Plane2Depth: Hierarchical Adaptive Plane Guidance for Monocular Depth Estimation

0

Sign in to get full access
Overview
- Monocular depth estimation is the task of predicting the depth of a scene from a single image.
- Plane2Depth proposes a hierarchical adaptive plane guidance approach for monocular depth estimation.
- The method uses transformer-based plane detection and guidance to improve depth prediction.
Plain English Explanation
Monocular depth estimation is the process of figuring out how far away objects are in a single photograph, without any additional information. Plane2Depth is a new technique that helps improve the accuracy of this depth prediction.
The key idea is to first detect the flat surfaces or "planes" in the image, and then use this information to guide the depth estimation process. The method uses a transformer-based neural network to identify these planes in a hierarchical, adaptive way. This plane information is then incorporated to produce a more accurate depth map of the scene.
The advantage of this approach is that it can better handle complex scenes with multiple surfaces at different depths. By focusing on the planar structures, the model can more reliably estimate the overall depth arrangement. This makes the depth predictions more robust and reliable compared to previous methods that did not explicitly leverage the planar geometry.
Technical Explanation
Plane2Depth introduces a novel hierarchical adaptive plane guidance approach for monocular depth estimation. The method first uses a transformer-based plane detection network to identify the planar surfaces in the input image. This plane information is then adaptively integrated into a depth estimation network to guide the dense depth prediction.
The plane detection network operates in a coarse-to-fine hierarchical manner, progressively refining the plane segmentation as the features are passed through multiple transformer encoder-decoder layers. The resulting plane parameters are then used to warp the features of the depth network, aligning them with the detected planar structures. This helps the depth network focus on the key geometric cues provided by the planes, leading to more accurate depth estimation.
Experiments on benchmark datasets show that Plane2Depth outperforms previous state-of-the-art monocular depth estimation methods, demonstrating the benefits of the hierarchical adaptive plane guidance approach.
Critical Analysis
The Plane2Depth paper presents an innovative solution to the challenging problem of monocular depth estimation. By explicitly modeling the planar geometry of scenes, the method is able to produce more reliable depth predictions compared to previous techniques.
However, the paper does not address some potential limitations of the approach. For example, the method may struggle in scenes with complex, non-planar surfaces that cannot be well approximated by the detected planes. Additionally, the reliance on accurate plane detection could make the overall system more vulnerable to errors in this initial step.
Further research could explore ways to better integrate non-planar cues, or to make the plane detection more robust to challenging real-world conditions. Investigating the performance of Plane2Depth on a wider variety of datasets and application scenarios would also help assess the generalizability of the approach.
Conclusion
Plane2Depth presents an innovative approach to monocular depth estimation that leverages hierarchical adaptive plane guidance. By incorporating planar geometric cues into the depth prediction process, the method is able to achieve state-of-the-art performance on benchmark datasets.
This work highlights the importance of incorporating scene-level structural information to improve dense prediction tasks like depth estimation. The hierarchical and adaptive nature of the plane guidance allows the model to effectively adapt to the varying planar structures in complex scenes. As monocular depth estimation continues to be a crucial capability for various computer vision applications, techniques like Plane2Depth will play an important role in advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Plane2Depth: Hierarchical Adaptive Plane Guidance for Monocular Depth Estimation
Li Liu, Ruijie Zhu, Jiacheng Deng, Ziyang Song, Wenfei Yang, Tianzhu Zhang
Monocular depth estimation aims to infer a dense depth map from a single image, which is a fundamental and prevalent task in computer vision. Many previous works have shown impressive depth estimation results through carefully designed network structures, but they usually ignore the planar information and therefore perform poorly in low-texture areas of indoor scenes. In this paper, we propose Plane2Depth, which adaptively utilizes plane information to improve depth prediction within a hierarchical framework. Specifically, in the proposed plane guided depth generator (PGDG), we design a set of plane queries as prototypes to softly model planes in the scene and predict per-pixel plane coefficients. Then the predicted plane coefficients can be converted into metric depth values with the pinhole camera model. In the proposed adaptive plane query aggregation (APGA) module, we introduce a novel feature interaction approach to improve the aggregation of multi-scale plane features in a top-down manner. Extensive experiments show that our method can achieve outstanding performance, especially in low-texture or repetitive areas. Furthermore, under the same backbone network, our method outperforms the state-of-the-art methods on the NYU-Depth-v2 dataset, achieves competitive results with state-of-the-art methods KITTI dataset and can be generalized to unseen scenes effectively.
Read more9/5/2024
0
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
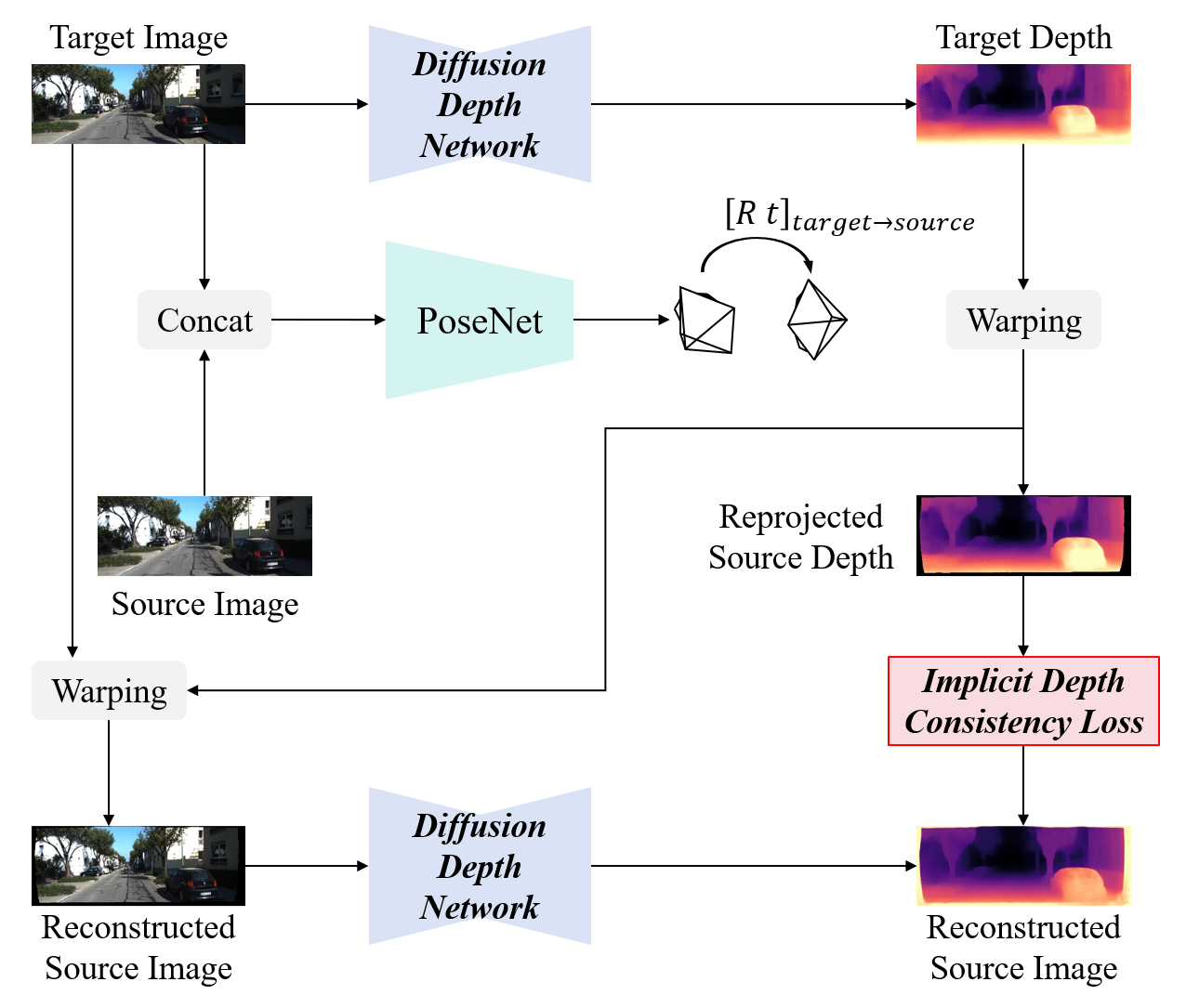
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Read more6/17/2024

0
PGD-VIO: An Accurate Plane-Aided Visual-Inertial Odometry with Graph-Based Drift Suppression
Yidi Zhang, Fulin Tang, Zewen Xu, Yihong Wu, Pengju Ma
Generally, high-level features provide more geometrical information compared to point features, which can be exploited to further constrain motions. Planes are commonplace in man-made environments, offering an active means to reduce drift, due to their extensive spatial and temporal observability. To make full use of planar information, we propose a novel visual-inertial odometry (VIO) using an RGBD camera and an inertial measurement unit (IMU), effectively integrating point and plane features in an extended Kalman filter (EKF) framework. Depth information of point features is leveraged to improve the accuracy of point triangulation, while plane features serve as direct observations added into the state vector. Notably, to benefit long-term navigation,a novel graph-based drift detection strategy is proposed to search overlapping and identical structures in the plane map so that the cumulative drift is suppressed subsequently. The experimental results on two public datasets demonstrate that our system outperforms state-of-the-art methods in localization accuracy and meanwhile generates a compact and consistent plane map, free of expensive global bundle adjustment and loop closing techniques.
Read more7/26/2024

0
DoubleTake: Geometry Guided Depth Estimation
Mohamed Sayed, Filippo Aleotti, Jamie Watson, Zawar Qureshi, Guillermo Garcia-Hernando, Gabriel Brostow, Sara Vicente, Michael Firman
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
Read more7/16/2024