Pixel Embedding: Fully Quantized Convolutional Neural Network with Differentiable Lookup Table

0

Sign in to get full access
Overview
- This paper introduces a new quantization technique called "Pixel Embedding" for convolutional neural networks (CNNs).
- It aims to fully quantize CNN models while maintaining their performance.
- The key idea is to learn a differentiable lookup table that maps between full-precision and quantized representations.
Plain English Explanation
The paper presents a new way to quantize convolutional neural networks (CNNs) - a type of deep learning model commonly used for image recognition tasks. Quantization is the process of reducing the number of bits used to represent the model's parameters, which can significantly reduce the model's size and memory requirements.
The key idea behind the "Pixel Embedding" technique is to learn a differentiable lookup table that maps between the full-precision (unquantized) and quantized representations of the model's parameters. This allows the model to be fully quantized while still maintaining its performance on the target task.
The authors demonstrate that their Pixel Embedding approach outperforms existing quantization techniques, particularly for mixed-precision settings where different parts of the model use different levels of quantization.
Technical Explanation
The paper introduces a new quantization technique called "Pixel Embedding" for convolutional neural networks (CNNs). The key idea is to learn a differentiable lookup table that maps between the full-precision (unquantized) and quantized representations of the model's parameters.
Specifically, the authors propose a CNN architecture that includes a Pixel Embedding layer, which is a learnable lookup table that maps the full-precision weights to their quantized counterparts. This lookup table is optimized during training along with the rest of the model parameters, allowing the quantized model to maintain its performance on the target task.
The paper presents experiments on various CNN architectures and datasets, demonstrating that the Pixel Embedding approach outperforms existing quantization techniques, especially in mixed-precision settings where different parts of the model use different levels of quantization.
Critical Analysis
The paper provides a novel and interesting approach to fully quantizing CNN models while maintaining their performance. The authors have carefully designed their experiments and provided a thorough technical explanation of their method.
One potential limitation of the Pixel Embedding approach is that the size of the lookup table may grow quickly as the model size or the number of quantization levels increases, which could impact the memory footprint and computational efficiency of the quantized model. The authors acknowledge this and suggest that further research is needed to address this scalability challenge.
Additionally, the paper does not explore the implications of the Pixel Embedding technique for other types of deep learning models beyond CNNs, such as transformers or recurrent neural networks. Examining the applicability of this approach to a broader range of neural network architectures could be a fruitful area for future research.
Conclusion
The "Pixel Embedding" technique presented in this paper is a promising approach for fully quantizing convolutional neural networks while maintaining their performance. By learning a differentiable lookup table to map between full-precision and quantized representations, the authors demonstrate that their method outperforms existing quantization techniques, particularly in mixed-precision settings.
This work contributes to the ongoing efforts to develop efficient and effective quantization methods for deep learning models, which is crucial for deploying such models on resource-constrained devices like mobile phones or embedded systems. Further research is needed to address the scalability challenges and explore the applicability of Pixel Embedding to a broader range of neural network architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pixel Embedding: Fully Quantized Convolutional Neural Network with Differentiable Lookup Table
Hiroyuki Tokunaga, Joel Nicholls, Daria Vazhenina, Atsunori Kanemura
By quantizing network weights and activations to low bitwidth, we can obtain hardware-friendly and energy-efficient networks. However, existing quantization techniques utilizing the straight-through estimator and piecewise constant functions face the issue of how to represent originally high-bit input data with low-bit values. To fully quantize deep neural networks, we propose pixel embedding, which replaces each float-valued input pixel with a vector of quantized values by using a lookup table. The lookup table or low-bit representation of pixels is differentiable and trainable by backpropagation. Such replacement of inputs with vectors is similar to word embedding in the natural language processing field. Experiments on ImageNet and CIFAR-100 show that pixel embedding reduces the top-5 error gap caused by quantizing the floating points at the first layer to only 1% for the ImageNet dataset, and the top-1 error gap caused by quantizing first and last layers to slightly over 1% for the CIFAR-100 dataset. The usefulness of pixel embedding is further demonstrated by inference time measurements, which demonstrate over 1.7 times speedup compared to floating point precision first layer.
Read more7/24/2024

0
Low-Bitwidth Floating Point Quantization for Efficient High-Quality Diffusion Models
Cheng Chen, Christina Giannoula, Andreas Moshovos
Diffusion models are emerging models that generate images by iteratively denoising random Gaussian noise using deep neural networks. These models typically exhibit high computational and memory demands, necessitating effective post-training quantization for high-performance inference. Recent works propose low-bitwidth (e.g., 8-bit or 4-bit) quantization for diffusion models, however 4-bit integer quantization typically results in low-quality images. We observe that on several widely used hardware platforms, there is little or no difference in compute capability between floating-point and integer arithmetic operations of the same bitwidth (e.g., 8-bit or 4-bit). Therefore, we propose an effective floating-point quantization method for diffusion models that provides better image quality compared to integer quantization methods. We employ a floating-point quantization method that was effective for other processing tasks, specifically computer vision and natural language tasks, and tailor it for diffusion models by integrating weight rounding learning during the mapping of the full-precision values to the quantized values in the quantization process. We comprehensively study integer and floating-point quantization methods in state-of-the-art diffusion models. Our floating-point quantization method not only generates higher-quality images than that of integer quantization methods, but also shows no noticeable degradation compared to full-precision models (32-bit floating-point), when both weights and activations are quantized to 8-bit floating-point values, while has minimal degradation with 4-bit weights and 8-bit activations.
Read more8/14/2024
🤿
0
Quality Scalable Quantization Methodology for Deep Learning on Edge
Salman Abdul Khaliq, Rehan Hafiz
Deep Learning Architectures employ heavy computations and bulk of the computational energy is taken up by the convolution operations in the Convolutional Neural Networks. The objective of our proposed work is to reduce the energy consumption and size of CNN for using machine learning techniques in edge computing on ubiquitous computing devices. We propose Systematic Quality Scalable Design Methodology consisting of Quality Scalable Quantization on a higher abstraction level and Quality Scalable Multipliers at lower abstraction level. The first component consists of parameter compression where we approximate representation of values in filters of deep learning models by encoding in 3 bits. A shift and scale based on-chip decoding hardware is proposed which can decode these 3-bit representations to recover approximate filter values. The size of the DNN model is reduced this way and can be sent over a communication channel to be decoded on the edge computing devices. This way power is reduced by limiting data bits by approximation. In the second component we propose a quality scalable multiplier which reduces the number of partial products by converting numbers in canonic sign digit representations and further approximating the number by reducing least significant bits. These quantized CNNs provide almost same ac-curacy as network with original weights with little or no fine-tuning. The hardware for the adaptive multipliers utilize gate clocking for reducing energy consumption during multiplications. The proposed methodology greatly reduces the memory and power requirements of DNN models making it a feasible approach to deploy Deep Learning on edge computing. The experiments done on LeNet and ConvNets show an increase upto 6% of zeros and memory savings upto 82.4919% while keeping the accuracy near the state of the art.
Read more7/17/2024
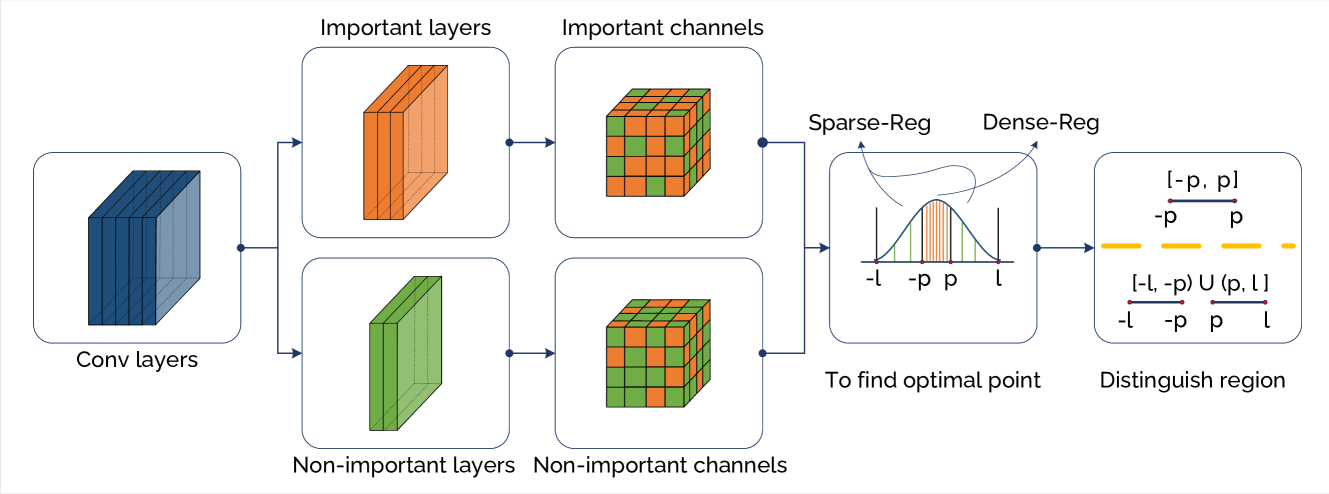
0
DNN Memory Footprint Reduction via Post-Training Intra-Layer Multi-Precision Quantization
Behnam Ghavami, Amin Kamjoo, Lesley Shannon, Steve Wilton
The imperative to deploy Deep Neural Network (DNN) models on resource-constrained edge devices, spurred by privacy concerns, has become increasingly apparent. To facilitate the transition from cloud to edge computing, this paper introduces a technique that effectively reduces the memory footprint of DNNs, accommodating the limitations of resource-constrained edge devices while preserving model accuracy. Our proposed technique, named Post-Training Intra-Layer Multi-Precision Quantization (PTILMPQ), employs a post-training quantization approach, eliminating the need for extensive training data. By estimating the importance of layers and channels within the network, the proposed method enables precise bit allocation throughout the quantization process. Experimental results demonstrate that PTILMPQ offers a promising solution for deploying DNNs on edge devices with restricted memory resources. For instance, in the case of ResNet50, it achieves an accuracy of 74.57% with a memory footprint of 9.5 MB, representing a 25.49% reduction compared to previous similar methods, with only a minor 1.08% decrease in accuracy.
Read more4/5/2024