The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding

0
Sign in to get full access
Overview
- This paper introduces the Scandinavian Embedding Benchmarks, a comprehensive assessment of multilingual and monolingual text embedding models.
- The benchmarks cover multiple Scandinavian languages, including Norwegian, Swedish, and Danish.
- The authors evaluate the performance of various text embedding models on a range of tasks, including semantic similarity, analogy, and classification.
Plain English Explanation
The paper presents a new set of benchmarks for evaluating how well text embedding models can understand and represent Scandinavian languages. Text embedding models are AI systems that convert words, sentences, or documents into numerical vectors, which can then be used for various language-related tasks.
The Scandinavian Embedding Benchmarks cover three main Scandinavian languages: Norwegian, Swedish, and Danish. The authors tested different text embedding models on a variety of tasks, such as measuring how well the models can understand the meaning of words and sentences, solve analogies, and classify text into different categories.
By creating these comprehensive benchmarks, the researchers aim to provide a more thorough assessment of the capabilities of text embedding models when it comes to Scandinavian languages. This can help developers and researchers improve the performance of these models, making them more useful for a wider range of applications, such as machine translation, text summarization, and language understanding.
Technical Explanation
The paper introduces the Scandinavian Embedding Benchmarks, a comprehensive evaluation framework for assessing the performance of text embedding models on Scandinavian languages. The benchmarks cover three main Scandinavian languages: Norwegian, Swedish, and Danish.
The authors curated several datasets for various tasks, including semantic similarity, analogy, and text classification. They evaluated the performance of various text embedding models, including monolingual and multilingual models, on these tasks. The models were trained on both Scandinavian-specific and general-purpose corpora.
The results show that while multilingual models can perform reasonably well on Scandinavian languages, there is still room for improvement, especially for more specialized tasks. The authors also found that models trained on Scandinavian-specific corpora generally outperform those trained on general-purpose corpora, highlighting the importance of specialized training data for these languages.
Critical Analysis
The Scandinavian Embedding Benchmarks provide a valuable resource for evaluating and improving text embedding models for Scandinavian languages. However, the paper does not address the limitations of the benchmarks, such as the potential bias in the datasets or the representativeness of the evaluated tasks.
Additionally, the paper does not discuss the ethical implications of using these text embedding models, such as the potential for perpetuating biases or the privacy concerns associated with large-scale language models. As these models become more widely adopted, it is crucial to consider these broader societal impacts.
Further research could also explore the generalizability of the findings to other low-resource languages or the potential for cross-lingual transfer learning to improve performance on Scandinavian languages.
Conclusion
The Scandinavian Embedding Benchmarks presented in this paper offer a comprehensive assessment of text embedding models for Scandinavian languages. By providing a standardized evaluation framework, the authors aim to drive progress in the development of more accurate and robust language models for these languages.
The findings suggest that while current multilingual models can perform reasonably well, there is still room for improvement, particularly in specialized tasks. The importance of using Scandinavian-specific training data is also highlighted. As text embedding models become more widely adopted, it will be crucial to consider their broader societal implications and continue to refine these benchmarking tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding
Kenneth Enevoldsen, M'arton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo
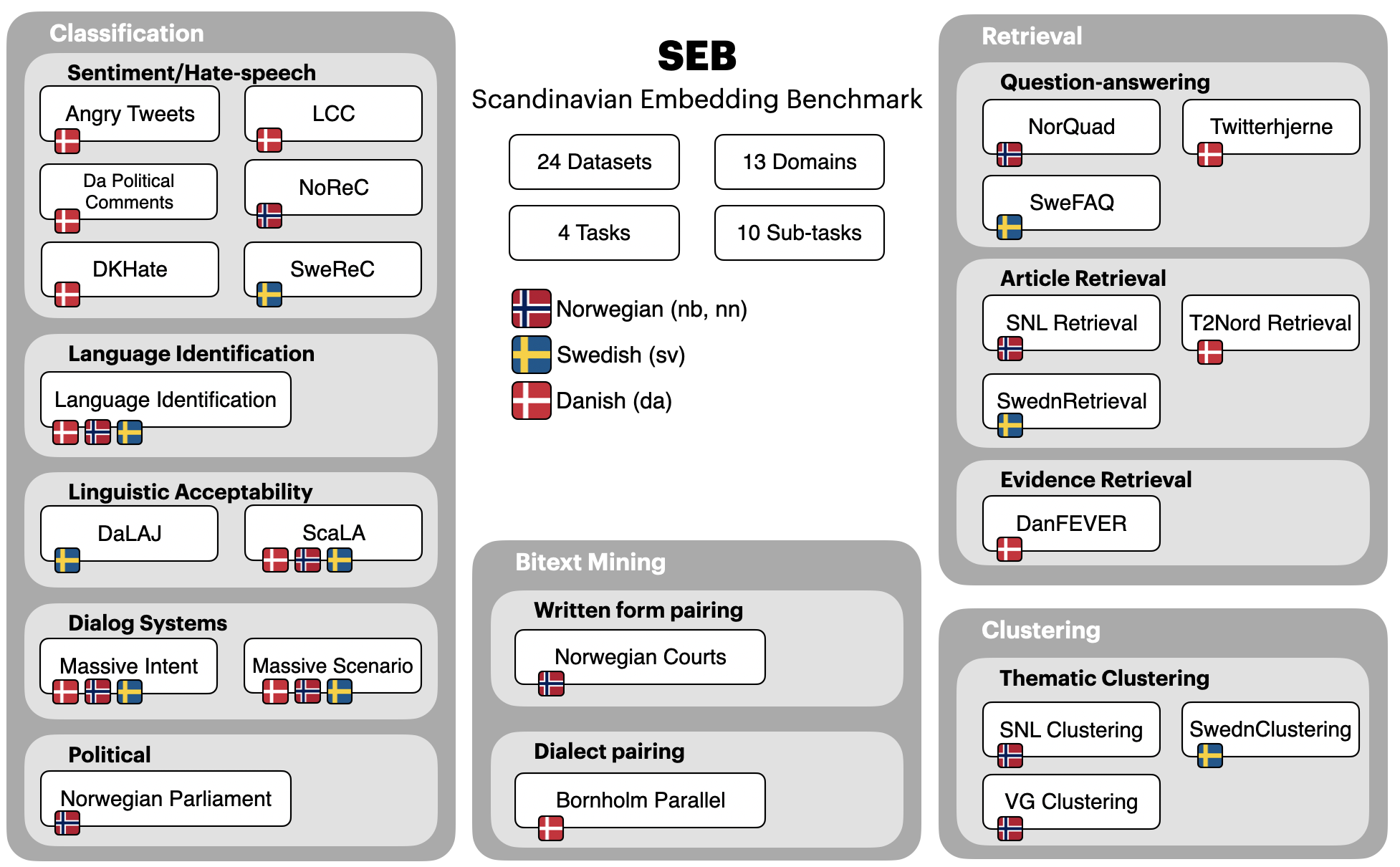
The evaluation of English text embeddings has transitioned from evaluating a handful of datasets to broad coverage across many tasks through benchmarks such as MTEB. However, this is not the case for multilingual text embeddings due to a lack of available benchmarks. To address this problem, we introduce the Scandinavian Embedding Benchmark (SEB). SEB is a comprehensive framework that enables text embedding evaluation for Scandinavian languages across 24 tasks, 10 subtasks, and 4 task categories. Building on SEB, we evaluate more than 26 models, uncovering significant performance disparities between public and commercial solutions not previously captured by MTEB. We open-source SEB and integrate it with MTEB, thus bridging the text embedding evaluation gap for Scandinavian languages.
Read more6/5/2024
0
Extending the Massive Text Embedding Benchmark to French
Mathieu Ciancone, Imene Kerboua, Marion Schaeffer, Wissam Siblini
Recently, numerous embedding models have been made available and widely used for various NLP tasks. The Massive Text Embedding Benchmark (MTEB) has primarily simplified the process of choosing a model that performs well for several tasks in English, but extensions to other languages remain challenging. This is why we expand MTEB to propose the first massive benchmark of sentence embeddings for French. We gather 15 existing datasets in an easy-to-use interface and create three new French datasets for a global evaluation of 8 task categories. We compare 51 carefully selected embedding models on a large scale, conduct comprehensive statistical tests, and analyze the correlation between model performance and many of their characteristics. We find out that even if no model is the best on all tasks, large multilingual models pre-trained on sentence similarity perform exceptionally well. Our work comes with open-source code, new datasets and a public leaderboard.
Read more6/18/2024

0
PL-MTEB: Polish Massive Text Embedding Benchmark
Rafa{l} Po'swiata, S{l}awomir Dadas, Micha{l} Pere{l}kiewicz
In this paper, we introduce the Polish Massive Text Embedding Benchmark (PL-MTEB), a comprehensive benchmark for text embeddings in Polish. The PL-MTEB consists of 28 diverse NLP tasks from 5 task types. We adapted the tasks based on previously used datasets by the Polish NLP community. In addition, we created a new PLSC (Polish Library of Science Corpus) dataset consisting of titles and abstracts of scientific publications in Polish, which was used as the basis for two novel clustering tasks. We evaluated 15 publicly available models for text embedding, including Polish and multilingual ones, and collected detailed results for individual tasks and aggregated results for each task type and the entire benchmark. PL-MTEB comes with open-source code at https://github.com/rafalposwiata/pl-mteb.
Read more5/17/2024

0
The Russian-focused embedders' exploration: ruMTEB benchmark and Russian embedding model design
Artem Snegirev, Maria Tikhonova, Anna Maksimova, Alena Fenogenova, Alexander Abramov
Embedding models play a crucial role in Natural Language Processing (NLP) by creating text embeddings used in various tasks such as information retrieval and assessing semantic text similarity. This paper focuses on research related to embedding models in the Russian language. It introduces a new Russian-focused embedding model called ru-en-RoSBERTa and the ruMTEB benchmark, the Russian version extending the Massive Text Embedding Benchmark (MTEB). Our benchmark includes seven categories of tasks, such as semantic textual similarity, text classification, reranking, and retrieval. The research also assesses a representative set of Russian and multilingual models on the proposed benchmark. The findings indicate that the new model achieves results that are on par with state-of-the-art models in Russian. We release the model ru-en-RoSBERTa, and the ruMTEB framework comes with open-source code, integration into the original framework and a public leaderboard.
Read more8/23/2024