PDSS: A Privacy-Preserving Framework for Step-by-Step Distillation of Large Language Models

0

Sign in to get full access
Overview
• This paper introduces PDSS, a privacy-preserving framework for step-by-step distillation of large language models.
Plain English Explanation
PDSS is a new method that allows researchers and companies to train smaller, more efficient language models from larger, more powerful models while protecting the privacy of the data used to train the larger model. This is important because the training data for large language models can contain sensitive personal information that needs to be protected.
The key idea behind PDSS is to train the smaller model in a step-by-step fashion, gradually distilling the knowledge from the larger model without ever exposing the full training data. At each step, only a limited amount of information is shared, and differential privacy techniques are used to further protect the privacy of the training data.
This approach has several benefits. It allows organizations to leverage the capabilities of large language models without compromising the privacy of their users. It also enables the creation of specialized, task-oriented models that are more efficient and affordable to deploy than the original large models. Overall, PDSS represents an important advance in the field of privacy-preserving machine learning.
Technical Explanation
The PDSS framework works by breaking down the distillation process into a series of smaller, iterative steps. At each step, the student model (the smaller model being trained) only receives a limited amount of information from the teacher model (the larger, original model). This information is carefully filtered and perturbed using differential privacy techniques to prevent the disclosure of sensitive training data.
The authors describe two key components of PDSS: a differential privacy-based knowledge distillation algorithm and a preference-based large language model distillation method. These techniques work together to gradually transfer knowledge from the teacher to the student model while preserving privacy.
The paper also discusses how PDSS can be combined with other privacy-preserving methods, such as differentially private next-token prediction and split-and-denoise techniques, to further enhance privacy protections.
Critical Analysis
The PDSS framework represents a promising approach to privacy-preserving model distillation. By breaking down the distillation process into smaller, iterative steps and applying differential privacy techniques, the authors have addressed a critical challenge in the field of large language model deployment.
However, the paper does not provide a detailed analysis of the computational and storage overhead associated with the PDSS approach. Implementing the various privacy-preserving techniques may incur significant performance costs, which could limit the practical applicability of the framework.
Additionally, the authors acknowledge that their approach may not be suitable for all use cases, as the step-by-step distillation process could lead to suboptimal model performance compared to a direct distillation from the original large model. Further research is needed to explore the trade-offs between privacy, efficiency, and model quality in the context of PDSS.
Conclusion
The PDSS framework represents an important step towards enabling the widespread deployment of large language models while preserving the privacy of the underlying training data. By combining differential privacy techniques with a step-by-step distillation process, the authors have developed a novel approach that balances the need for powerful language models with the imperative of protecting user privacy.
As the field of large language models continues to evolve, frameworks like PDSS will become increasingly crucial in ensuring that the benefits of these technologies can be realized without compromising fundamental rights and ethical principles. Further research and real-world applications of PDSS will be crucial in evaluating its practical impact and driving the development of more privacy-preserving AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PDSS: A Privacy-Preserving Framework for Step-by-Step Distillation of Large Language Models
Tao Fan, Yan Kang, Weijing Chen, Hanlin Gu, Yuanfeng Song, Lixin Fan, Kai Chen, Qiang Yang
In the context of real-world applications, leveraging large language models (LLMs) for domain-specific tasks often faces two major challenges: domain-specific knowledge privacy and constrained resources. To address these issues, we propose PDSS, a privacy-preserving framework for step-by-step distillation of LLMs. PDSS works on a server-client architecture, wherein client transmits perturbed prompts to the server's LLM for rationale generation. The generated rationales are then decoded by the client and used to enrich the training of task-specific small language model(SLM) within a multi-task learning paradigm. PDSS introduces two privacy protection strategies: the Exponential Mechanism Strategy and the Encoder-Decoder Strategy, balancing prompt privacy and rationale usability. Experiments demonstrate the effectiveness of PDSS in various text generation tasks, enabling the training of task-specific SLM with enhanced performance while prioritizing data privacy protection.
Read more6/19/2024
0
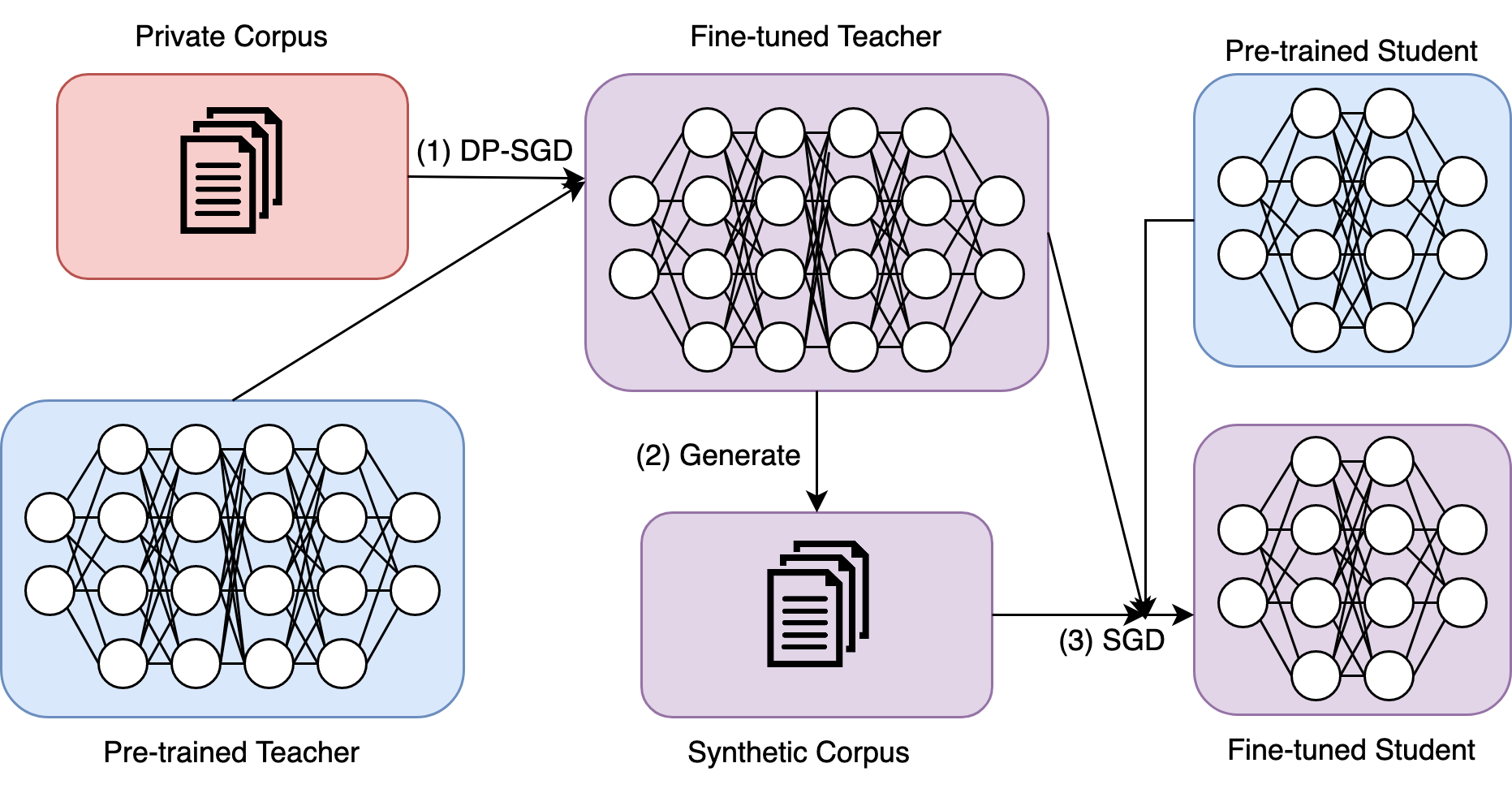
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
Read more6/6/2024

0
Differentially Private Next-Token Prediction of Large Language Models
James Flemings, Meisam Razaviyayn, Murali Annavaram
Ensuring the privacy of Large Language Models (LLMs) is becoming increasingly important. The most widely adopted technique to accomplish this is DP-SGD, which trains a model to guarantee Differential Privacy (DP). However, DP-SGD overestimates an adversary's capabilities in having white box access to the model and, as a result, causes longer training times and larger memory usage than SGD. On the other hand, commercial LLM deployments are predominantly cloud-based; hence, adversarial access to LLMs is black-box. Motivated by these observations, we present Private Mixing of Ensemble Distributions (PMixED): a private prediction protocol for next-token prediction that utilizes the inherent stochasticity of next-token sampling and a public model to achieve Differential Privacy. We formalize this by introducing RD-mollifers which project each of the model's output distribution from an ensemble of fine-tuned LLMs onto a set around a public LLM's output distribution, then average the projected distributions and sample from it. Unlike DP-SGD which needs to consider the model architecture during training, PMixED is model agnostic, which makes PMixED a very appealing solution for current deployments. Our results show that PMixED achieves a stronger privacy guarantee than sample-level privacy and outperforms DP-SGD for privacy $epsilon = 8$ on large-scale datasets. Thus, PMixED offers a practical alternative to DP training methods for achieving strong generative utility without compromising privacy.
Read more4/30/2024

0
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Rongzhi Zhang, Jiaming Shen, Tianqi Liu, Haorui Wang, Zhen Qin, Feng Han, Jialu Liu, Simon Baumgartner, Michael Bendersky, Chao Zhang
Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
Read more6/7/2024