PertEval: Unveiling Real Knowledge Capacity of LLMs with Knowledge-Invariant Perturbations

0

Sign in to get full access
Overview
- This paper introduces PertEval, a novel approach to evaluating the knowledge capacity of large language models (LLMs)
- PertEval uses "knowledge-invariant perturbations" to uncover the true limits of an LLM's factual knowledge, rather than relying on standard benchmarks
- The authors argue that existing evaluation methods often fail to accurately measure an LLM's knowledge, as they can be "gamed" by the model
Plain English Explanation
The paper proposes a new way to test the knowledge of large language models (LLMs) like GPT-3 or BERT. Current methods for evaluating LLMs tend to be limited, as the models can sometimes find ways to "cheat" on the tests and make it seem like they know more than they actually do.
The key idea behind PertEval is to introduce "perturbations" - small changes to the input - that don't affect the underlying knowledge required to answer a question. By seeing how the LLM's performance changes under these perturbations, the researchers can get a better sense of the model's true knowledge capacity, rather than just its ability to parrot memorized facts.
For example, if an LLM can answer a question about the capital of France correctly, but then gets it wrong when the question is phrased slightly differently, that suggests the model may not have a deep, robust understanding of that geographical knowledge. PertEval aims to dig deeper and uncover the limitations of LLM knowledge in a more comprehensive way.
Technical Explanation
The paper first reviews prior work on evaluating LLM knowledge, such as benchmarks and consistency-based approaches. The authors argue that these methods often fail to accurately measure the true limits of an LLM's factual knowledge.
To address this, PertEval introduces a new evaluation framework centered around "knowledge-invariant perturbations" - small changes to the input that do not affect the underlying knowledge required to answer a question correctly. By measuring how an LLM's performance changes under these perturbations, the researchers can gain insights into the model's true knowledge capacity, rather than just its ability to match patterns in the training data.
The paper describes the process of constructing these perturbations, as well as experiments evaluating several prominent LLMs on a range of knowledge-intensive tasks. The results suggest that existing benchmarks may overestimate the true factual knowledge of these models, and that PertEval can provide a more nuanced and informative assessment.
Critical Analysis
The PertEval approach offers a promising new direction for evaluating LLM knowledge, but the paper acknowledges several important limitations and areas for further research. For example, the perturbation techniques used may not be comprehensive enough to uncover all the subtle gaps in an LLM's knowledge, and the specific tasks and datasets employed may not generalize to real-world applications.
Additionally, while the paper demonstrates the limitations of existing benchmarks, it does not provide a complete solution. The authors note that PertEval is best used in conjunction with other evaluation methods to get a more holistic understanding of an LLM's capabilities.
There is also the potential concern that "gaming" the evaluation system is an inherent challenge when testing highly capable AI systems. As models become more sophisticated, they may find ways to exploit even the PertEval framework, requiring continuous refinement and innovation in evaluation methodologies.
Conclusion
Overall, the PertEval approach represents an important step forward in the ongoing effort to accurately measure the knowledge capacity of large language models. By moving beyond simplistic benchmarks and incorporating more nuanced, knowledge-focused perturbations, the researchers have developed a framework that can provide deeper insights into the strengths and limitations of these powerful AI systems.
As the field of natural language processing continues to advance, it will be crucial to have robust and comprehensive evaluation methods like PertEval to ensure that the real-world deployment of LLMs is done in a responsible and well-informed manner. This paper lays important groundwork for future research in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PertEval: Unveiling Real Knowledge Capacity of LLMs with Knowledge-Invariant Perturbations
Jiatong Li, Renjun Hu, Kunzhe Huang, Yan Zhuang, Qi Liu, Mengxiao Zhu, Xing Shi, Wei Lin
Expert-designed close-ended benchmarks serve as vital tools in assessing the knowledge capacity of large language models (LLMs). Despite their widespread use, concerns have mounted regarding their reliability due to limited test scenarios and an unavoidable risk of data contamination. To rectify this, we present PertEval, a toolkit devised for in-depth probing of LLMs' knowledge capacity through knowledge-invariant perturbations. These perturbations employ human-like restatement techniques to generate on-the-fly test samples from static benchmarks, meticulously retaining knowledge-critical content while altering irrelevant details. Our toolkit further includes a suite of transition analyses that compare performance on raw vs. perturbed test sets to precisely assess LLMs' genuine knowledge capacity. Six state-of-the-art LLMs are re-evaluated using PertEval. Results reveal significantly inflated performance of the LLMs on raw benchmarks, including an absolute 21% overestimation for GPT-4. Additionally, through a nuanced response pattern analysis, we discover that PertEval retains LLMs' uncertainty to specious knowledge, potentially being resolved through rote memorization and leading to inflated performance. We also find that the detailed transition analyses by PertEval could illuminate weaknesses in existing LLMs' knowledge mastery and guide the development of refinement. Given these insights, we posit that PertEval can act as an essential tool that, when applied alongside any close-ended benchmark, unveils the true knowledge capacity of LLMs, marking a significant step toward more trustworthy LLM evaluation.
Read more5/31/2024

0
RUPBench: Benchmarking Reasoning Under Perturbations for Robustness Evaluation in Large Language Models
Yuqing Wang, Yun Zhao
With the increasing use of large language models (LLMs), ensuring reliable performance in diverse, real-world environments is essential. Despite their remarkable achievements, LLMs often struggle with adversarial inputs, significantly impacting their effectiveness in practical applications. To systematically understand the robustness of LLMs, we present RUPBench, a comprehensive benchmark designed to evaluate LLM robustness across diverse reasoning tasks. Our benchmark incorporates 15 reasoning datasets, categorized into commonsense, arithmetic, logical, and knowledge-intensive reasoning, and introduces nine types of textual perturbations at lexical, syntactic, and semantic levels. By examining the performance of state-of-the-art LLMs such as GPT-4o, Llama3, Phi-3, and Gemma on both original and perturbed datasets, we provide a detailed analysis of their robustness and error patterns. Our findings highlight that larger models tend to exhibit greater robustness to perturbations. Additionally, common error types are identified through manual inspection, revealing specific challenges faced by LLMs in different reasoning contexts. This work provides insights into areas where LLMs need further improvement to handle diverse and noisy inputs effectively.
Read more6/18/2024
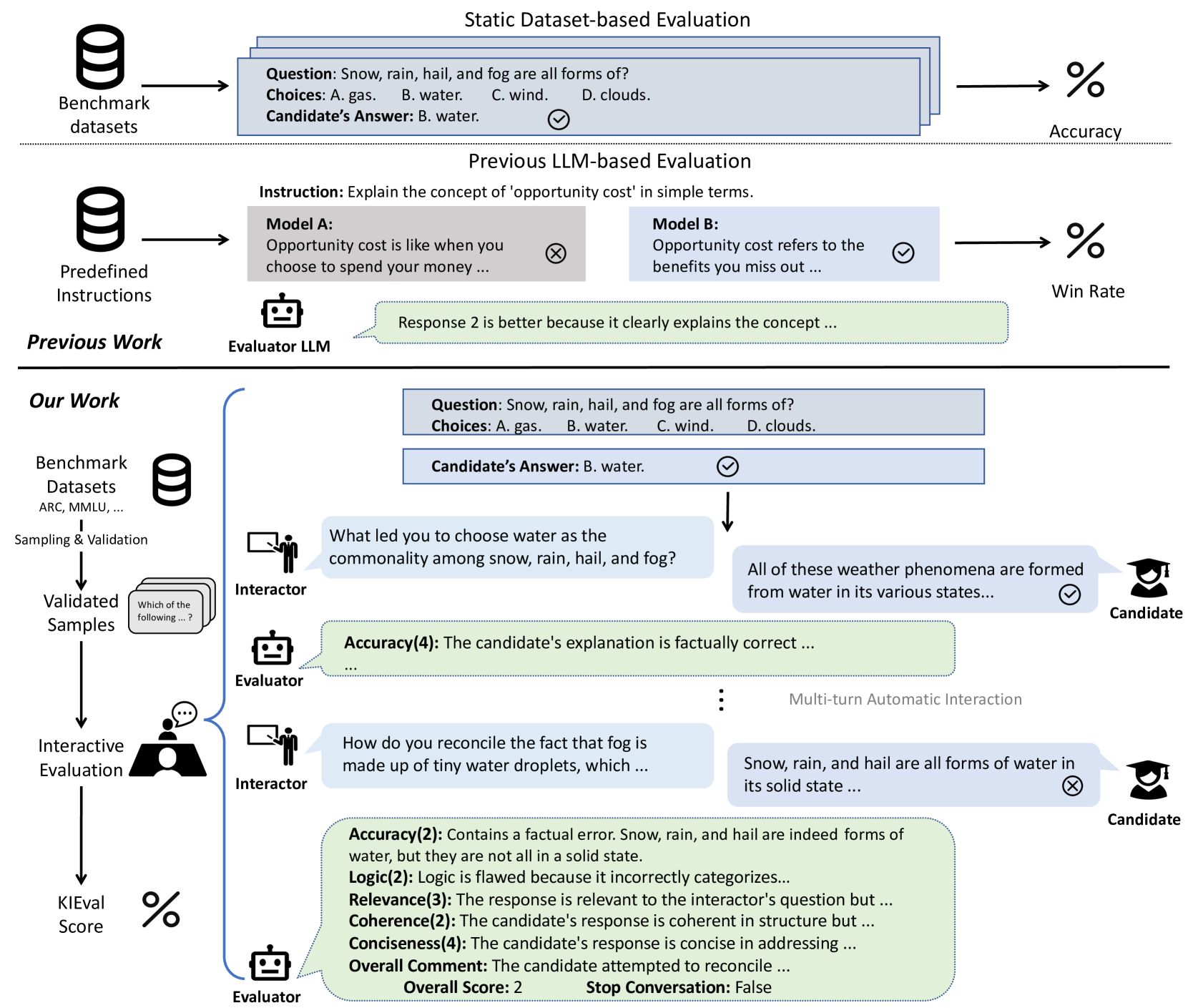
0
KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models
Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Wei Ye, Jindong Wang, Xing Xie, Yue Zhang, Shikun Zhang
Automatic evaluation methods for large language models (LLMs) are hindered by data contamination, leading to inflated assessments of their effectiveness. Existing strategies, which aim to detect contaminated texts, focus on quantifying contamination status instead of accurately gauging model performance. In this paper, we introduce KIEval, a Knowledge-grounded Interactive Evaluation framework, which incorporates an LLM-powered interactor role for the first time to accomplish a dynamic contamination-resilient evaluation. Starting with a question in a conventional LLM benchmark involving domain-specific knowledge, KIEval utilizes dynamically generated, multi-round, and knowledge-focused dialogues to determine whether a model's response is merely a recall of benchmark answers or demonstrates a deep comprehension to apply knowledge in more complex conversations. Extensive experiments on seven leading LLMs across five datasets validate KIEval's effectiveness and generalization. We also reveal that data contamination brings no contribution or even negative effect to models' real-world applicability and understanding, and existing contamination detection methods for LLMs can only identify contamination in pre-training but not during supervised fine-tuning.
Read more6/4/2024
🤿
0
Evaluate What You Can't Evaluate: Unassessable Quality for Generated Response
Yongkang Liu, Shi Feng, Daling Wang, Yifei Zhang, Hinrich Schutze
LLMs (large language models) such as ChatGPT have shown remarkable language understanding and generation capabilities. Although reference-free evaluators based on LLMs show better human alignment than traditional reference-based evaluators, there are many challenges in using reference-free evaluators based on LLMs. Reference-free evaluators are more suitable for open-ended examples with different semantics responses. But not all examples are open-ended. For closed-ended examples with unique correct semantic response, reference-free evaluators will still consider it high quality when giving a response that is inconsistent with the facts and the semantic of reference. In order to comprehensively evaluate the reliability of evaluators based on LLMs, we construct two adversarial meta-evaluation dialogue generation datasets KdConv-ADV and DSTC7-ADV based on KdConv and DSTC7-AVSD, respectively. Compared to previous meta-evaluation benchmarks, KdConv-ADV and DSTC7-ADV are much more challenging since they requires evaluators to be able to reasonably evaluate closed-ended examples with the help of external knowledge or even its own knowledge. Empirical results show that the ability of LLMs to identify unreasonable responses is insufficient. There are risks in using eference-free evaluators based on LLMs to evaluate the quality of dialogue responses.
Read more5/7/2024