Pixtral 12B

0
🔄
Sign in to get full access
Overview
- The provided paper aims to reproduce the reported performance of prior models in a fair re-evaluation.
- The authors examine the ability of models like Pixtral 12B to achieve strong performance without requiring special interventions.
- The paper conducts a thorough evaluation of various models using a common protocol, prompt, and metric.
Plain English Explanation
In this paper, the researchers wanted to [object Object]. They used the same evaluation setup, including the same prompt and metric, to assess the capabilities of different models.
The key finding is that some powerful models, like [object Object], can achieve impressive results without needing special adjustments or tuning. This is similar to what has been observed with other strong closed-source models, such as [object Object] and [object Object].
By using a consistent evaluation setup, the researchers were able to make a fair comparison of the models' performance. This helps provide a clearer understanding of the relative capabilities of different AI systems.
Technical Explanation
The paper's main focus is on [object Object] through a rigorous evaluation process. The authors set up a common evaluation harness, using the same prompt and metric, to assess the abilities of various models.
By tuning the evaluation settings to individual models, the researchers were able to recover the reported performance of each system. This approach allowed them to make a fair comparison, as opposed to relying on the original claims made by the model developers.
A key finding is that [object Object], like other strong closed-source models, is able to achieve impressive results without requiring special interventions. This suggests that these models possess inherent capabilities that enable them to perform well on the given task.
Critical Analysis
The paper provides a valuable contribution by [object Object] using a consistent evaluation setup. This helps to address the potential issue of model developers reporting inflated or optimistic performance claims.
However, the paper does not delve into the potential limitations or caveats of the models being examined. It would be helpful to understand any known weaknesses or areas for improvement in the evaluated systems.
Additionally, the paper could have explored the broader implications of the finding that some models can achieve strong performance without special tuning. This could lead to questions about the transparency and interpretability of these systems, as well as their potential biases or shortcomings.
Conclusion
This paper presents a [object Object] using a common evaluation protocol. The key insight is that certain powerful models, like Pixtral 12B, can achieve impressive results without requiring specific interventions or tuning.
This research helps to provide a more reliable and fair comparison of model capabilities, which is crucial for the responsible development and deployment of AI systems. By using a consistent evaluation approach, the study offers a clearer understanding of the relative strengths and limitations of different AI models.
However, the paper could have delved deeper into the potential limitations and broader implications of these findings, which would further enhance our understanding of the current state of AI technology and its future development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
New!Pixtral 12B
Pravesh Agrawal, Szymon Antoniak, Emma Bou Hanna, Devendra Chaplot, Jessica Chudnovsky, Saurabh Garg, Theophile Gervet, Soham Ghosh, Am'elie H'eliou, Paul Jacob, Albert Q. Jiang, Timoth'ee Lacroix, Guillaume Lample, Diego Las Casas, Thibaut Lavril, Teven Le Scao, Andy Lo, William Marshall, Louis Martin, Arthur Mensch, Pavankumar Muddireddy, Valera Nemychnikova, Marie Pellat, Patrick Von Platen, Nikhil Raghuraman, Baptiste Rozi`ere, Alexandre Sablayrolles, Lucile Saulnier, Romain Sauvestre, Wendy Shang, Roman Soletskyi, Lawrence Stewart, Pierre Stock, Joachim Studnia, Sandeep Subramanian, Sagar Vaze, Thomas Wang
We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B & Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
Read more10/10/2024
0
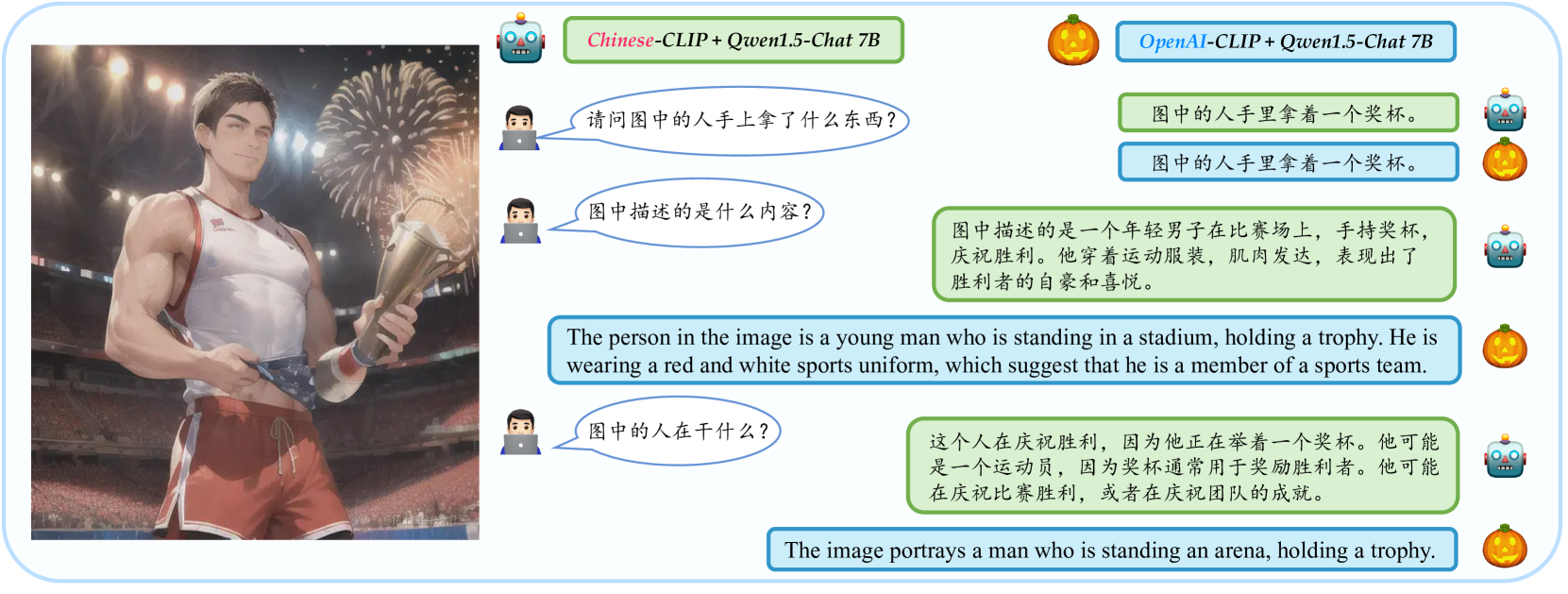
Parrot: Multilingual Visual Instruction Tuning
Hai-Long Sun, Da-Wei Zhou, Yang Li, Shiyin Lu, Chao Yi, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, Han-Jia Ye
The rapid development of Multimodal Large Language Models (MLLMs) like GPT-4V has marked a significant step towards artificial general intelligence. Existing methods mainly focus on aligning vision encoders with LLMs through supervised fine-tuning (SFT) to endow LLMs with multimodal abilities, making MLLMs' inherent ability to react to multiple languages progressively deteriorate as the training process evolves. We empirically find that the imbalanced SFT datasets, primarily composed of English-centric image-text pairs, lead to significantly reduced performance in non-English languages. This is due to the failure of aligning the vision encoder and LLM with multilingual tokens during the SFT process. In this paper, we introduce Parrot, a novel method that utilizes textual guidance to drive visual token alignment at the language level. Parrot makes the visual tokens condition on diverse language inputs and uses Mixture-of-Experts (MoE) to promote the alignment of multilingual tokens. Specifically, to enhance non-English visual tokens alignment, we compute the cross-attention using the initial visual features and textual embeddings, the result of which is then fed into the MoE router to select the most relevant experts. The selected experts subsequently convert the initial visual tokens into language-specific visual tokens. Moreover, considering the current lack of benchmarks for evaluating multilingual capabilities within the field, we collect and make available a Massive Multilingual Multimodal Benchmark which includes 6 languages, 15 categories, and 12,000 questions, named as MMMB. Our method not only demonstrates state-of-the-art performance on multilingual MMBench and MMMB, but also excels across a broad range of multimodal tasks. Both the source code and the training dataset of Parrot will be made publicly available. Code is available at: https://github.com/AIDC-AI/Parrot.
Read more8/13/2024
0
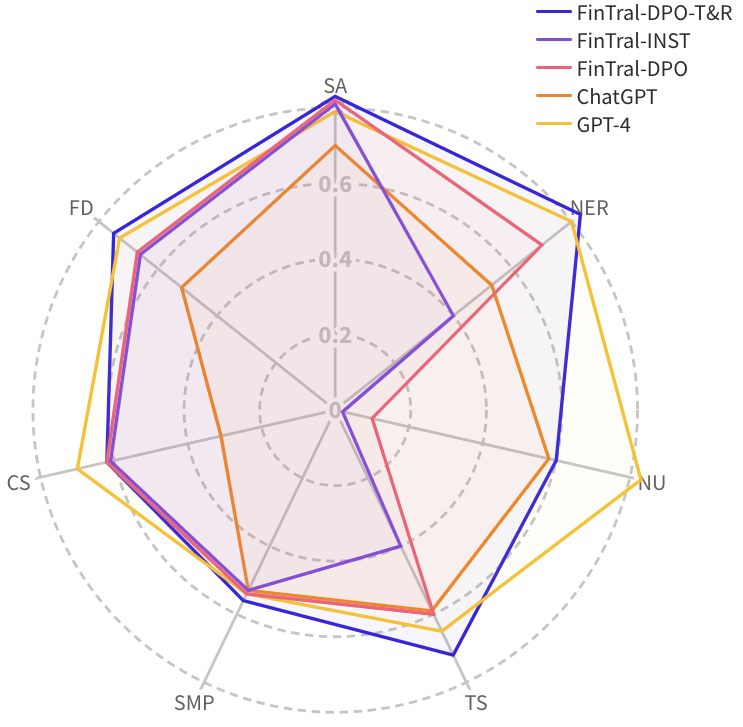
FinTral: A Family of GPT-4 Level Multimodal Financial Large Language Models
Gagan Bhatia, El Moatez Billah Nagoudi, Hasan Cavusoglu, Muhammad Abdul-Mageed
We introduce FinTral, a suite of state-of-the-art multimodal large language models (LLMs) built upon the Mistral-7b model and tailored for financial analysis. FinTral integrates textual, numerical, tabular, and image data. We enhance FinTral with domain-specific pretraining, instruction fine-tuning, and RLAIF training by exploiting a large collection of textual and visual datasets we curate for this work. We also introduce an extensive benchmark featuring nine tasks and 25 datasets for evaluation, including hallucinations in the financial domain. Our FinTral model trained with direct preference optimization employing advanced Tools and Retrieval methods, dubbed FinTral-DPO-T&R, demonstrates an exceptional zero-shot performance. It outperforms ChatGPT-3.5 in all tasks and surpasses GPT-4 in five out of nine tasks, marking a significant advancement in AI-driven financial technology. We also demonstrate that FinTral has the potential to excel in real-time analysis and decision-making in diverse financial contexts. The GitHub repository for FinTral is available at url{https://github.com/UBC-NLP/fintral}.
Read more6/17/2024

0
Babel-ImageNet: Massively Multilingual Evaluation of Vision-and-Language Representations
Gregor Geigle, Radu Timofte, Goran Glavav{s}
Vision-and-language (VL) models with separate encoders for each modality (e.g., CLIP) have become the go-to models for zero-shot image classification and image-text retrieval. They are, however, mostly evaluated in English as multilingual benchmarks are limited in availability. We introduce Babel-ImageNet, a massively multilingual benchmark that offers (partial) translations of ImageNet labels to 100 languages, built without machine translation or manual annotation. We instead automatically obtain reliable translations by linking them -- via shared WordNet synsets -- to BabelNet, a massively multilingual lexico-semantic network. We evaluate 11 public multilingual CLIP models on zero-shot image classification (ZS-IC) on our benchmark, demonstrating a significant gap between English ImageNet performance and that of high-resource languages (e.g., German or Chinese), and an even bigger gap for low-resource languages (e.g., Sinhala or Lao). Crucially, we show that the models' ZS-IC performance highly correlates with their performance in image-text retrieval, validating the use of Babel-ImageNet to evaluate multilingual models for the vast majority of languages without gold image-text data. Finally, we show that the performance of multilingual CLIP can be drastically improved for low-resource languages with parameter-efficient language-specific training. We make our code and data publicly available: url{https://github.com/gregor-ge/Babel-ImageNet}
Read more6/13/2024