KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models

0
Sign in to get full access
Overview
- Proposes KIEval, a knowledge-grounded interactive evaluation framework for assessing the performance of large language models (LLMs)
- Addresses limitations of existing LLM evaluation methods by incorporating interactive user feedback and knowledge-grounded assessments
- Aims to provide a more comprehensive and nuanced understanding of LLM capabilities and limitations
Plain English Explanation
KIEval is a new way to evaluate the performance of large language models (LLMs), which are AI systems that can generate human-like text. Existing methods for evaluating LLMs often rely on predefined benchmarks or tasks, which may not fully capture the models' real-world capabilities.
In contrast, KIEval takes a more interactive and knowledge-driven approach. It allows users to engage with the LLM in a conversational manner, asking questions and providing feedback. This feedback is then used to assess the model's understanding of the underlying knowledge and its ability to apply that knowledge effectively.
By incorporating this interactive element and grounding the evaluation in real-world knowledge, KIEval aims to provide a more nuanced and comprehensive assessment of LLM performance. This can help researchers, developers, and users better understand the strengths, limitations, and potential applications of these powerful AI models.
Technical Explanation
The key elements of the KIEval framework include:
-
Interactive Evaluation: KIEval allows users to engage with the LLM in a conversational manner, posing questions and providing feedback on the model's responses. This interactive approach helps capture the model's ability to understand and apply knowledge in real-time.
-
Knowledge-grounded Assessments: KIEval leverages a knowledge base to ground the evaluation in real-world information. This helps assess the LLM's understanding of the underlying knowledge and its ability to apply that knowledge effectively in the interactive dialogue.
-
Comprehensive Metrics: In addition to traditional evaluation metrics, KIEval introduces new measures that capture the model's knowledge coherence, knowledge retrieval, and knowledge application capabilities. These metrics provide a more holistic assessment of the LLM's performance.
The researchers demonstrate the effectiveness of KIEval through experiments on several popular LLMs, such as GPT-3 and PaLM. The results show that KIEval can identify strengths and weaknesses that are not readily apparent in standard benchmark evaluations, highlighting the potential of this interactive, knowledge-grounded approach.
Critical Analysis
The KIEval framework addresses important limitations of existing LLM evaluation methods, which often rely on predefined tasks or datasets that may not fully capture the models' real-world capabilities. By incorporating interactive user feedback and knowledge-grounded assessments, KIEval provides a more nuanced and comprehensive evaluation.
However, the paper does not discuss potential challenges in scaling KIEval to larger, more diverse user populations or in maintaining and updating the underlying knowledge base. Additionally, the paper could have explored the potential biases or limitations of the interactive evaluation process, such as the influence of user demographics or preconceptions on the assessment.
Further research could also investigate the reliability and reproducibility of KIEval's metrics, as well as its applicability to different domains and use cases beyond the current experiments.
Conclusion
The KIEval framework represents a significant advancement in the evaluation of large language models. By integrating interactive user feedback and knowledge-grounded assessments, it provides a more comprehensive and nuanced understanding of LLM capabilities and limitations. This approach has the potential to inform the development of more robust and trustworthy AI systems, ultimately benefiting researchers, developers, and end-users alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models
Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Wei Ye, Jindong Wang, Xing Xie, Yue Zhang, Shikun Zhang
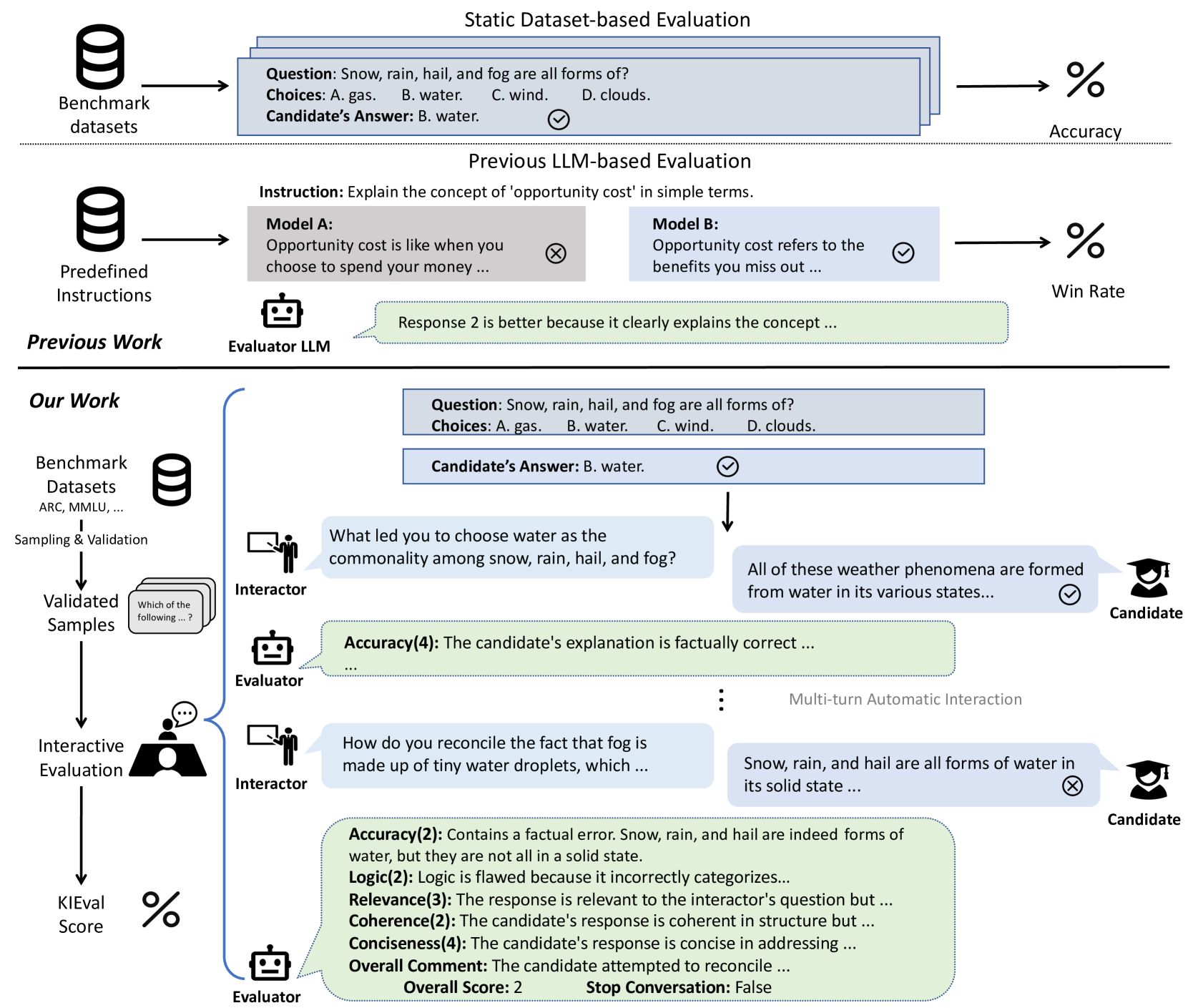
Automatic evaluation methods for large language models (LLMs) are hindered by data contamination, leading to inflated assessments of their effectiveness. Existing strategies, which aim to detect contaminated texts, focus on quantifying contamination status instead of accurately gauging model performance. In this paper, we introduce KIEval, a Knowledge-grounded Interactive Evaluation framework, which incorporates an LLM-powered interactor role for the first time to accomplish a dynamic contamination-resilient evaluation. Starting with a question in a conventional LLM benchmark involving domain-specific knowledge, KIEval utilizes dynamically generated, multi-round, and knowledge-focused dialogues to determine whether a model's response is merely a recall of benchmark answers or demonstrates a deep comprehension to apply knowledge in more complex conversations. Extensive experiments on seven leading LLMs across five datasets validate KIEval's effectiveness and generalization. We also reveal that data contamination brings no contribution or even negative effect to models' real-world applicability and understanding, and existing contamination detection methods for LLMs can only identify contamination in pre-training but not during supervised fine-tuning.
Read more6/4/2024

0
SciKnowEval: Evaluating Multi-level Scientific Knowledge of Large Language Models
Kehua Feng, Keyan Ding, Weijie Wang, Xiang Zhuang, Zeyuan Wang, Ming Qin, Yu Zhao, Jianhua Yao, Qiang Zhang, Huajun Chen
Large language models (LLMs) have gained increasing prominence in scientific research, but there is a lack of comprehensive benchmarks to fully evaluate their proficiency in understanding and mastering scientific knowledge. To address this need, we introduce the SciKnowEval benchmark, a novel framework that systematically evaluates LLMs across five progressive levels of scientific knowledge: studying extensively, inquiring earnestly, thinking profoundly, discerning clearly, and practicing assiduously. These levels aim to assess the breadth and depth of scientific knowledge in LLMs, including memory, comprehension, reasoning, discernment, and application. Specifically, we first construct a large-scale evaluation dataset encompassing 70K multi-level scientific problems and solutions in the domains of biology, chemistry, physics, and materials science. By leveraging this dataset, we benchmark 26 advanced open-source and proprietary LLMs using zero-shot and few-shot prompting strategies. The results reveal that despite the state-of-the-art performance of proprietary LLMs, there is still significant room for improvement, particularly in addressing scientific reasoning and applications. We anticipate that SciKnowEval will establish a standard for benchmarking LLMs in science research and promote the development of stronger scientific LLMs. The dataset and code are publicly available at https://scimind.ai/sciknoweval .
Read more9/24/2024
💬
0
CLEAN-EVAL: Clean Evaluation on Contaminated Large Language Models
Wenhong Zhu, Hongkun Hao, Zhiwei He, Yunze Song, Yumeng Zhang, Hanxu Hu, Yiran Wei, Rui Wang, Hongyuan Lu
We are currently in an era of fierce competition among various large language models (LLMs) continuously pushing the boundaries of benchmark performance. However, genuinely assessing the capabilities of these LLMs has become a challenging and critical issue due to potential data contamination, and it wastes dozens of time and effort for researchers and engineers to download and try those contaminated models. To save our precious time, we propose a novel and useful method, Clean-Eval, which mitigates the issue of data contamination and evaluates the LLMs in a cleaner manner. Clean-Eval employs an LLM to paraphrase and back-translate the contaminated data into a candidate set, generating expressions with the same meaning but in different surface forms. A semantic detector is then used to filter the generated low-quality samples to narrow down this candidate set. The best candidate is finally selected from this set based on the BLEURT score. According to human assessment, this best candidate is semantically similar to the original contamination data but expressed differently. All candidates can form a new benchmark to evaluate the model. Our experiments illustrate that Clean-Eval substantially restores the actual evaluation results on contaminated LLMs under both few-shot learning and fine-tuning scenarios.
Read more6/4/2024
0
Can I understand what I create? Self-Knowledge Evaluation of Large Language Models
Zhiquan Tan, Lai Wei, Jindong Wang, Xing Xie, Weiran Huang
Large language models (LLMs) have achieved remarkable progress in linguistic tasks, necessitating robust evaluation frameworks to understand their capabilities and limitations. Inspired by Feynman's principle of understanding through creation, we introduce a self-knowledge evaluation framework that is easy to implement, evaluating models on their ability to comprehend and respond to self-generated questions. Our findings, based on testing multiple models across diverse tasks, reveal significant gaps in the model's self-knowledge ability. Further analysis indicates these gaps may be due to misalignment with human attention mechanisms. Additionally, fine-tuning on self-generated math task may enhance the model's math performance, highlighting the potential of the framework for efficient and insightful model evaluation and may also contribute to the improvement of LLMs.
Read more6/11/2024