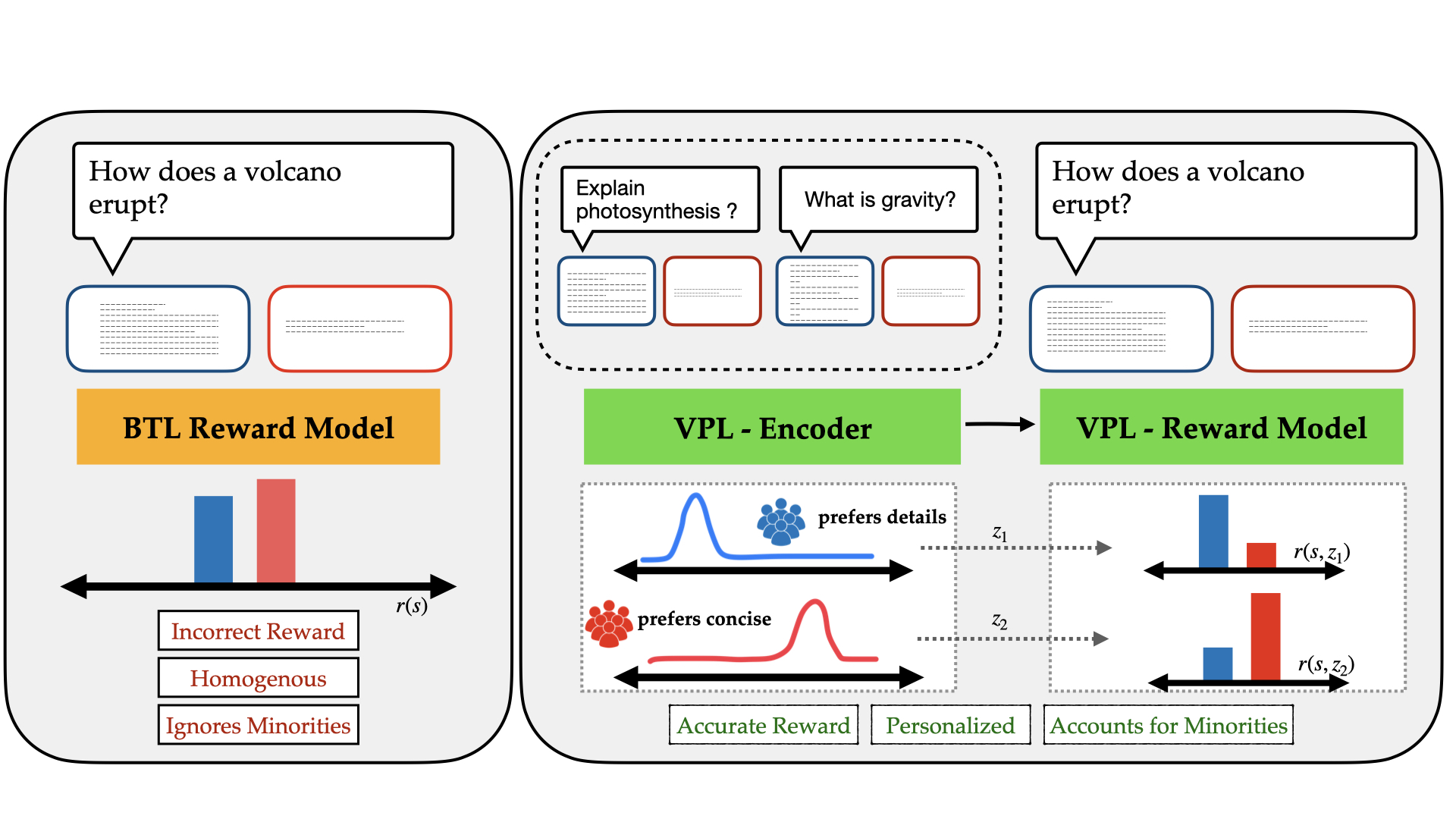
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024

0
Orchestrating LLMs with Different Personalizations
Jin Peng Zhou, Katie Z Luo, Jingwen Gu, Jason Yuan, Kilian Q. Weinberger, Wen Sun
This paper presents a novel approach to aligning large language models (LLMs) with individual human preferences, sometimes referred to as Reinforcement Learning from textit{Personalized} Human Feedback (RLPHF). Given stated preferences along multiple dimensions, such as helpfulness, conciseness, or humor, the goal is to create an LLM without re-training that best adheres to this specification. Starting from specialized expert LLMs, each trained for one such particular preference dimension, we propose a black-box method that merges their outputs on a per-token level. We train a lightweight Preference Control Model (PCM) that dynamically translates the preference description and current context into next-token prediction weights. By combining the expert models' outputs at the token level, our approach dynamically generates text that optimizes the given preference. Empirical tests show that our method matches or surpasses existing preference merging techniques, providing a scalable, efficient alternative to fine-tuning LLMs for individual personalization.
Read more7/8/2024
🏅
0
Multi-turn Reinforcement Learning from Preference Human Feedback
Lior Shani, Aviv Rosenberg, Asaf Cassel, Oran Lang, Daniele Calandriello, Avital Zipori, Hila Noga, Orgad Keller, Bilal Piot, Idan Szpektor, Avinatan Hassidim, Yossi Matias, R'emi Munos
Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
Read more5/24/2024