PhilHumans: Benchmarking Machine Learning for Personal Health
2405.02770
0
0
👀
Abstract
The use of machine learning in Healthcare has the potential to improve patient outcomes as well as broaden the reach and affordability of Healthcare. The history of other application areas indicates that strong benchmarks are essential for the development of intelligent systems. We present Personal Health Interfaces Leveraging HUman-MAchine Natural interactions (PhilHumans), a holistic suite of benchmarks for machine learning across different Healthcare settings - talk therapy, diet coaching, emergency care, intensive care, obstetric sonography - as well as different learning settings, such as action anticipation, timeseries modeling, insight mining, language modeling, computer vision, reinforcement learning and program synthesis
Create account to get full access
Overview
- The paper presents a new benchmark called "PhilHumans" for evaluating machine learning models in various healthcare settings
- The benchmark covers different areas such as talk therapy, diet coaching, emergency care, intensive care, and obstetric sonography
- It also includes different learning tasks like action anticipation, time series modeling, insight mining, language modeling, computer vision, reinforcement learning, and program synthesis
Plain English Explanation
The paper discusses how machine learning in healthcare has the potential to improve patient outcomes and make healthcare more accessible and affordable. To help advance this field, the researchers have created a new benchmark called "PhilHumans" that evaluates machine learning models in various healthcare scenarios.
The benchmark covers a wide range of healthcare applications, from talk therapy and diet coaching to emergency care, intensive care, and obstetric sonography. It also includes different types of machine learning tasks, such as anticipating actions, modeling time series data, extracting insights, generating language, and even synthesizing programs.
The goal of this benchmark is to create a comprehensive set of standardized tests that can help researchers and developers build more effective and capable machine learning models for healthcare. By having a common set of benchmarks, the field can progress more rapidly and ensure that the models being developed are truly meeting the needs of healthcare providers and patients.
Technical Explanation
The paper presents "PhilHumans," a new suite of benchmarks for evaluating machine learning models in various healthcare settings. The benchmark covers a diverse set of applications, including talk therapy, diet coaching, emergency care, intensive care, and obstetric sonography. It also includes a range of learning tasks such as action anticipation, time series modeling, insight mining, language modeling, computer vision, reinforcement learning, and program synthesis.
The goal of this benchmark is to provide a comprehensive and standardized way to assess the performance of machine learning models in healthcare. By having a common set of benchmarks, the researchers aim to accelerate the development of intelligent systems that can truly improve patient outcomes and make healthcare more accessible and affordable.
The paper highlights the importance of strong benchmarks in driving the progress of intelligent systems, drawing insights from the history of other application areas. The researchers argue that the development of PhilHumans can serve as a crucial step towards realizing the full potential of machine learning in healthcare.
Critical Analysis
The paper presents a compelling case for the need for a comprehensive benchmark suite like PhilHumans to advance the field of machine learning in healthcare. By covering a wide range of healthcare applications and learning tasks, the benchmark has the potential to provide a more holistic assessment of model capabilities and performance.
However, the paper does not provide detailed information about the specific benchmark tasks, datasets, and evaluation metrics used in the PhilHumans suite. This makes it challenging to assess the rigor and comprehensiveness of the benchmark itself. Further information on the benchmark design and validation process would be helpful for readers to better understand the strengths and limitations of the proposed framework.
Additionally, the paper does not discuss potential biases or ethical considerations that might arise from the use of machine learning models in healthcare. As these models become more integrated into healthcare decision-making, it will be crucial to address issues of fairness, transparency, and accountability to ensure that they do not exacerbate existing disparities or introduce new ethical concerns.
Overall, the PhilHumans benchmark is a promising step towards improving the development and evaluation of machine learning models for healthcare applications. However, the research community would benefit from more detailed information about the benchmark and a deeper consideration of the ethical implications of deploying these technologies in sensitive healthcare contexts.
Conclusion
The paper presents a new benchmark called "PhilHumans" that aims to accelerate the development of machine learning models for a wide range of healthcare applications. By providing a comprehensive suite of standardized tests covering diverse healthcare scenarios and learning tasks, the researchers hope to drive progress in the field and ensure that the models being developed are truly meeting the needs of healthcare providers and patients.
The development of robust benchmarks like PhilHumans is a crucial step towards realizing the full potential of machine learning in healthcare, which has the promise of improving patient outcomes and expanding the reach and affordability of healthcare services. As this technology continues to advance, it will be important to address the ethical considerations and potential biases that may arise to ensure that these models are developed and deployed responsibly and equitably.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
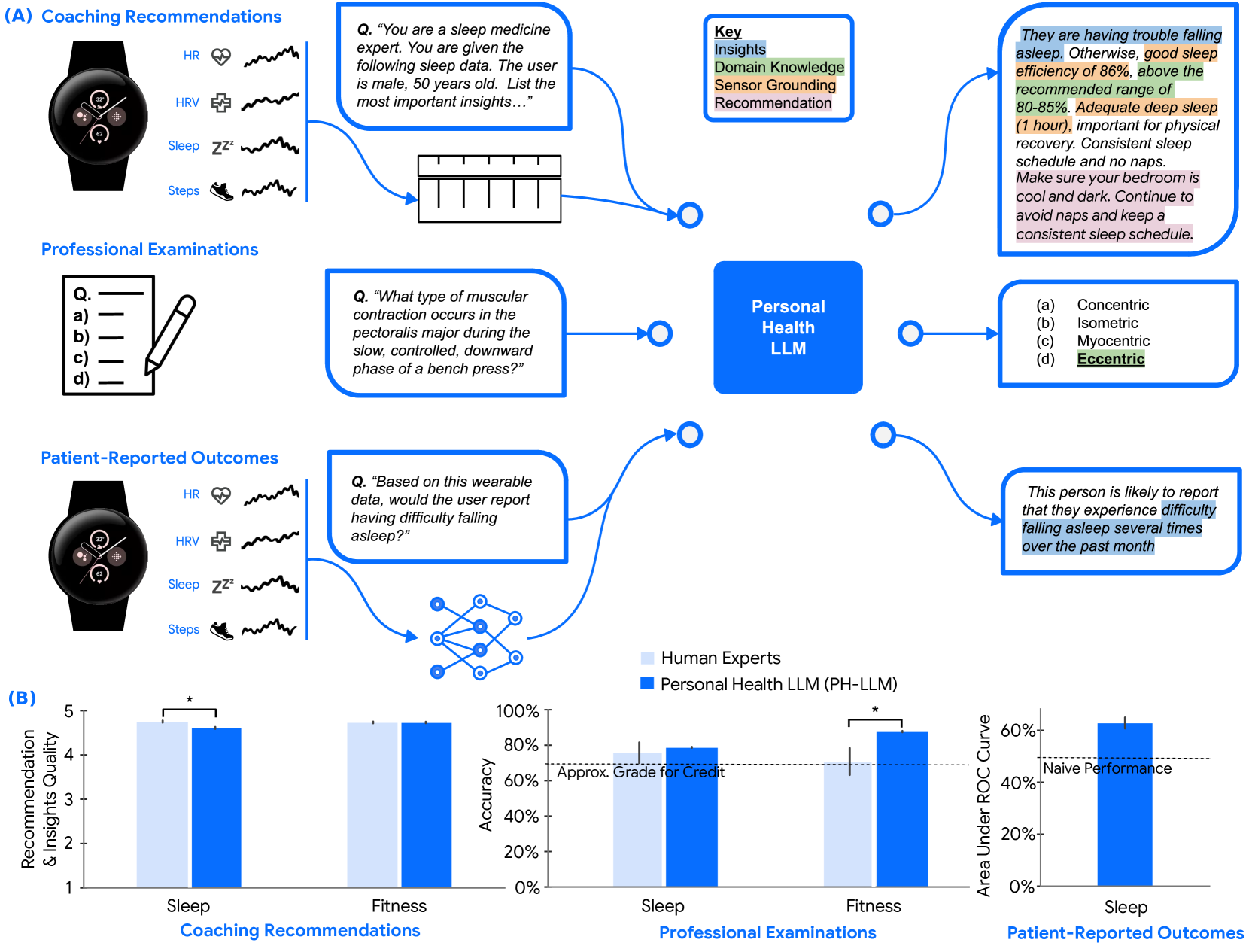
Towards a Personal Health Large Language Model
Justin Cosentino, Anastasiya Belyaeva, Xin Liu, Nicholas A. Furlotte, Zhun Yang, Chace Lee, Erik Schenck, Yojan Patel, Jian Cui, Logan Douglas Schneider, Robby Bryant, Ryan G. Gomes, Allen Jiang, Roy Lee, Yun Liu, Javier Perez, Jameson K. Rogers, Cathy Speed, Shyam Tailor, Megan Walker, Jeffrey Yu, Tim Althoff, Conor Heneghan, John Hernandez, Mark Malhotra, Leor Stern, Yossi Matias, Greg S. Corrado, Shwetak Patel, Shravya Shetty, Jiening Zhan, Shruthi Prabhakara, Daniel McDuff, Cory Y. McLean
0
0
In health, most large language model (LLM) research has focused on clinical tasks. However, mobile and wearable devices, which are rarely integrated into such tasks, provide rich, longitudinal data for personal health monitoring. Here we present Personal Health Large Language Model (PH-LLM), fine-tuned from Gemini for understanding and reasoning over numerical time-series personal health data. We created and curated three datasets that test 1) production of personalized insights and recommendations from sleep patterns, physical activity, and physiological responses, 2) expert domain knowledge, and 3) prediction of self-reported sleep outcomes. For the first task we designed 857 case studies in collaboration with domain experts to assess real-world scenarios in sleep and fitness. Through comprehensive evaluation of domain-specific rubrics, we observed that Gemini Ultra 1.0 and PH-LLM are not statistically different from expert performance in fitness and, while experts remain superior for sleep, fine-tuning PH-LLM provided significant improvements in using relevant domain knowledge and personalizing information for sleep insights. We evaluated PH-LLM domain knowledge using multiple choice sleep medicine and fitness examinations. PH-LLM achieved 79% on sleep and 88% on fitness, exceeding average scores from a sample of human experts. Finally, we trained PH-LLM to predict self-reported sleep quality outcomes from textual and multimodal encoding representations of wearable data, and demonstrate that multimodal encoding is required to match performance of specialized discriminative models. Although further development and evaluation are necessary in the safety-critical personal health domain, these results demonstrate both the broad knowledge and capabilities of Gemini models and the benefit of contextualizing physiological data for personal health applications as done with PH-LLM.
6/11/2024
Leveraging Large Language Models for Patient Engagement: The Power of Conversational AI in Digital Health
Bo Wen, Raquel Norel, Julia Liu, Thaddeus Stappenbeck, Farhana Zulkernine, Huamin Chen
0
0
The rapid advancements in large language models (LLMs) have opened up new opportunities for transforming patient engagement in healthcare through conversational AI. This paper presents an overview of the current landscape of LLMs in healthcare, specifically focusing on their applications in analyzing and generating conversations for improved patient engagement. We showcase the power of LLMs in handling unstructured conversational data through four case studies: (1) analyzing mental health discussions on Reddit, (2) developing a personalized chatbot for cognitive engagement in seniors, (3) summarizing medical conversation datasets, and (4) designing an AI-powered patient engagement system. These case studies demonstrate how LLMs can effectively extract insights and summarizations from unstructured dialogues and engage patients in guided, goal-oriented conversations. Leveraging LLMs for conversational analysis and generation opens new doors for many patient-centered outcomes research opportunities. However, integrating LLMs into healthcare raises important ethical considerations regarding data privacy, bias, transparency, and regulatory compliance. We discuss best practices and guidelines for the responsible development and deployment of LLMs in healthcare settings. Realizing the full potential of LLMs in digital health will require close collaboration between the AI and healthcare professionals communities to address technical challenges and ensure these powerful tools' safety, efficacy, and equity.
6/21/2024
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
6/27/2024
📈
A Dynamic Model of Performative Human-ML Collaboration: Theory and Empirical Evidence
Tom Suhr, Samira Samadi, Chiara Farronato
0
0
Machine learning (ML) models are increasingly used in various applications, from recommendation systems in e-commerce to diagnosis prediction in healthcare. In this paper, we present a novel dynamic framework for thinking about the deployment of ML models in a performative, human-ML collaborative system. In our framework, the introduction of ML recommendations changes the data generating process of human decisions, which are only a proxy to the ground truth and which are then used to train future versions of the model. We show that this dynamic process in principle can converge to different stable points, i.e. where the ML model and the Human+ML system have the same performance. Some of these stable points are suboptimal with respect to the actual ground truth. We conduct an empirical user study with 1,408 participants to showcase this process. In the study, humans solve instances of the knapsack problem with the help of machine learning predictions. This is an ideal setting because we can see how ML models learn to imitate human decisions and how this learning process converges to a stable point. We find that for many levels of ML performance, humans can improve the ML predictions to dynamically reach an equilibrium performance that is around 92% of the maximum knapsack value. We also find that the equilibrium performance could be even higher if humans rationally followed the ML recommendations. Finally, we test whether monetary incentives can increase the quality of human decisions, but we fail to find any positive effect. Our results have practical implications for the deployment of ML models in contexts where human decisions may deviate from the indisputable ground truth.
6/7/2024