PFID: Privacy First Inference Delegation Framework for LLMs

0
Sign in to get full access
Overview
- This paper proposes PFID, a framework for delegating machine learning model inference to large language models (LLMs) while prioritizing user privacy.
- PFID uses a two-stage process to protect user data: first, the user's data is transformed to remove sensitive information, then the transformed data is used to query the LLM for inference.
- The framework aims to enable the benefits of LLMs while minimizing the risk of data leaks or misuse.
Plain English Explanation
The paper introduces PFID, a new system for using powerful AI language models (called LLMs) to make predictions and inferences, while still protecting the privacy of the users providing the data.
The key idea is to have a two-step process:
-
Data Transformation: First, the user's original data is transformed in a way that removes sensitive or identifying information. This "sanitized" data is what gets sent to the AI model.
-
Inference Delegation: The transformed data is then used to query the LLM and get the desired predictions or inferences. The LLM never sees the original user data, only the transformed version.
This approach allows users to take advantage of the impressive capabilities of large language models, without having to share their private information directly with the AI system. The goal is to enable the benefits of advanced AI while minimizing the risks of data breaches or misuse.
Technical Explanation
The PFID framework operates in two main stages:
-
Data Transformation: PFID first applies a series of techniques to transform the user's input data in a way that removes sensitive or identifying information. This includes techniques like feature selection, differential privacy, and homomorphic encryption. The transformed data is then used as the input for the next stage.
-
Inference Delegation: In this stage, the transformed data is used to query a large language model (LLM) to perform the desired inference task, such as text generation, classification, or question answering. The LLM never sees the original user data, only the transformed version. The LLM's responses are then returned to the user.
Key aspects of the PFID framework include:
- Two-Stage Architecture: The separation of data transformation and inference delegation is central to PFID's privacy-preserving approach.
- Adaptive Transformation: PFID dynamically adjusts the data transformation based on the specific inference task and LLM being used, to maximize utility while ensuring privacy.
- Verification and Auditing: PFID includes mechanisms to verify the integrity of the transformed data and audit the overall inference process.
Overall, PFID aims to unlock the power of large language models for a wide range of applications, while putting user privacy first and minimizing the risks of data misuse.
Critical Analysis
The PFID paper provides a comprehensive and well-designed framework for privacy-preserving inference delegation to large language models. The key strengths of the approach include:
- Strong Privacy Guarantees: The two-stage process of data transformation and inference delegation effectively isolates the user's private information from the LLM, providing robust privacy protections.
- Adaptive and Flexible: PFID's ability to dynamically adjust the data transformation based on the task and model allows for optimizing the balance between privacy and utility.
- Verification and Auditing: The inclusion of verification and auditing mechanisms is an important safeguard to ensure the integrity of the overall process.
However, some potential limitations and areas for further research include:
- Performance Impact: The additional computational overhead of the data transformation stage may impact the overall latency or throughput of the inference process, which could be a concern for some real-time applications.
- Attacks and Vulnerabilities: While the paper discusses some potential threats and countermeasures, a more comprehensive security analysis may be needed to ensure the framework is resilient to advanced attacks.
- Scalability and Deployment: The feasibility of deploying PFID in large-scale, production-ready systems with high availability and reliability requirements would be an important area for further exploration.
Overall, the PFID framework represents a significant advancement in the field of privacy-preserving machine learning and has the potential to enable widespread adoption of large language models while prioritizing user privacy.
Conclusion
The PFID framework proposed in this paper offers a promising approach to delegating inference tasks to powerful large language models while prioritizing user privacy. By separating the data transformation and inference stages, PFID is able to provide strong privacy guarantees without sacrificing the benefits of advanced AI capabilities.
The adaptive and flexible nature of PFID, along with its verification and auditing mechanisms, make it a compelling solution for a wide range of applications that require both the power of LLMs and the protection of sensitive user data. As the use of large language models continues to grow, frameworks like PFID will likely play a crucial role in enabling their widespread adoption while addressing critical privacy concerns.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PFID: Privacy First Inference Delegation Framework for LLMs
Haoyan Yang, Zhitao Li, Yong Zhang, Jianzong Wang, Ning Cheng, Ming Li, Jing Xiao
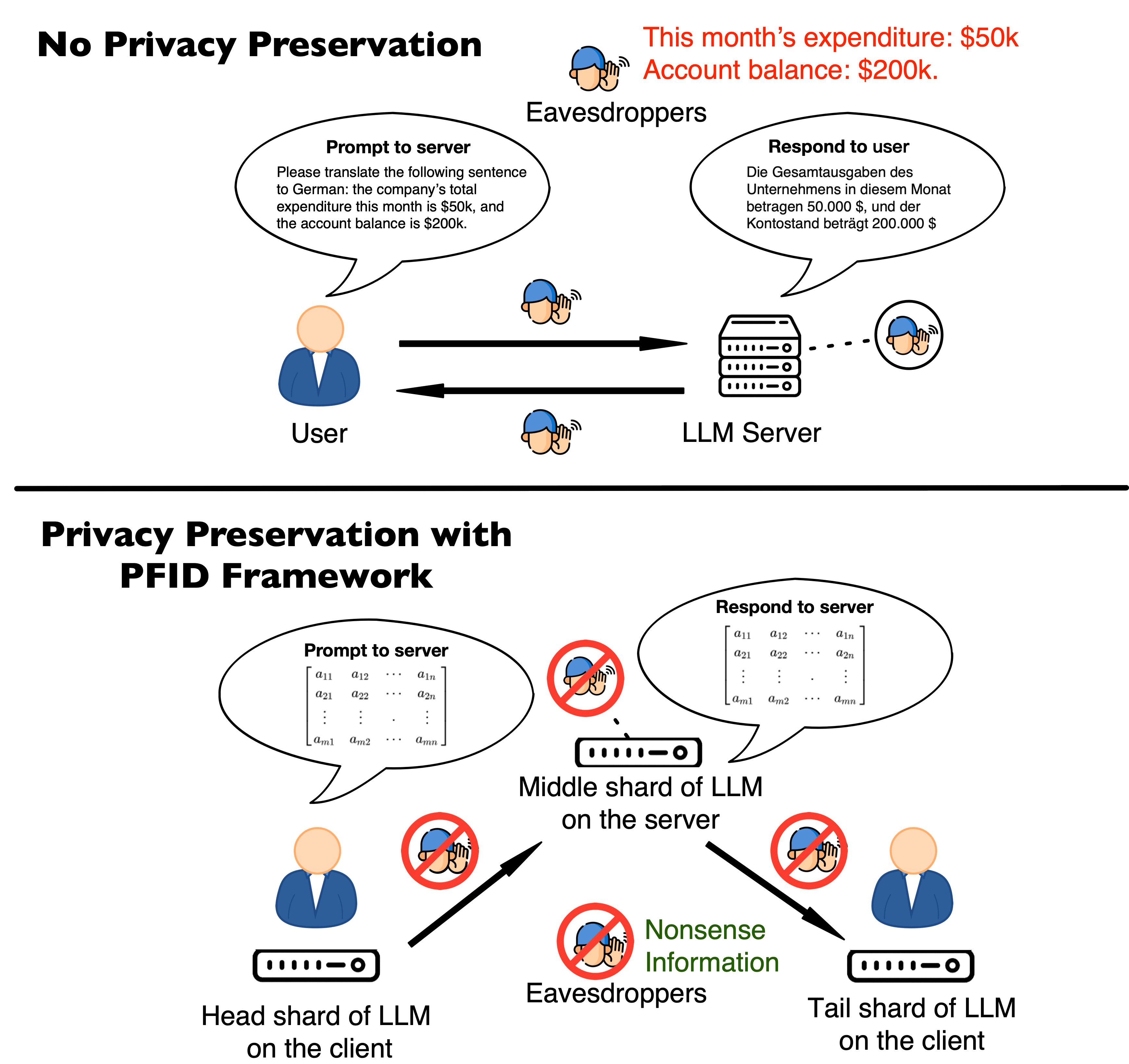
This paper introduces a novel privacy-preservation framework named PFID for LLMs that addresses critical privacy concerns by localizing user data through model sharding and singular value decomposition. When users are interacting with LLM systems, their prompts could be subject to being exposed to eavesdroppers within or outside LLM system providers who are interested in collecting users' input. In this work, we proposed a framework to camouflage user input, so as to alleviate privacy issues. Our framework proposes to place model shards on the client and the public server, we sent compressed hidden states instead of prompts to and from servers. Clients have held back information that can re-privatized the hidden states so that overall system performance is comparable to traditional LLMs services. Our framework was designed to be communication efficient, computation can be delegated to the local client so that the server's computation burden can be lightened. We conduct extensive experiments on machine translation tasks to verify our framework's performance.
Read more6/19/2024
📈
0
MH-pFLID: Model Heterogeneous personalized Federated Learning via Injection and Distillation for Medical Data Analysis
Luyuan Xie, Manqing Lin, Tianyu Luan, Cong Li, Yuejian Fang, Qingni Shen, Zhonghai Wu
Federated learning is widely used in medical applications for training global models without needing local data access. However, varying computational capabilities and network architectures (system heterogeneity), across clients pose significant challenges in effectively aggregating information from non-independently and identically distributed (non-IID) data. Current federated learning methods using knowledge distillation require public datasets, raising privacy and data collection issues. Additionally, these datasets require additional local computing and storage resources, which is a burden for medical institutions with limited hardware conditions. In this paper, we introduce a novel federated learning paradigm, named Model Heterogeneous personalized Federated Learning via Injection and Distillation (MH-pFLID). Our framework leverages a lightweight messenger model that carries concentrated information to collect the information from each client. We also develop a set of receiver and transmitter modules to receive and send information from the messenger model, so that the information could be injected and distilled with efficiency.
Read more5/14/2024
🧪
0
IPFed: Identity protected federated learning for user authentication
Yosuke Kaga, Yusei Suzuki, Kenta Takahashi
With the development of laws and regulations related to privacy preservation, it has become difficult to collect personal data to perform machine learning. In this context, federated learning, which is distributed learning without sharing personal data, has been proposed. In this paper, we focus on federated learning for user authentication. We show that it is difficult to achieve both privacy preservation and high accuracy with existing methods. To address these challenges, we propose IPFed which is privacy-preserving federated learning using random projection for class embedding. Furthermore, we prove that IPFed is capable of learning equivalent to the state-of-the-art method. Experiments on face image datasets show that IPFed can protect the privacy of personal data while maintaining the accuracy of the state-of-the-art method.
Read more5/8/2024

0
PDSS: A Privacy-Preserving Framework for Step-by-Step Distillation of Large Language Models
Tao Fan, Yan Kang, Weijing Chen, Hanlin Gu, Yuanfeng Song, Lixin Fan, Kai Chen, Qiang Yang
In the context of real-world applications, leveraging large language models (LLMs) for domain-specific tasks often faces two major challenges: domain-specific knowledge privacy and constrained resources. To address these issues, we propose PDSS, a privacy-preserving framework for step-by-step distillation of LLMs. PDSS works on a server-client architecture, wherein client transmits perturbed prompts to the server's LLM for rationale generation. The generated rationales are then decoded by the client and used to enrich the training of task-specific small language model(SLM) within a multi-task learning paradigm. PDSS introduces two privacy protection strategies: the Exponential Mechanism Strategy and the Encoder-Decoder Strategy, balancing prompt privacy and rationale usability. Experiments demonstrate the effectiveness of PDSS in various text generation tasks, enabling the training of task-specific SLM with enhanced performance while prioritizing data privacy protection.
Read more6/19/2024