PianoMime: Learning a Generalist, Dexterous Piano Player from Internet Demonstrations

0

Sign in to get full access
Overview
- The paper describes PianoMime, a system that learns to play the piano by imitating demonstrations from the internet.
- PianoMime is a "generalist, dexterous piano player" that can learn a wide range of piano playing skills from diverse online demonstrations.
- The system leverages large-scale internet data to learn a comprehensive piano playing capability, going beyond narrow, specialized models.
Plain English Explanation
The paper presents PianoMime, a system that learns to play the piano by watching and imitating demonstration videos from the internet. Unlike narrow, specialized piano-playing models, PianoMime aims to become a "generalist, dexterous piano player" - a system that can learn a broad range of piano skills from diverse online examples.
By learning from a large corpus of internet data, PianoMime develops a comprehensive piano playing capability, going beyond what could be achieved from a limited set of training examples. The key idea is to leverage the wealth of piano playing demonstrations available online to teach the system a wide variety of techniques and skills.
Rather than being trained on a specific dataset or task, PianoMime learns in a more open-ended way, observing and imitating the diverse range of piano playing behaviors exhibited in internet videos. This allows the system to acquire a generalist set of piano playing abilities that can be applied flexibly to new pieces and scenarios.
Technical Explanation
The PianoMime system uses a transformer-based architecture to learn a generalist piano playing model from internet video demonstrations. The model takes as input a sequence of video frames showing piano playing, and outputs the corresponding sequence of piano key presses.
The core architecture consists of a visual encoder that processes the video frames, and a piano action decoder that predicts the piano key presses. These components are trained end-to-end on a large dataset of internet piano demonstration videos.
To handle the diversity of internet data, PianoMime employs several techniques such as data augmentation, domain-adaptive pretraining, and task-agnostic fine-tuning. This allows the model to learn robust, generalizable piano playing skills from the noisy, heterogeneous online examples.
The experiments demonstrate that PianoMime can effectively imitate a wide range of piano playing behaviors from internet data, outperforming specialized models trained on limited datasets. This highlights the power of leveraging large-scale online demonstrations to acquire versatile, real-world skills.
Critical Analysis
The paper provides a compelling proof-of-concept for the PianoMime system, showing how it can learn generalist piano playing abilities from internet data. However, the authors acknowledge several limitations and areas for further research.
One notable caveat is that the system's performance is still limited compared to human piano experts, especially for challenging musical passages. The authors suggest that further advances in areas like multimodal perception and fine-grained motor control may be needed to fully match human-level piano playing.
Additionally, the paper does not address potential issues around the quality and reliability of internet data, which could introduce biases or artifacts into the learned piano playing model. Careful curation and validation of the training data may be an important area for improvement.
While the PianoMime system demonstrates impressive generalization, there may also be opportunities to combine it with more targeted, specialized training to further enhance its piano playing capabilities. Exploring hybrid approaches could be a fruitful direction for future research.
Conclusion
The PianoMime paper presents an innovative approach to learning piano playing skills by imitating a diverse corpus of internet demonstrations. By leveraging large-scale online data, the system acquires a generalist, dexterous piano playing capability that goes beyond narrow, specialized models.
This work highlights the potential of using internet data to train versatile real-world skills, beyond the constraints of curated datasets. As the authors note, further advancements in areas like multimodal perception and fine motor control could help PianoMime and similar systems reach human-level piano playing proficiency.
Overall, the PianoMime research represents an exciting step towards developing flexible, general-purpose AI systems that can learn complex real-world skills by observing and imitating human demonstrations at scale.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PianoMime: Learning a Generalist, Dexterous Piano Player from Internet Demonstrations
Cheng Qian, Julen Urain, Kevin Zakka, Jan Peters
In this work, we introduce PianoMime, a framework for training a piano-playing agent using internet demonstrations. The internet is a promising source of large-scale demonstrations for training our robot agents. In particular, for the case of piano-playing, Youtube is full of videos of professional pianists playing a wide myriad of songs. In our work, we leverage these demonstrations to learn a generalist piano-playing agent capable of playing any arbitrary song. Our framework is divided into three parts: a data preparation phase to extract the informative features from the Youtube videos, a policy learning phase to train song-specific expert policies from the demonstrations and a policy distillation phase to distil the policies into a single generalist agent. We explore different policy designs to represent the agent and evaluate the influence of the amount of training data on the generalization capability of the agent to novel songs not available in the dataset. We show that we are able to learn a policy with up to 56% F1 score on unseen songs.
Read more7/26/2024
0
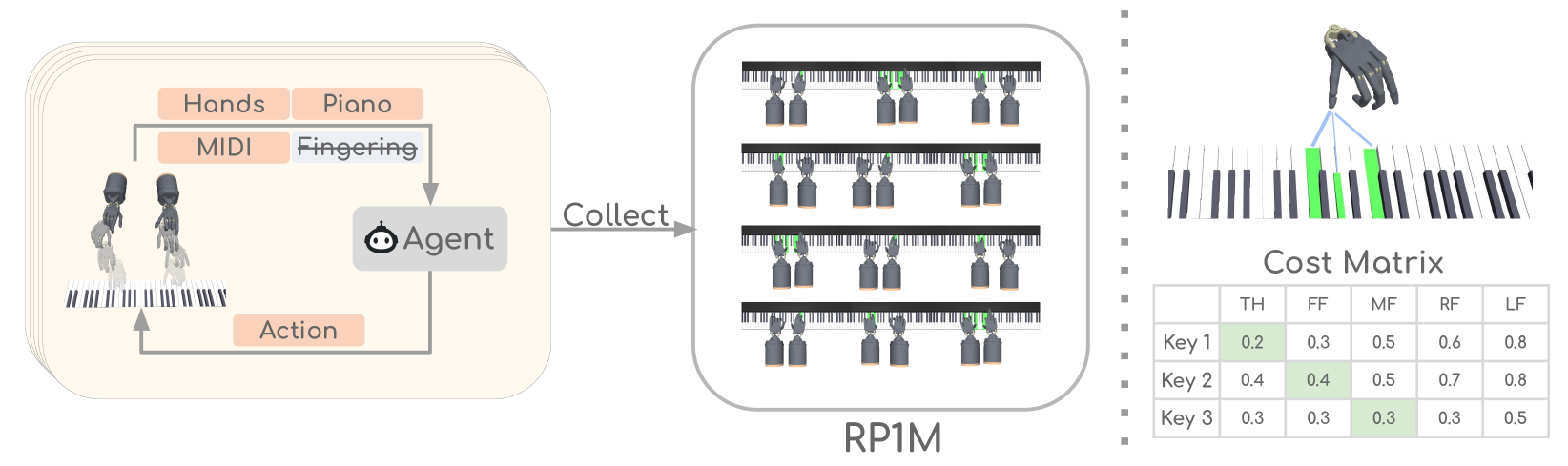
RP1M: A Large-Scale Motion Dataset for Piano Playing with Bi-Manual Dexterous Robot Hands
Yi Zhao, Le Chen, Jan Schneider, Quankai Gao, Juho Kannala, Bernhard Scholkopf, Joni Pajarinen, Dieter Buchler
It has been a long-standing research goal to endow robot hands with human-level dexterity. Bi-manual robot piano playing constitutes a task that combines challenges from dynamic tasks, such as generating fast while precise motions, with slower but contact-rich manipulation problems. Although reinforcement learning based approaches have shown promising results in single-task performance, these methods struggle in a multi-song setting. Our work aims to close this gap and, thereby, enable imitation learning approaches for robot piano playing at scale. To this end, we introduce the Robot Piano 1 Million (RP1M) dataset, containing bi-manual robot piano playing motion data of more than one million trajectories. We formulate finger placements as an optimal transport problem, thus, enabling automatic annotation of vast amounts of unlabeled songs. Benchmarking existing imitation learning approaches shows that such approaches reach state-of-the-art robot piano playing performance by leveraging RP1M.
Read more8/21/2024

0
Generating Piano Practice Policy with a Gaussian Process
Alexandra Moringen, Elad Vromen, Helge Ritter, Jason Friedman
A typical process of learning to play a piece on a piano consists of a progression through a series of practice units that focus on individual dimensions of the skill, the so-called practice modes. Practice modes in learning to play music comprise a particularly large set of possibilities, such as hand coordination, posture, articulation, ability to read a music score, correct timing or pitch, etc. Self-guided practice is known to be suboptimal, and a model that schedules optimal practice to maximize a learner's progress still does not exist. Because we each learn differently and there are many choices for possible piano practice tasks and methods, the set of practice modes should be dynamically adapted to the human learner, a process typically guided by a teacher. However, having a human teacher guide individual practice is not always feasible since it is time-consuming, expensive, and often unavailable. In this work, we present a modeling framework to guide the human learner through the learning process by choosing the practice modes generated by a policy model. To this end, we present a computational architecture building on a Gaussian process that incorporates 1) the learner state, 2) a policy that selects a suitable practice mode, 3) performance evaluation, and 4) expert knowledge. The proposed policy model is trained to approximate the expert-learner interaction during a practice session. In our future work, we will test different Bayesian optimization techniques, e.g., different acquisition functions, and evaluate their effect on the learning progress.
Read more6/10/2024
0
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
Read more6/26/2024