Contextualization with SPLADE for High Recall Retrieval

0
Sign in to get full access
Overview
- This paper introduces a novel approach called SPLADE (Sparse Lexical Approximation for Dense Embeddings) for high recall information retrieval.
- SPLADE aims to achieve high recall by leveraging contextualization and sparse interaction between query and document representations.
- The proposed method builds upon previous work on Sparse Late Interaction and Two-Step SPLADE, further enhancing the retrieval performance.
- SPLADE is evaluated on several benchmark datasets for high recall retrieval, demonstrating its effectiveness compared to state-of-the-art methods.
Plain English Explanation
The paper presents a new technique called SPLADE (Sparse Lexical Approximation for Dense Embeddings) that is designed to help search engines and information retrieval systems find more relevant documents, even if they don't perfectly match the search query.
The key idea behind SPLADE is to use a more sophisticated way of comparing the search query to the documents in the database. Rather than just looking for exact keyword matches, SPLADE tries to understand the meaning and context of both the query and the documents. This allows it to identify relevant documents that may use different words but convey similar information.
SPLADE builds on previous research on Sparse Late Interaction and Two-Step SPLADE, improving upon those techniques to achieve even better results at retrieving relevant documents, even if they don't perfectly match the search query.
The paper evaluates SPLADE on several standard benchmark datasets used in information retrieval research. The results show that SPLADE outperforms other state-of-the-art methods at retrieving a larger number of relevant documents, without sacrificing precision.
This could be useful in a variety of applications, such as academic search, e-commerce product search, or legal document discovery, where it's important to find all the relevant information, even if it's not an exact match to the original query.
Technical Explanation
The paper introduces a novel approach called SPLADE (Sparse Lexical Approximation for Dense Embeddings) for high recall information retrieval. SPLADE builds upon previous work on Sparse Late Interaction and Two-Step SPLADE, further enhancing the retrieval performance.
SPLADE aims to achieve high recall by leveraging contextualization and sparse interaction between query and document representations. The key idea is to learn a sparse projection of the query and document representations onto a shared sparse lexical space, which allows for more effective matching of semantically related content.
The SPLADE model consists of two main components: a lexical projection layer and a sparse interaction layer. The lexical projection layer maps the query and document representations into a sparse lexical space, preserving essential semantic information. The sparse interaction layer then computes the sparse interactions between the projected query and document representations, capturing the relevance signals.
SPLADE is evaluated on several benchmark datasets for high recall retrieval, including TREC Web, MS MARCO, and TREC COVID. The results demonstrate that SPLADE outperforms state-of-the-art methods, achieving significant improvements in terms of high recall retrieval performance.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the SPLADE model, comparing it against a variety of strong baseline methods on several established benchmark datasets. The authors have carefully considered the existing research landscape and built upon previous work in a meaningful way.
One potential limitation of the SPLADE approach is its reliance on sparse representations, which can be more challenging to optimize and may not capture all the nuances of language. The authors acknowledge this and suggest that exploring dense representations or hybrid approaches could be a fruitful direction for future research.
Additionally, the paper does not delve deeply into the potential biases or fairness considerations of the SPLADE model. As information retrieval systems become more widely deployed, it is crucial to consider how they may inadvertently amplify societal biases or exclude certain groups of users. Further research in this area would be valuable.
Overall, the SPLADE approach represents a significant contribution to the field of high recall information retrieval. By leveraging contextualization and sparse interactions, the model demonstrates impressive performance gains over existing methods. As the authors note, applying these techniques to other information retrieval tasks, such as entity linking or making retrieval-augmented language models more robust, could be a fruitful area for future exploration.
Conclusion
The Contextualization with SPLADE for High Recall Retrieval paper introduces a novel approach called SPLADE that aims to improve the recall of information retrieval systems. SPLADE leverages contextualization and sparse interactions between query and document representations to identify relevant content, even if it doesn't perfectly match the original search query.
The evaluation results demonstrate that SPLADE outperforms state-of-the-art methods on several benchmark datasets, making it a promising technique for a wide range of applications where high recall is crucial, such as academic search, e-commerce, and legal document discovery.
While the paper highlights some potential limitations, such as the reliance on sparse representations, the SPLADE approach represents a significant advancement in the field of information retrieval. Further research exploring hybrid approaches or addressing fairness considerations could help unlock even greater potential for this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contextualization with SPLADE for High Recall Retrieval
Eugene Yang
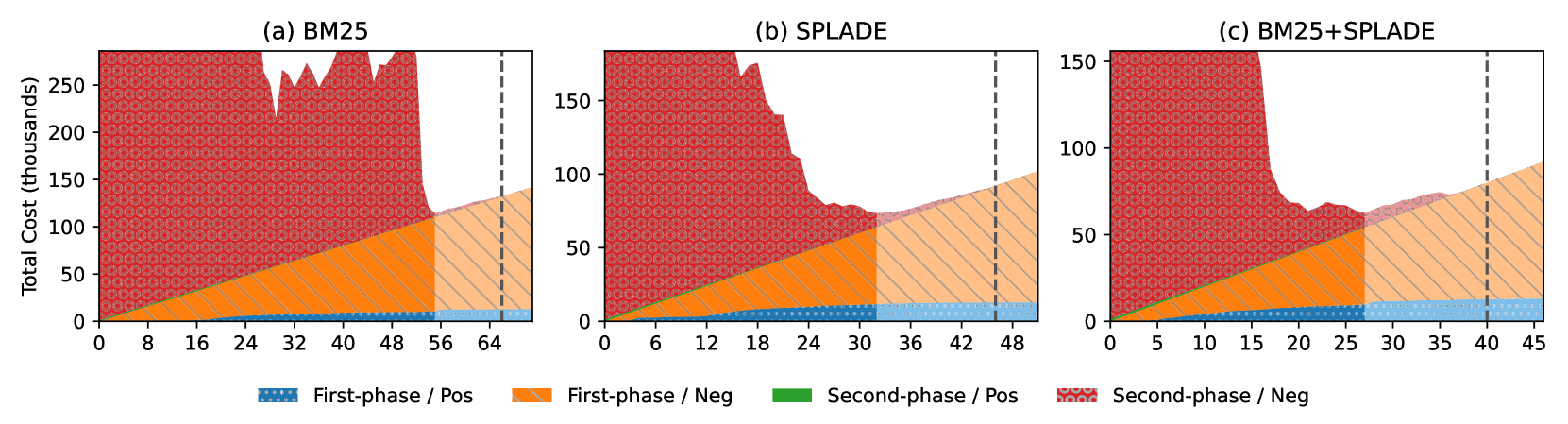
High Recall Retrieval (HRR), such as eDiscovery and medical systematic review, is a search problem that optimizes the cost of retrieving most relevant documents in a given collection. Iterative approaches, such as iterative relevance feedback and uncertainty sampling, are shown to be effective under various operational scenarios. Despite neural models demonstrating success in other text-related tasks, linear models such as logistic regression, in general, are still more effective and efficient in HRR since the model is trained and retrieves documents from the same fixed collection. In this work, we leverage SPLADE, an efficient retrieval model that transforms documents into contextualized sparse vectors, for HRR. Our approach combines the best of both worlds, leveraging both the contextualization from pretrained language models and the efficiency of linear models. It reduces 10% and 18% of the review cost in two HRR evaluation collections under a one-phase review workflow with a target recall of 80%. The experiment is implemented with TARexp and is available at https://github.com/eugene-yang/LSR-for-TAR.
Read more5/8/2024
🤷
0
CoSPLADE: Contextualizing SPLADE for Conversational Information Retrieval
Nam Le Hai, Thomas Gerald, Thibault Formal, Jian-Yun Nie, Benjamin Piwowarski, Laure Soulier
Conversational search is a difficult task as it aims at retrieving documents based not only on the current user query but also on the full conversation history. Most of the previous methods have focused on a multi-stage ranking approach relying on query reformulation, a critical intermediate step that might lead to a sub-optimal retrieval. Other approaches have tried to use a fully neural IR first-stage, but are either zero-shot or rely on full learning-to-rank based on a dataset with pseudo-labels. In this work, leveraging the CANARD dataset, we propose an innovative lightweight learning technique to train a first-stage ranker based on SPLADE. By relying on SPLADE sparse representations, we show that, when combined with a second-stage ranker based on T5Mono, the results are competitive on the TREC CAsT 2020 and 2021 tracks.
Read more7/8/2024
0
Two-Step SPLADE: Simple, Efficient and Effective Approximation of SPLADE
Carlos Lassance, Herv'e Dejean, St'ephane Clinchant, Nicola Tonellotto
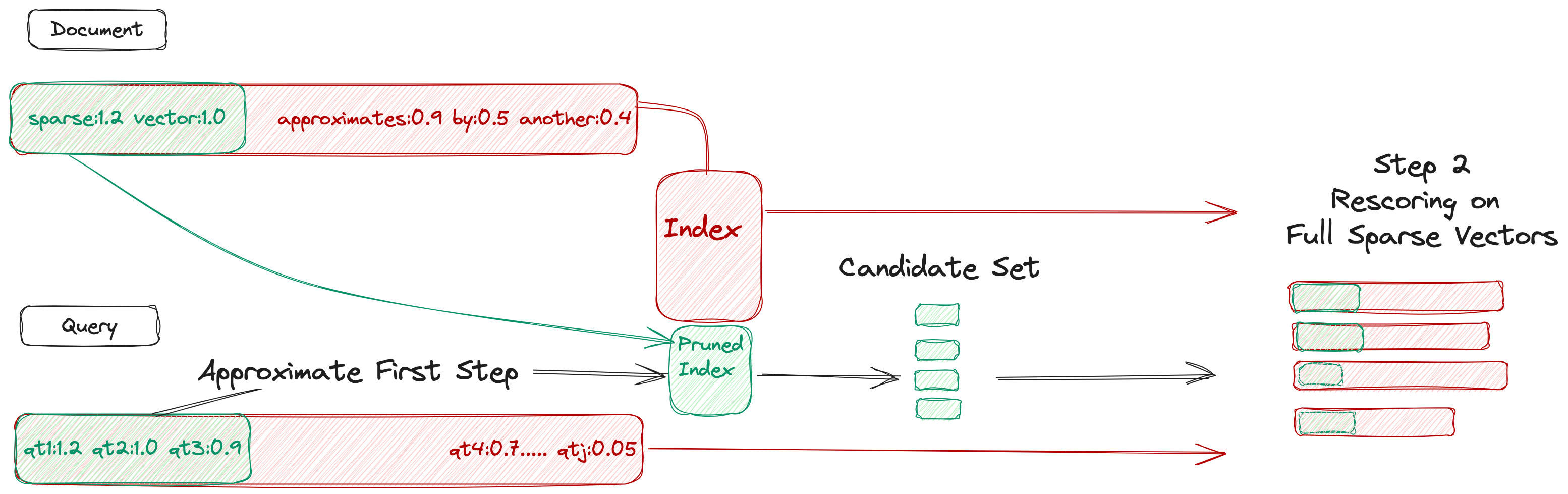
Learned sparse models such as SPLADE have successfully shown how to incorporate the benefits of state-of-the-art neural information retrieval models into the classical inverted index data structure. Despite their improvements in effectiveness, learned sparse models are not as efficient as classical sparse model such as BM25. The problem has been investigated and addressed by recently developed strategies, such as guided traversal query processing and static pruning, with different degrees of success on in-domain and out-of-domain datasets. In this work, we propose a new query processing strategy for SPLADE based on a two-step cascade. The first step uses a pruned and reweighted version of the SPLADE sparse vectors, and the second step uses the original SPLADE vectors to re-score a sample of documents retrieved in the first stage. Our extensive experiments, performed on 30 different in-domain and out-of-domain datasets, show that our proposed strategy is able to improve mean and tail response times over the original single-stage SPLADE processing by up to $30times$ and $40times$, respectively, for in-domain datasets, and by 12x to 25x, for mean response on out-of-domain datasets, while not incurring in statistical significant difference in 60% of datasets.
Read more4/23/2024

0
Mistral-SPLADE: LLMs for for better Learned Sparse Retrieval
Meet Doshi, Vishwajeet Kumar, Rudra Murthy, Vignesh P, Jaydeep Sen
Learned Sparse Retrievers (LSR) have evolved into an effective retrieval strategy that can bridge the gap between traditional keyword-based sparse retrievers and embedding-based dense retrievers. At its core, learned sparse retrievers try to learn the most important semantic keyword expansions from a query and/or document which can facilitate better retrieval with overlapping keyword expansions. LSR like SPLADE has typically been using encoder only models with MLM (masked language modeling) style objective in conjunction with known ways of retrieval performance improvement such as hard negative mining, distillation, etc. In this work, we propose to use decoder-only model for learning semantic keyword expansion. We posit, decoder only models that have seen much higher magnitudes of data are better equipped to learn keyword expansions needed for improved retrieval. We use Mistral as the backbone to develop our Learned Sparse Retriever similar to SPLADE and train it on a subset of sentence-transformer data which is often used for training text embedding models. Our experiments support the hypothesis that a sparse retrieval model based on decoder only large language model (LLM) surpasses the performance of existing LSR systems, including SPLADE and all its variants. The LLM based model (Echo-Mistral-SPLADE) now stands as a state-of-the-art learned sparse retrieval model on the BEIR text retrieval benchmark.
Read more8/23/2024