Clustered Policy Decision Ranking
2311.12970
0
0
📶
Abstract
Policies trained via reinforcement learning (RL) are often very complex even for simple tasks. In an episode with n time steps, a policy will make n decisions on actions to take, many of which may appear non-intuitive to the observer. Moreover, it is not clear which of these decisions directly contribute towards achieving the reward and how significant their contribution is. Given a trained policy, we propose a black-box method based on statistical covariance estimation that clusters the states of the environment and ranks each cluster according to the importance of decisions made in its states. We compare our measure against a previous statistical fault localization based ranking procedure.
Create account to get full access
Overview
- Reinforcement learning (RL) policies can be very complex, even for simple tasks
- A policy makes many decisions in an episode, some of which may seem non-intuitive
- It's unclear which decisions directly contribute to the reward and how significant that contribution is
- This paper proposes a black-box method to analyze trained RL policies and understand the importance of different decisions
Plain English Explanation
Reinforcement learning is a powerful technique for training agents to perform tasks and achieve goals. However, the policies (decision-making strategies) learned by these agents can be very intricate, even for relatively simple problems. During an episode, where the agent interacts with the environment over a series of time steps, the policy will make many decisions about which actions to take. Some of these decisions may not seem logical or intuitive to an outside observer.
Moreover, it can be challenging to determine which of these decisions are truly important for achieving the desired reward, and how much each decision contributes to the overall performance. This paper presents a new method to analyze trained RL policies and shed light on this issue. The approach is a "black-box" technique, meaning it can be applied to any trained policy without requiring access to the model's internal workings.
The core idea is to cluster the states of the environment that the agent encounters, and then rank the importance of the decisions made in each cluster. This allows the researchers to identify the most critical decision points that drive the agent's behavior and performance. They compare this approach to a previous statistical method for analyzing RL policies, and demonstrate its effectiveness on several benchmark tasks.
By providing better interpretability and insight into the decision-making of RL agents, this research aims to make these powerful algorithms more transparent and trustworthy, particularly for applications where understanding the agent's reasoning is important. This could have implications for learning efficient and fair policies under uncertainty, dynamic observation policies, and sample-efficient multi-agent reinforcement learning.
Technical Explanation
The authors propose a black-box method to analyze the decision-making of trained reinforcement learning (RL) policies. In a typical RL setting, an agent interacts with an environment over a series of time steps, making decisions about which actions to take in order to maximize some reward signal. The resulting policy, which maps states to actions, can be extremely complex, with many seemingly non-intuitive decisions.
To better understand these policies, the authors develop a statistical approach based on covariance estimation. The key idea is to cluster the states encountered by the agent during an episode, and then rank the importance of the decisions made in each cluster. This allows them to identify the most critical decision points that drive the agent's behavior and performance.
Specifically, the method works as follows:
-
State Clustering: The states encountered by the agent are clustered using a statistical technique like k-means. This partitions the state space into regions where the agent makes similar decisions.
-
Decision Importance Ranking: For each cluster, the authors compute the covariance between the agent's decisions and the eventual return (cumulative reward). This provides a ranking of the importance of the decisions made in that cluster, highlighting the ones that most strongly influence performance.
-
Comparison to Previous Approach: The authors compare their covariance-based ranking to a previous statistical fault localization method for analyzing RL policies. They demonstrate that their approach provides better interpretability and insight into the agent's decision-making process.
The authors evaluate their method on several benchmark RL tasks, including goal-conditioned policies and fast-changing, slow-spiking neural networks. Their results show that the proposed covariance-based analysis can effectively identify the most important decisions made by the agent, providing valuable transparency into the reasoning behind complex RL policies.
Critical Analysis
The authors present a promising approach for analyzing the decision-making of trained reinforcement learning policies. By clustering states and ranking the importance of decisions made in each cluster, their method can shed light on the underlying logic driving an agent's behavior, even for very complex policies.
One potential limitation of the approach is that it relies on statistical techniques like covariance estimation, which may be sensitive to noise or outliers in the data. The authors do not extensively explore the robustness of their method to these types of issues. Additionally, the clustering step could be quite sensitive to the choice of hyperparameters, which may affect the interpretability of the results.
Another area for further research would be to investigate how the proposed analysis could be used to guide the training of more interpretable RL policies. For example, the importance ranking of decisions could potentially be incorporated into the reward function or used to constrain the policy search space. This could lead to more transparent and trustworthy agents, particularly for safety-critical applications.
Overall, this paper presents a valuable contribution to the field of interpretable reinforcement learning. By providing a better understanding of how complex policies make decisions, the authors' black-box analysis method has the potential to increase the transparency and accountability of these powerful algorithms, paving the way for more reliable and responsible AI systems.
Conclusion
This paper introduces a novel method for analyzing the decision-making of trained reinforcement learning policies. By clustering the states encountered by the agent and ranking the importance of the decisions made in each cluster, the approach can shed light on the underlying logic driving an agent's behavior, even for very complex policies.
The authors demonstrate the effectiveness of their covariance-based analysis on several benchmark RL tasks, and compare it to a previous statistical fault localization approach. While the method has some potential limitations, it represents an important step towards greater interpretability and transparency in reinforcement learning.
As AI systems become more capable and ubiquitous, understanding the reasoning behind their decisions will be crucial for building trustworthy and accountable algorithms, particularly in safety-critical domains. The insights gained from this research could have broad implications for the development of more interpretable and fair RL policies, with applications ranging from collaborative decision-making under uncertainty to sample-efficient multi-agent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
Guillermo Infante, David Kuric, Anders Jonsson, Vicenc{c} G'omez, Herke van Hoof
0
0
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
6/4/2024
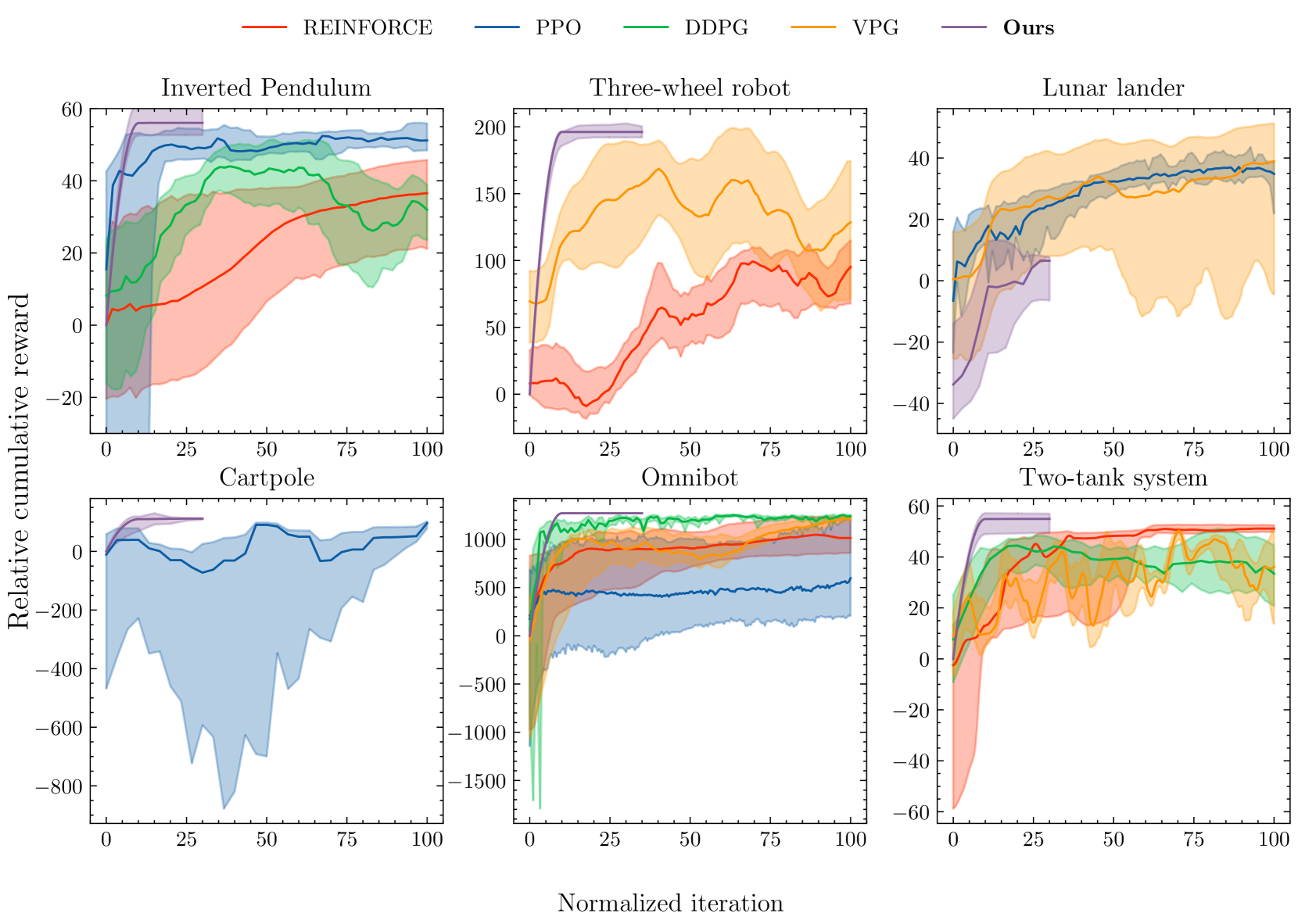
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev
0
0
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Simulation experiments on six problems under five agents, including the benchmarked one, provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
5/30/2024
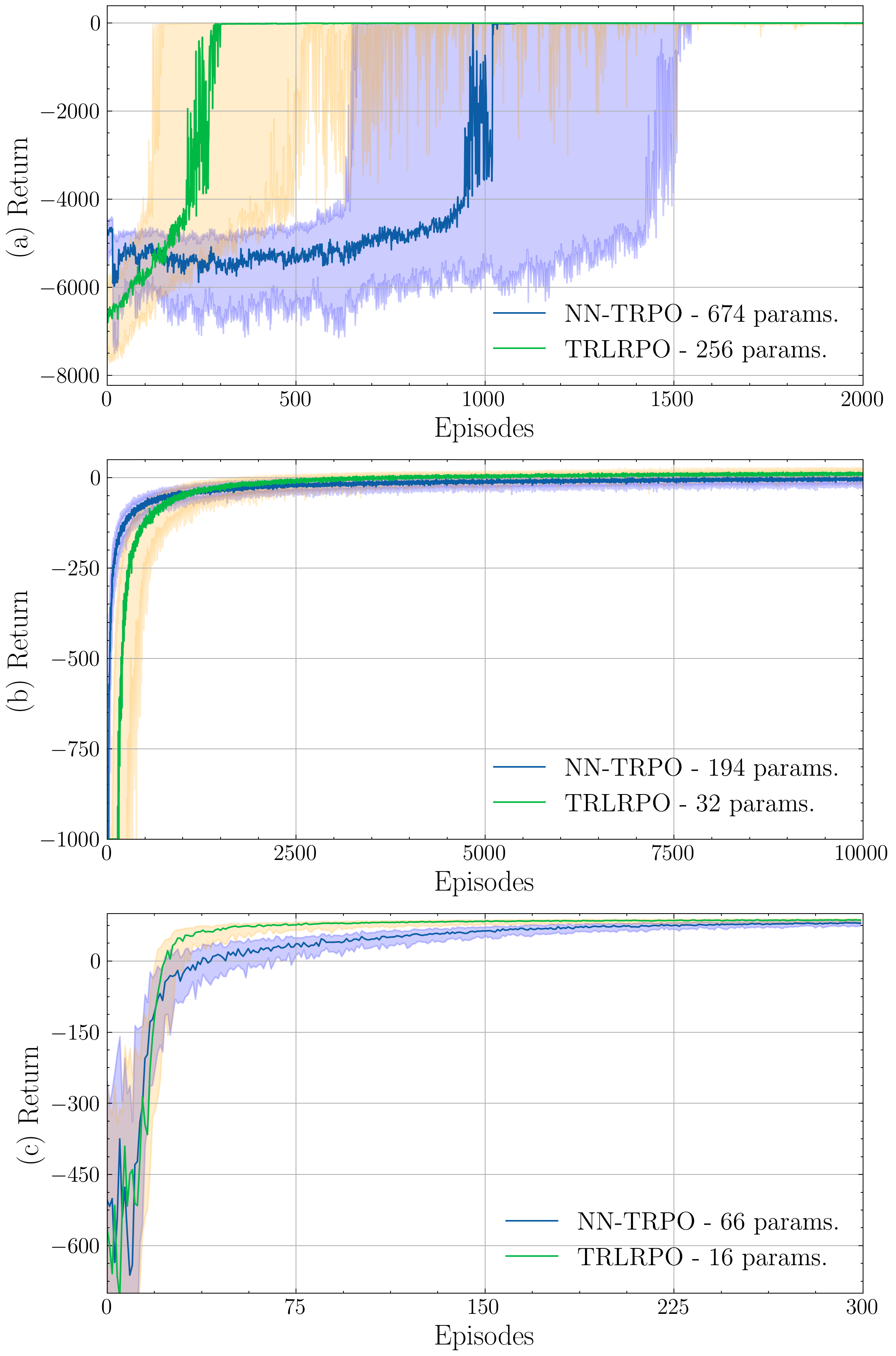
Matrix Low-Rank Trust Region Policy Optimization
Sergio Rozada, Antonio G. Marques
0
0
Most methods in reinforcement learning use a Policy Gradient (PG) approach to learn a parametric stochastic policy that maps states to actions. The standard approach is to implement such a mapping via a neural network (NN) whose parameters are optimized using stochastic gradient descent. However, PG methods are prone to large policy updates that can render learning inefficient. Trust region algorithms, like Trust Region Policy Optimization (TRPO), constrain the policy update step, ensuring monotonic improvements. This paper introduces low-rank matrix-based models as an efficient alternative for estimating the parameters of TRPO algorithms. By gathering the stochastic policy's parameters into a matrix and applying matrix-completion techniques, we promote and enforce low rank. Our numerical studies demonstrate that low-rank matrix-based policy models effectively reduce both computational and sample complexities compared to NN models, while maintaining comparable aggregated rewards.
5/29/2024
📉
PcLast: Discovering Plannable Continuous Latent States
Anurag Koul, Shivakanth Sujit, Shaoru Chen, Ben Evans, Lili Wu, Byron Xu, Rajan Chari, Riashat Islam, Raihan Seraj, Yonathan Efroni, Lekan Molu, Miro Dudik, John Langford, Alex Lamb
0
0
Goal-conditioned planning benefits from learned low-dimensional representations of rich observations. While compact latent representations typically learned from variational autoencoders or inverse dynamics enable goal-conditioned decision making, they ignore state reachability, hampering their performance. In this paper, we learn a representation that associates reachable states together for effective planning and goal-conditioned policy learning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information), and then transform this representation to associate reachable states together in $ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based settings show significant improvements in sampling efficiency. Further, in reward-free settings this approach yields layered state abstractions that enable computationally efficient hierarchical planning for reaching ad hoc goals with zero additional samples.
6/12/2024