PL-MTEB: Polish Massive Text Embedding Benchmark

0

Sign in to get full access
Overview
• The paper introduces PL-MTEB, a new benchmark for evaluating Polish language text embeddings. • PL-MTEB includes a large, diverse dataset of Polish texts across multiple domains and tasks. • The benchmark aims to spur development of high-quality Polish language models and advance natural language processing in Polish.
Plain English Explanation
The researchers created a new tool called PL-MTEB to help evaluate and improve language models for the Polish language. Language models are AI systems that can understand and generate human language. PL-MTEB is a benchmark, which means it's a standardized way to test how well these models perform on different language tasks.
PL-MTEB includes a big, varied dataset of Polish texts from many different topics and contexts. This allows researchers to thoroughly test Polish language models and see how well they can handle real-world Polish language usage. The goal is to drive progress in Polish NLP (natural language processing) by providing a way to measure and improve the performance of Polish language models.
[This benchmark builds on work like the <a href="https://aimodels.fyi/papers/arxiv/beir-pl-zero-shot-information-retrieval-benchmark">BEIR PL zero-shot information retrieval benchmark</a> and the <a href="https://aimodels.fyi/papers/arxiv/megaverse-benchmarking-large-language-models-across-languages">Megaverse benchmark for evaluating language models across languages</a>.]
Technical Explanation
The paper introduces PL-MTEB, a new Polish Massive Text Embedding Benchmark. PL-MTEB is designed to evaluate the performance of text embedding models for the Polish language. Text embeddings are mathematical representations of text that capture semantic meaning and can be used for a variety of natural language processing tasks.
PL-MTEB includes a large, diverse dataset of Polish language texts spanning multiple domains such as news, social media, and technical literature. The benchmark covers a range of fundamental NLP tasks like text classification, question answering, and semantic similarity. By providing a comprehensive set of evaluation tasks and data, PL-MTEB aims to spur the development of high-quality Polish language models and advance the state-of-the-art in Polish natural language processing.
[The authors draw inspiration from benchmarks like <a href="https://aimodels.fyi/papers/arxiv/enhancing-embedding-performance-through-large-language-model">EmbedBench</a> and <a href="https://aimodels.fyi/papers/arxiv/petkaz-at-semeval-2024-task-8-can">PETKAZ</a>, which have demonstrated the value of standardized evaluation frameworks for advancing language technology in other contexts.]
Critical Analysis
The PL-MTEB benchmark represents an important contribution to the field of Polish NLP. By providing a large, diverse, and standardized evaluation framework, the authors aim to drive progress in developing more capable Polish language models. This is a valuable pursuit, as high-performance Polish NLP tools can enable a wide range of applications and services for Polish-speaking users.
However, the authors acknowledge some limitations of the current benchmark. The dataset, while large, may not fully capture the breadth of Polish language usage, especially in emerging domains like social media, e-commerce, and technical documentation. Additionally, the benchmark tasks, while spanning core NLP competencies, may not reflect the full range of real-world applications for Polish language technology.
Further research could explore expanding the PL-MTEB dataset and task set to better represent the evolving needs of Polish language users. The authors could also investigate incorporating more advanced evaluation metrics, such as those that capture contextual understanding or model robustness. Ongoing refinement and expansion of PL-MTEB can help ensure it remains a valuable tool for driving progress in Polish NLP.
[Readers interested in related work may also want to explore <a href="https://aimodels.fyi/papers/arxiv/gecko-versatile-text-embeddings-distilled-from-large">GECKO</a>, which examines techniques for distilling high-quality text embeddings from large language models.]
Conclusion
The PL-MTEB benchmark represents an important step forward in advancing Polish natural language processing. By providing a large-scale, standardized evaluation framework, the authors aim to spur the development of more capable Polish language models that can support a wide range of applications and services for Polish-speaking users. While the current benchmark has some limitations, the authors' commitment to ongoing refinement and expansion can help ensure PL-MTEB remains a valuable tool for the Polish NLP community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PL-MTEB: Polish Massive Text Embedding Benchmark
Rafa{l} Po'swiata, S{l}awomir Dadas, Micha{l} Pere{l}kiewicz
In this paper, we introduce the Polish Massive Text Embedding Benchmark (PL-MTEB), a comprehensive benchmark for text embeddings in Polish. The PL-MTEB consists of 28 diverse NLP tasks from 5 task types. We adapted the tasks based on previously used datasets by the Polish NLP community. In addition, we created a new PLSC (Polish Library of Science Corpus) dataset consisting of titles and abstracts of scientific publications in Polish, which was used as the basis for two novel clustering tasks. We evaluated 15 publicly available models for text embedding, including Polish and multilingual ones, and collected detailed results for individual tasks and aggregated results for each task type and the entire benchmark. PL-MTEB comes with open-source code at https://github.com/rafalposwiata/pl-mteb.
Read more5/17/2024
0
Extending the Massive Text Embedding Benchmark to French
Mathieu Ciancone, Imene Kerboua, Marion Schaeffer, Wissam Siblini
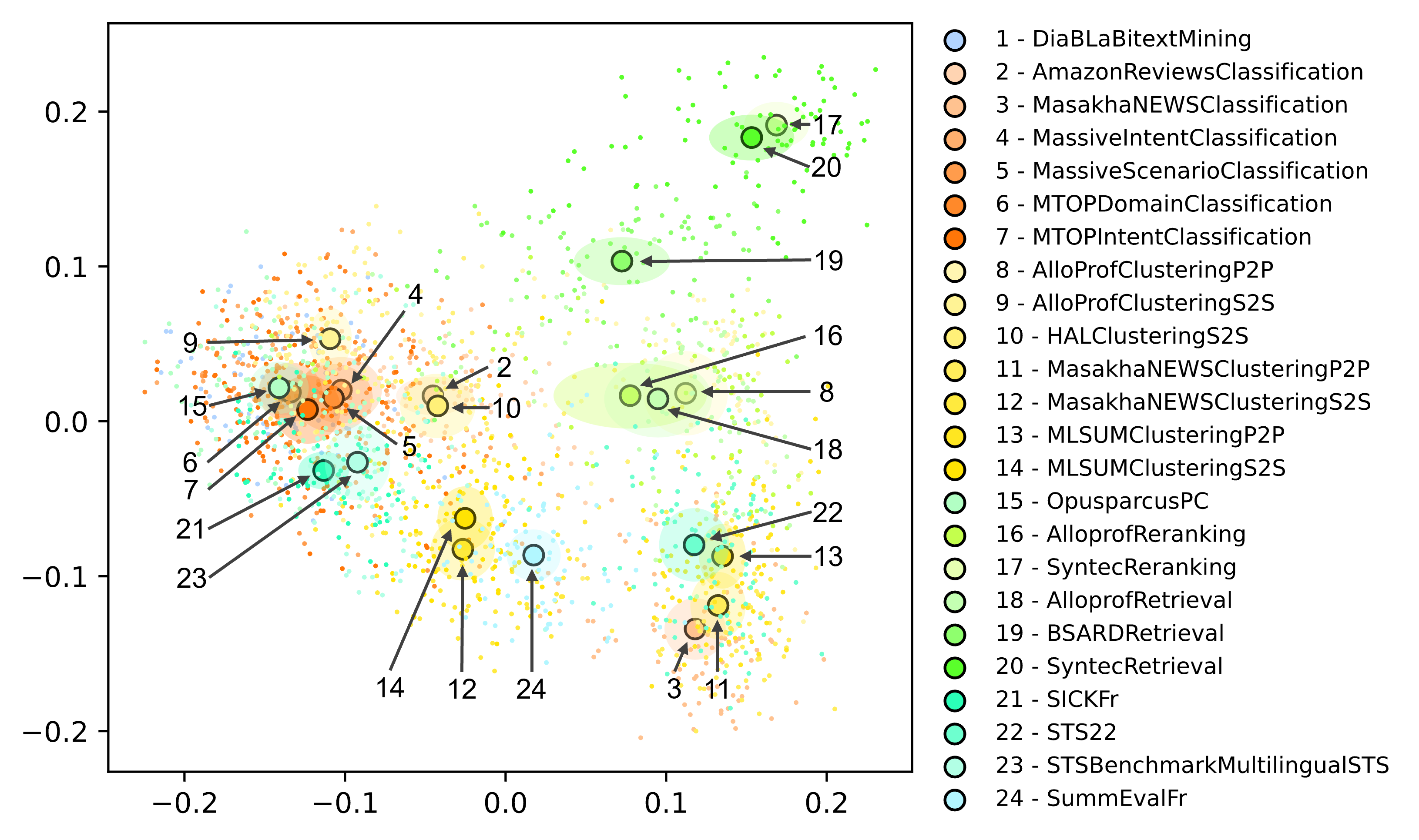
Recently, numerous embedding models have been made available and widely used for various NLP tasks. The Massive Text Embedding Benchmark (MTEB) has primarily simplified the process of choosing a model that performs well for several tasks in English, but extensions to other languages remain challenging. This is why we expand MTEB to propose the first massive benchmark of sentence embeddings for French. We gather 15 existing datasets in an easy-to-use interface and create three new French datasets for a global evaluation of 8 task categories. We compare 51 carefully selected embedding models on a large scale, conduct comprehensive statistical tests, and analyze the correlation between model performance and many of their characteristics. We find out that even if no model is the best on all tasks, large multilingual models pre-trained on sentence similarity perform exceptionally well. Our work comes with open-source code, new datasets and a public leaderboard.
Read more6/18/2024
0
The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding
Kenneth Enevoldsen, M'arton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo
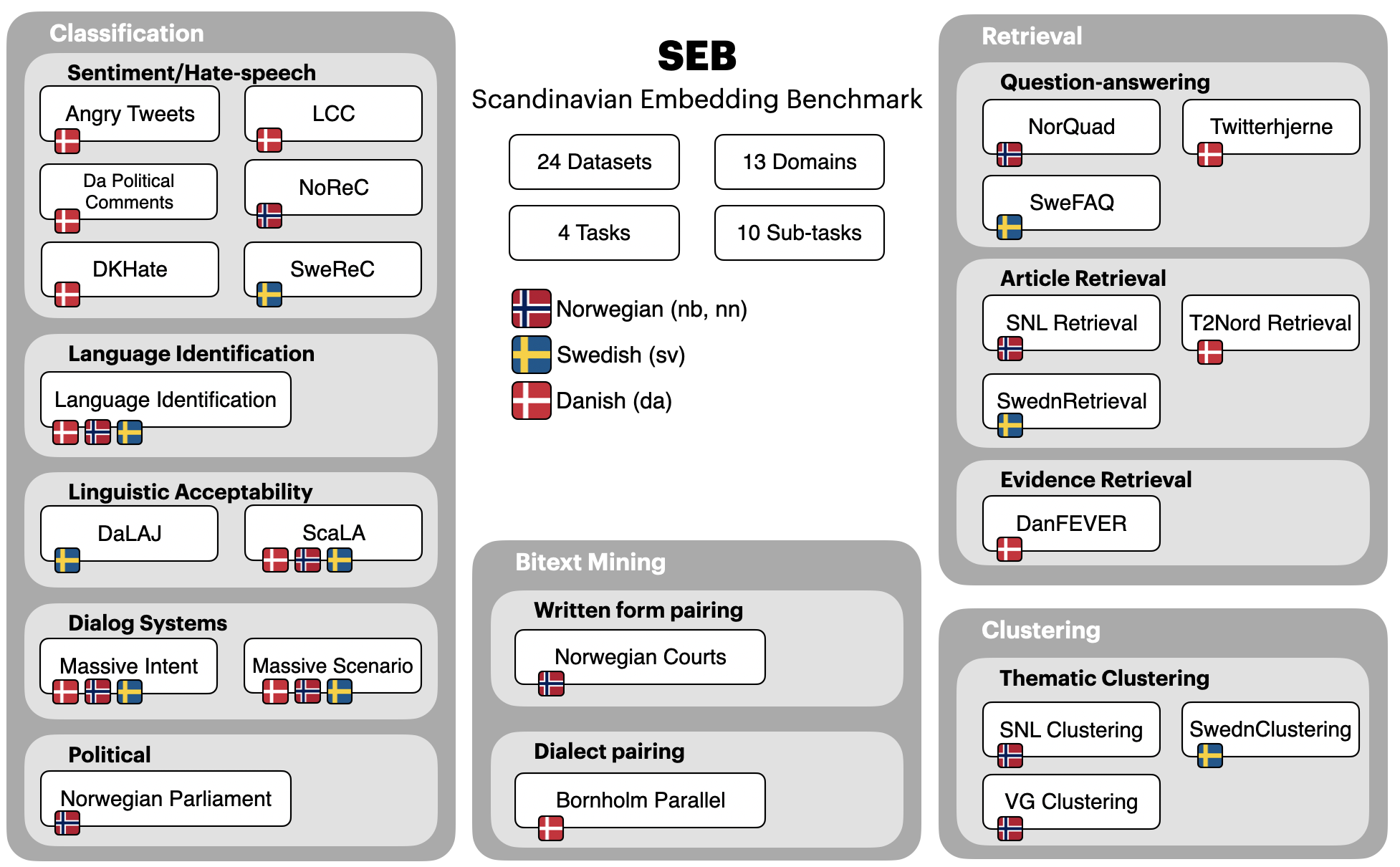
The evaluation of English text embeddings has transitioned from evaluating a handful of datasets to broad coverage across many tasks through benchmarks such as MTEB. However, this is not the case for multilingual text embeddings due to a lack of available benchmarks. To address this problem, we introduce the Scandinavian Embedding Benchmark (SEB). SEB is a comprehensive framework that enables text embedding evaluation for Scandinavian languages across 24 tasks, 10 subtasks, and 4 task categories. Building on SEB, we evaluate more than 26 models, uncovering significant performance disparities between public and commercial solutions not previously captured by MTEB. We open-source SEB and integrate it with MTEB, thus bridging the text embedding evaluation gap for Scandinavian languages.
Read more6/5/2024

0
Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark
Hongliu Cao
Text embedding methods have become increasingly popular in both industrial and academic fields due to their critical role in a variety of natural language processing tasks. The significance of universal text embeddings has been further highlighted with the rise of Large Language Models (LLMs) applications such as Retrieval-Augmented Systems (RAGs). While previous models have attempted to be general-purpose, they often struggle to generalize across tasks and domains. However, recent advancements in training data quantity, quality and diversity; synthetic data generation from LLMs as well as using LLMs as backbones encourage great improvements in pursuing universal text embeddings. In this paper, we provide an overview of the recent advances in universal text embedding models with a focus on the top performing text embeddings on Massive Text Embedding Benchmark (MTEB). Through detailed comparison and analysis, we highlight the key contributions and limitations in this area, and propose potentially inspiring future research directions.
Read more6/21/2024