Physics-based Scene Layout Generation from Human Motion
2405.12460
0
0
🛸
Abstract
Creating scenes for captured motions that achieve realistic human-scene interaction is crucial for 3D animation in movies or video games. As character motion is often captured in a blue-screened studio without real furniture or objects in place, there may be a discrepancy between the planned motion and the captured one. This gives rise to the need for automatic scene layout generation to relieve the burdens of selecting and positioning furniture and objects. Previous approaches cannot avoid artifacts like penetration and floating due to the lack of physical constraints. Furthermore, some heavily rely on specific data to learn the contact affordances, restricting the generalization ability to different motions. In this work, we present a physics-based approach that simultaneously optimizes a scene layout generator and simulates a moving human in a physics simulator. To attain plausible and realistic interaction motions, our method explicitly introduces physical constraints. To automatically recover and generate the scene layout, we minimize the motion tracking errors to identify the objects that can afford interaction. We use reinforcement learning to perform a dual-optimization of both the character motion imitation controller and the scene layout generator. To facilitate the optimization, we reshape the tracking rewards and devise pose prior guidance obtained from our estimated pseudo-contact labels. We evaluate our method using motions from SAMP and PROX, and demonstrate physically plausible scene layout reconstruction compared with the previous kinematics-based method.
Create account to get full access
Overview
- Creating realistic human-scene interaction is crucial for 3D animation in movies and video games
- Character motion is often captured in a studio without real furniture or objects, leading to a mismatch between the planned and captured motion
- Automatic scene layout generation can help relieve the burdens of selecting and positioning furniture and objects
- Previous approaches have struggled with artifacts like penetration and floating due to lack of physical constraints
- Some heavily rely on specific data, limiting their ability to generalize to different motions
Plain English Explanation
When creating 3D animations for movies or video games, it's important that the characters interact with their environment in a realistic way. However, character motion is often captured in a studio without any actual furniture or objects present. This can lead to a mismatch between the planned motion and the captured one, as the character may not be interacting with the virtual objects as intended.
To address this issue, researchers have explored automatic scene layout generation to help select and position the necessary furniture and objects. However, previous approaches have struggled to create scenes that truly feel realistic, as they couldn't account for the physical constraints of the environment. Some methods also relied heavily on specific data, which limited their ability to work with different types of character motions.
In this work, the researchers present a new, physics-based approach that tries to solve these problems. By simulating the character's motion in a physics-based environment and optimizing the scene layout at the same time, their method can create scenes that facilitate realistic human-object interaction. The key is explicitly incorporating physical constraints into the optimization process, which helps avoid unrealistic artifacts like objects floating or passing through each other.
Technical Explanation
The researchers propose a physics-based approach that simultaneously optimizes a scene layout generator and simulates a moving human character within a physics simulator. To achieve plausible and realistic interaction motions, their method explicitly introduces physical constraints.
To automatically recover and generate the scene layout, the researchers minimize the motion tracking errors to identify the objects that can afford interaction. They use reinforcement learning to perform a dual-optimization of both the character motion imitation controller and the scene layout generator.
To facilitate the optimization, the researchers reshape the tracking rewards and devise pose prior guidance obtained from their estimated pseudo-contact labels. They evaluate their method using motions from the SAMP and PROX datasets, and demonstrate physically plausible scene layout reconstruction compared to previous kinematics-based methods.
Critical Analysis
The researchers acknowledge that their approach still has some limitations. For example, they note that their method may struggle with complex interactions or scenarios where the character needs to adapt to unexpected changes in the environment. Additionally, the reliance on reinforcement learning could make the optimization process computationally intensive and potentially unstable.
Furthermore, the paper does not provide a comprehensive evaluation of the method's generalization capabilities. It would be valuable to see how well the approach performs with a wider range of character motions and scene types, beyond the specific datasets used in the experiments.
Overall, the researchers present an interesting and promising approach to the problem of generating realistic human-scene interactions. By explicitly incorporating physical constraints and using a dual-optimization strategy, they have made progress in addressing some of the shortcomings of previous methods. However, further research and evaluation will be needed to fully understand the strengths and limitations of this approach.
Conclusion
This paper presents a novel, physics-based approach to generating realistic human-scene interactions for 3D animation. By simultaneously optimizing a scene layout generator and simulating a moving human character in a physics-based environment, the researchers are able to create scenes that facilitate plausible and realistic interactions.
The key innovations of this work are the explicit incorporation of physical constraints and the use of reinforcement learning to perform a dual-optimization of both the character motion imitation and the scene layout generation. This helps to address the limitations of previous methods, which struggled with artifacts like penetration and floating due to the lack of physical considerations.
While the approach shows promise, there are still some areas for further research and improvement, such as expanding the method's generalization capabilities and addressing the computational challenges of the reinforcement learning-based optimization. Nevertheless, this work represents an important step forward in the field of 3D animation and interactive virtual environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
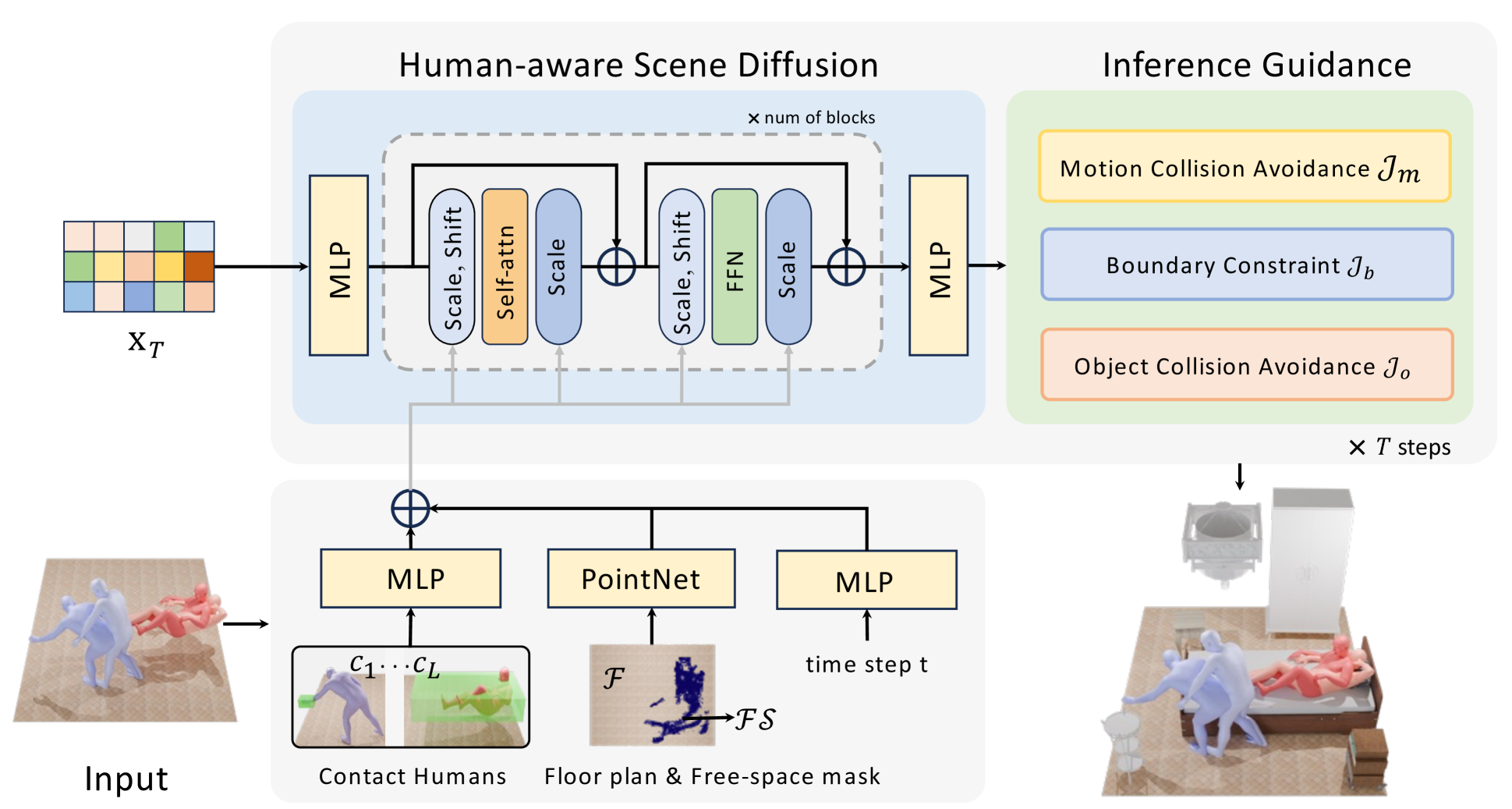
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Xiaolin Hong, Hongwei Yi, Fazhi He, Qiong Cao
0
0
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
6/27/2024
⚙️
Generating Human Motion in 3D Scenes from Text Descriptions
Zhi Cen, Huaijin Pi, Sida Peng, Zehong Shen, Minghui Yang, Shuai Zhu, Hujun Bao, Xiaowei Zhou
0
0
Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
5/14/2024

PhyScene: Physically Interactable 3D Scene Synthesis for Embodied AI
Yandan Yang, Baoxiong Jia, Peiyuan Zhi, Siyuan Huang
0
0
With recent developments in Embodied Artificial Intelligence (EAI) research, there has been a growing demand for high-quality, large-scale interactive scene generation. While prior methods in scene synthesis have prioritized the naturalness and realism of the generated scenes, the physical plausibility and interactivity of scenes have been largely left unexplored. To address this disparity, we introduce PhyScene, a novel method dedicated to generating interactive 3D scenes characterized by realistic layouts, articulated objects, and rich physical interactivity tailored for embodied agents. Based on a conditional diffusion model for capturing scene layouts, we devise novel physics- and interactivity-based guidance mechanisms that integrate constraints from object collision, room layout, and object reachability. Through extensive experiments, we demonstrate that PhyScene effectively leverages these guidance functions for physically interactable scene synthesis, outperforming existing state-of-the-art scene synthesis methods by a large margin. Our findings suggest that the scenes generated by PhyScene hold considerable potential for facilitating diverse skill acquisition among agents within interactive environments, thereby catalyzing further advancements in embodied AI research. Project website: http://physcene.github.io.
4/16/2024
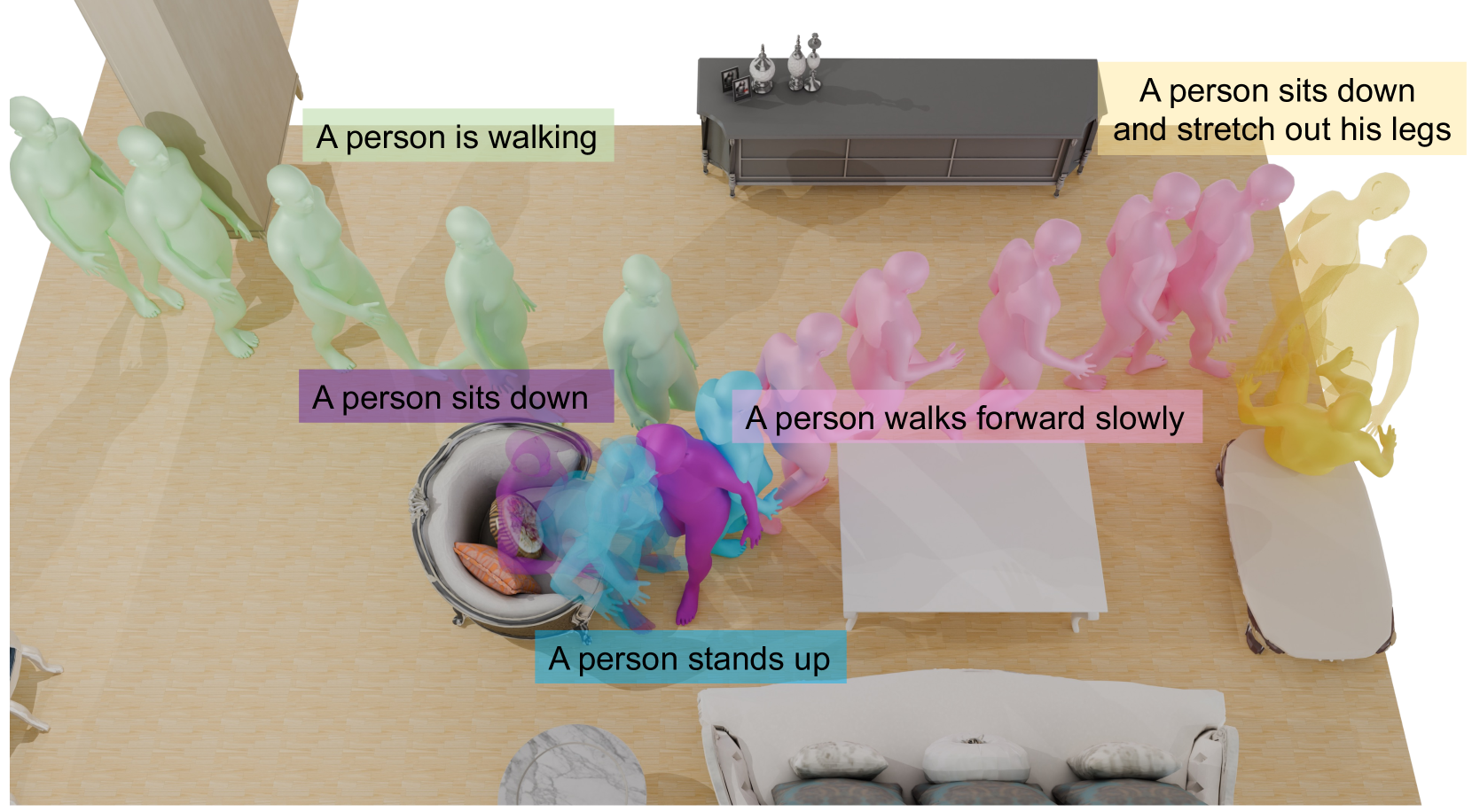
Generating Human Interaction Motions in Scenes with Text Control
Hongwei Yi, Justus Thies, Michael J. Black, Xue Bin Peng, Davis Rempe
0
0
We present TeSMo, a method for text-controlled scene-aware motion generation based on denoising diffusion models. Previous text-to-motion methods focus on characters in isolation without considering scenes due to the limited availability of datasets that include motion, text descriptions, and interactive scenes. Our approach begins with pre-training a scene-agnostic text-to-motion diffusion model, emphasizing goal-reaching constraints on large-scale motion-capture datasets. We then enhance this model with a scene-aware component, fine-tuned using data augmented with detailed scene information, including ground plane and object shapes. To facilitate training, we embed annotated navigation and interaction motions within scenes. The proposed method produces realistic and diverse human-object interactions, such as navigation and sitting, in different scenes with various object shapes, orientations, initial body positions, and poses. Extensive experiments demonstrate that our approach surpasses prior techniques in terms of the plausibility of human-scene interactions, as well as the realism and variety of the generated motions. Code will be released upon publication of this work at https://research.nvidia.com/labs/toronto-ai/tesmo.
4/17/2024