PLAID SHIRTTT for Large-Scale Streaming Dense Retrieval
2405.00975
0
0
🔍
Abstract
PLAID, an efficient implementation of the ColBERT late interaction bi-encoder using pretrained language models for ranking, consistently achieves state-of-the-art performance in monolingual, cross-language, and multilingual retrieval. PLAID differs from ColBERT by assigning terms to clusters and representing those terms as cluster centroids plus compressed residual vectors. While PLAID is effective in batch experiments, its performance degrades in streaming settings where documents arrive over time because representations of new tokens may be poorly modeled by the earlier tokens used to select cluster centroids. PLAID Streaming Hierarchical Indexing that Runs on Terabytes of Temporal Text (PLAID SHIRTTT) addresses this concern using multi-phase incremental indexing based on hierarchical sharding. Experiments on ClueWeb09 and the multilingual NeuCLIR collection demonstrate the effectiveness of this approach both for the largest collection indexed to date by the ColBERT architecture and in the multilingual setting, respectively.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- PLAID is an efficient implementation of the ColBERT late interaction bi-encoder using pretrained language models for ranking
- It consistently achieves state-of-the-art performance in monolingual, cross-language, and multilingual retrieval
- PLAID differs from ColBERT by assigning terms to clusters and representing them as cluster centroids plus compressed residual vectors
- PLAID is effective in batch experiments, but its performance degrades in streaming settings where new tokens may be poorly modeled
- PLAID Streaming Hierarchical Indexing that Runs on Terabytes of Temporal Text (PLAID SHIRTTT) addresses this by using multi-phase incremental indexing based on hierarchical sharding
Plain English Explanation
PLAID is a powerful document retrieval system that outperforms other state-of-the-art approaches, even in multilingual and cross-language settings. It works by taking a novel approach to representing the terms in documents. Instead of treating each term individually, PLAID groups similar terms into clusters and represents them using a combination of cluster centroids and compressed "residual" vectors. This makes the system more efficient and effective.
However, PLAID has a weakness when it comes to streaming settings, where new documents are constantly being added. In these cases, the representations of new terms may not be well-captured by the earlier terms used to define the clusters. To address this, the researchers developed PLAID SHIRTTT, which uses a multi-phase indexing system based on hierarchical sharding. This allows the system to adapt to new documents and terms over time, maintaining its high performance.
The researchers tested PLAID and PLAID SHIRTTT on large-scale datasets, including the massive ClueWeb09 collection and the multilingual NeuCLIR dataset. The results demonstrate the effectiveness of these approaches, making them valuable tools for real-world information retrieval tasks.
Technical Explanation
PLAID is an efficient implementation of the ColBERT late interaction bi-encoder, a powerful document retrieval system that uses pretrained language models. Unlike traditional approaches that represent each term independently, PLAID assigns terms to clusters and represents them using a combination of cluster centroids and compressed "residual" vectors. This makes the system more efficient while maintaining high performance.
In batch experiments, PLAID consistently achieves state-of-the-art results in monolingual, cross-language, and multilingual retrieval tasks. However, the researchers found that PLAID's performance degrades in streaming settings, where new documents and terms are constantly being added. This is because the representations of new tokens may not be well-captured by the earlier terms used to define the clusters.
To address this issue, the researchers developed PLAID SHIRTTT, which uses a multi-phase incremental indexing system based on hierarchical sharding. This allows the system to adapt to new documents and terms over time, maintaining its high performance even in streaming scenarios.
The researchers evaluated PLAID and PLAID SHIRTTT on two large-scale datasets: the ClueWeb09 collection, which is the largest collection indexed to date by the ColBERT architecture, and the multilingual NeuCLIR dataset. The results demonstrate the effectiveness of these approaches, making them valuable tools for real-world information retrieval tasks.
Critical Analysis
The PLAID and PLAID SHIRTTT approaches represent significant advancements in the field of document retrieval, particularly in their ability to handle large-scale, multilingual, and streaming data. However, the paper does mention some caveats and areas for further research.
One potential limitation is the reliance on pretrained language models, which can be computationally expensive and may not be practical for all use cases. Additionally, the effectiveness of the clustering-based term representation may be sensitive to the quality and composition of the training data, which could be a concern in some domains.
The researchers also acknowledge that the PLAID SHIRTTT approach, while effective, adds additional complexity to the system. Further research may be needed to explore more efficient or simplified methods for handling streaming data in a way that maintains PLAID's high performance.
Overall, the PLAID and PLAID SHIRTTT systems represent impressive advancements in the field of document retrieval, particularly in their ability to handle large-scale, multilingual, and temporal data. However, as with any research, there are areas for further exploration and potential improvements that could be addressed in future work.
Conclusion
The PLAID and PLAID SHIRTTT systems described in this paper are highly effective and efficient document retrieval systems that consistently achieve state-of-the-art performance, even in challenging multilingual and streaming settings. By using a novel approach to term representation based on clustering and compressed residual vectors, PLAID is able to outperform other leading methods.
The development of PLAID SHIRTTT, which incorporates a multi-phase incremental indexing system, further enhances the system's ability to handle streaming data, making it a valuable tool for real-world information retrieval tasks. The researchers' extensive evaluation on large-scale datasets like ClueWeb09 and NeuCLIR demonstrates the practical viability and impact of these advancements.
While there are some potential limitations and areas for further research, the PLAID and PLAID SHIRTTT systems represent significant progress in the field of document retrieval. Their ability to consistently deliver state-of-the-art performance across a wide range of settings and tasks makes them highly promising approaches for a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Reproducibility Study of PLAID
Sean MacAvaney, Nicola Tonellotto
0
0
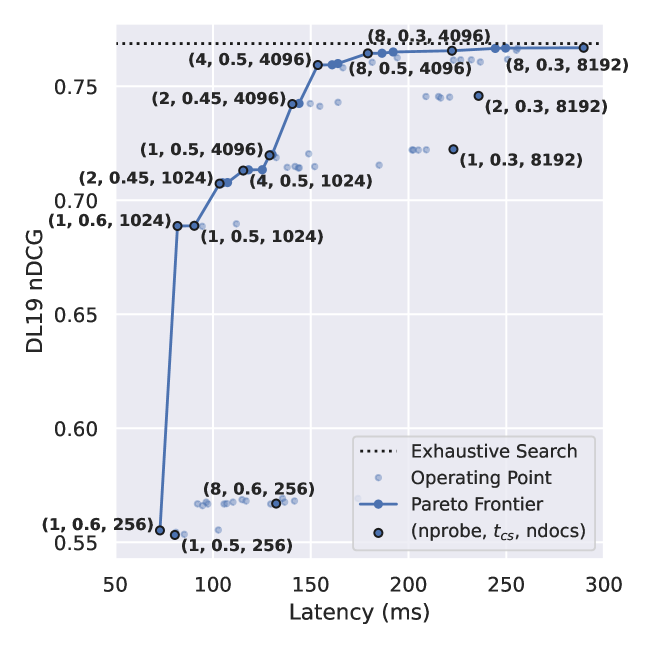
The PLAID (Performance-optimized Late Interaction Driver) algorithm for ColBERTv2 uses clustered term representations to retrieve and progressively prune documents for final (exact) document scoring. In this paper, we reproduce and fill in missing gaps from the original work. By studying the parameters PLAID introduces, we find that its Pareto frontier is formed of a careful balance among its three parameters; deviations beyond the suggested settings can substantially increase latency without necessarily improving its effectiveness. We then compare PLAID with an important baseline missing from the paper: re-ranking a lexical system. We find that applying ColBERTv2 as a re-ranker atop an initial pool of BM25 results provides better efficiency-effectiveness trade-offs in low-latency settings. However, re-ranking cannot reach peak effectiveness at higher latency settings due to limitations in recall of lexical matching and provides a poor approximation of an exhaustive ColBERTv2 search. We find that recently proposed modifications to re-ranking that pull in the neighbors of top-scoring documents overcome this limitation, providing a Pareto frontier across all operational points for ColBERTv2 when evaluated using a well-annotated dataset. Curious about why re-ranking methods are highly competitive with PLAID, we analyze the token representation clusters PLAID uses for retrieval and find that most clusters are predominantly aligned with a single token and vice versa. Given the competitive trade-offs that re-ranking baselines exhibit, this work highlights the importance of carefully selecting pertinent baselines when evaluating the efficiency of retrieval engines.
4/24/2024
SPLATE: Sparse Late Interaction Retrieval
Thibault Formal, St'ephane Clinchant, Herv'e D'ejean, Carlos Lassance
0
0
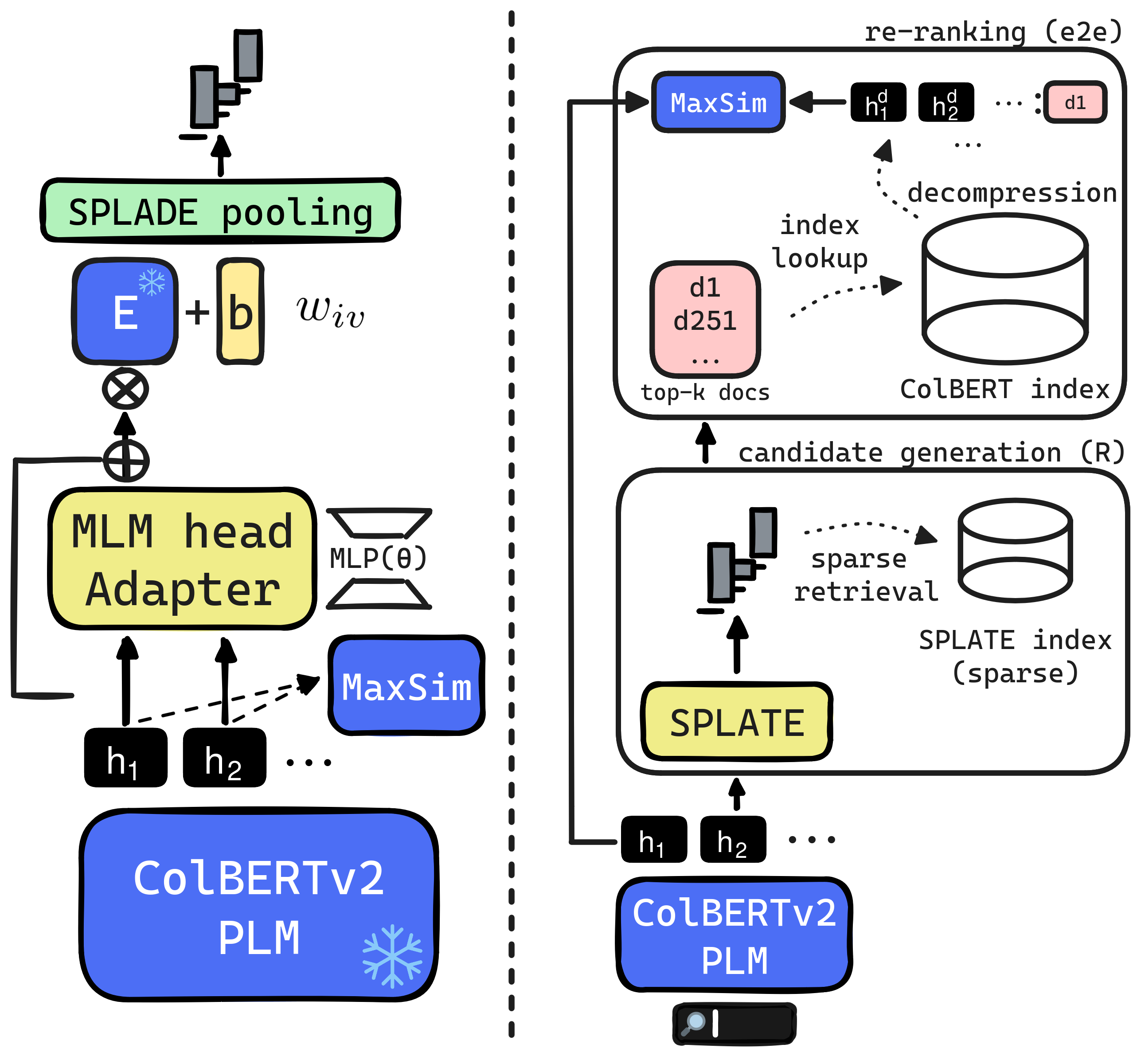
The late interaction paradigm introduced with ColBERT stands out in the neural Information Retrieval space, offering a compelling effectiveness-efficiency trade-off across many benchmarks. Efficient late interaction retrieval is based on an optimized multi-step strategy, where an approximate search first identifies a set of candidate documents to re-rank exactly. In this work, we introduce SPLATE, a simple and lightweight adaptation of the ColBERTv2 model which learns an ``MLM adapter'', mapping its frozen token embeddings to a sparse vocabulary space with a partially learned SPLADE module. This allows us to perform the candidate generation step in late interaction pipelines with traditional sparse retrieval techniques, making it particularly appealing for running ColBERT in CPU environments. Our SPLATE ColBERTv2 pipeline achieves the same effectiveness as the PLAID ColBERTv2 engine by re-ranking 50 documents that can be retrieved under 10ms.
4/23/2024
🏋️
HLTCOE at TREC 2023 NeuCLIR Track
Eugene Yang, Dawn Lawrie, James Mayfield
0
0
The HLTCOE team applied PLAID, an mT5 reranker, and document translation to the TREC 2023 NeuCLIR track. For PLAID we included a variety of models and training techniques -- the English model released with ColBERT v2, translate-train~(TT), Translate Distill~(TD) and multilingual translate-train~(MTT). TT trains a ColBERT model with English queries and passages automatically translated into the document language from the MS-MARCO v1 collection. This results in three cross-language models for the track, one per language. MTT creates a single model for all three document languages by combining the translations of MS-MARCO passages in all three languages into mixed-language batches. Thus the model learns about matching queries to passages simultaneously in all languages. Distillation uses scores from the mT5 model over non-English translated document pairs to learn how to score query-document pairs. The team submitted runs to all NeuCLIR tasks: the CLIR and MLIR news task as well as the technical documents task.
4/15/2024
Contextualization with SPLADE for High Recall Retrieval
Eugene Yang
0
0
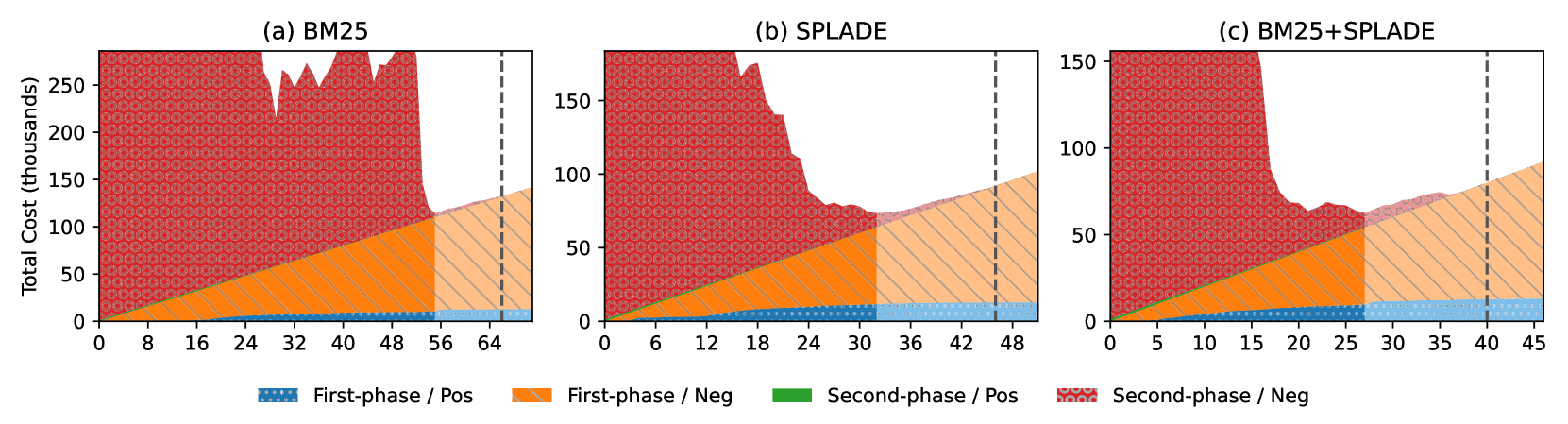
High Recall Retrieval (HRR), such as eDiscovery and medical systematic review, is a search problem that optimizes the cost of retrieving most relevant documents in a given collection. Iterative approaches, such as iterative relevance feedback and uncertainty sampling, are shown to be effective under various operational scenarios. Despite neural models demonstrating success in other text-related tasks, linear models such as logistic regression, in general, are still more effective and efficient in HRR since the model is trained and retrieves documents from the same fixed collection. In this work, we leverage SPLADE, an efficient retrieval model that transforms documents into contextualized sparse vectors, for HRR. Our approach combines the best of both worlds, leveraging both the contextualization from pretrained language models and the efficiency of linear models. It reduces 10% and 18% of the review cost in two HRR evaluation collections under a one-phase review workflow with a target recall of 80%. The experiment is implemented with TARexp and is available at https://github.com/eugene-yang/LSR-for-TAR.
5/8/2024