Planning Transformer: Long-Horizon Offline Reinforcement Learning with Planning Tokens

0

Sign in to get full access
Overview
- This paper presents a novel offline reinforcement learning model called the Planning Transformer that can learn long-horizon planning policies from offline data.
- The model uses a Transformer architecture with "planning tokens" that allow it to reason about and generate long-term plans.
- Experiments show the Planning Transformer outperforms previous methods on a variety of long-horizon control tasks.
Plain English Explanation
The Planning Transformer is a new machine learning model that can learn how to plan ahead and make decisions for long-term goals, even when it only has access to pre-recorded data (rather than being able to interact with the environment directly).
The key idea is to give the model "planning tokens" that allow it to reason about and generate multi-step plans, rather than just predicting the next action. This enables the model to learn strategies that accomplish long-term objectives, rather than being myopic and only focusing on immediate rewards.
The Planning Transformer is built using a Transformer architecture, which is a type of neural network that is good at processing sequences of information. By training this model on datasets of previous experiences, it can learn patterns and develop planning capabilities without needing to actively explore the environment.
Importantly, the researchers show that the Planning Transformer outperforms previous offline reinforcement learning methods on a variety of challenging long-horizon control tasks. This suggests the planning tokens and Transformer-based approach are effective at enabling long-term reasoning from limited data.
Technical Explanation
The Planning Transformer is an offline reinforcement learning model that uses a Transformer architecture with "planning tokens" to enable long-horizon planning.
The model takes in a sequence of past states, actions, and rewards, and outputs a sequence of future actions that aim to maximize the cumulative long-term reward. The key innovation is the use of planning tokens, which are special tokens the model can attend to and use to reason about and generate multi-step plans.
During training, the model learns to predict the next action as well as a sequence of future planning tokens. These planning tokens are used to condition the model's predictions, allowing it to consider long-term consequences and find more strategic behaviors.
The Planning Transformer is evaluated on a range of long-horizon control tasks, such as navigation and manipulation in simulated environments. The results show it outperforms prior offline RL methods, demonstrating the effectiveness of the planning token approach for learning long-term planning policies from limited data.
Critical Analysis
The Planning Transformer represents an important step towards enabling more capable and strategic decision-making in complex, long-horizon tasks. By leveraging planning tokens and a Transformer architecture, the model is able to reason about long-term consequences and find more effective policies compared to myopic approaches.
However, the paper does not fully explore the limitations of the method. For example, it is unclear how well the model would scale to even more complex environments or tasks that require deeper reasoning and planning. Additionally, the paper does not discuss potential biases or failure modes that could arise from relying solely on offline data for training.
Further research could investigate ways to combine the Planning Transformer with online exploration to handle more diverse and dynamic environments. Exploring ways to make the planning process more interpretable and verifiable would also be valuable for real-world applications.
Overall, the Planning Transformer is a promising approach that demonstrates the potential of Transformer-based models for tackling long-horizon decision-making challenges. However, more research is needed to fully understand its capabilities and limitations.
Conclusion
The Planning Transformer is a novel offline reinforcement learning model that uses a Transformer architecture and "planning tokens" to enable long-horizon planning and decision-making. By training on pre-recorded data, the model can learn strategic behaviors that consider long-term consequences, outperforming previous offline RL methods.
This work represents an important step towards building more capable and versatile AI systems that can plan and make decisions with long-term goals in mind. While there are still limitations to explore, the Planning Transformer demonstrates the potential of Transformer-based models for tackling challenging decision-making problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Planning Transformer: Long-Horizon Offline Reinforcement Learning with Planning Tokens
Joseph Clinton, Robert Lieck
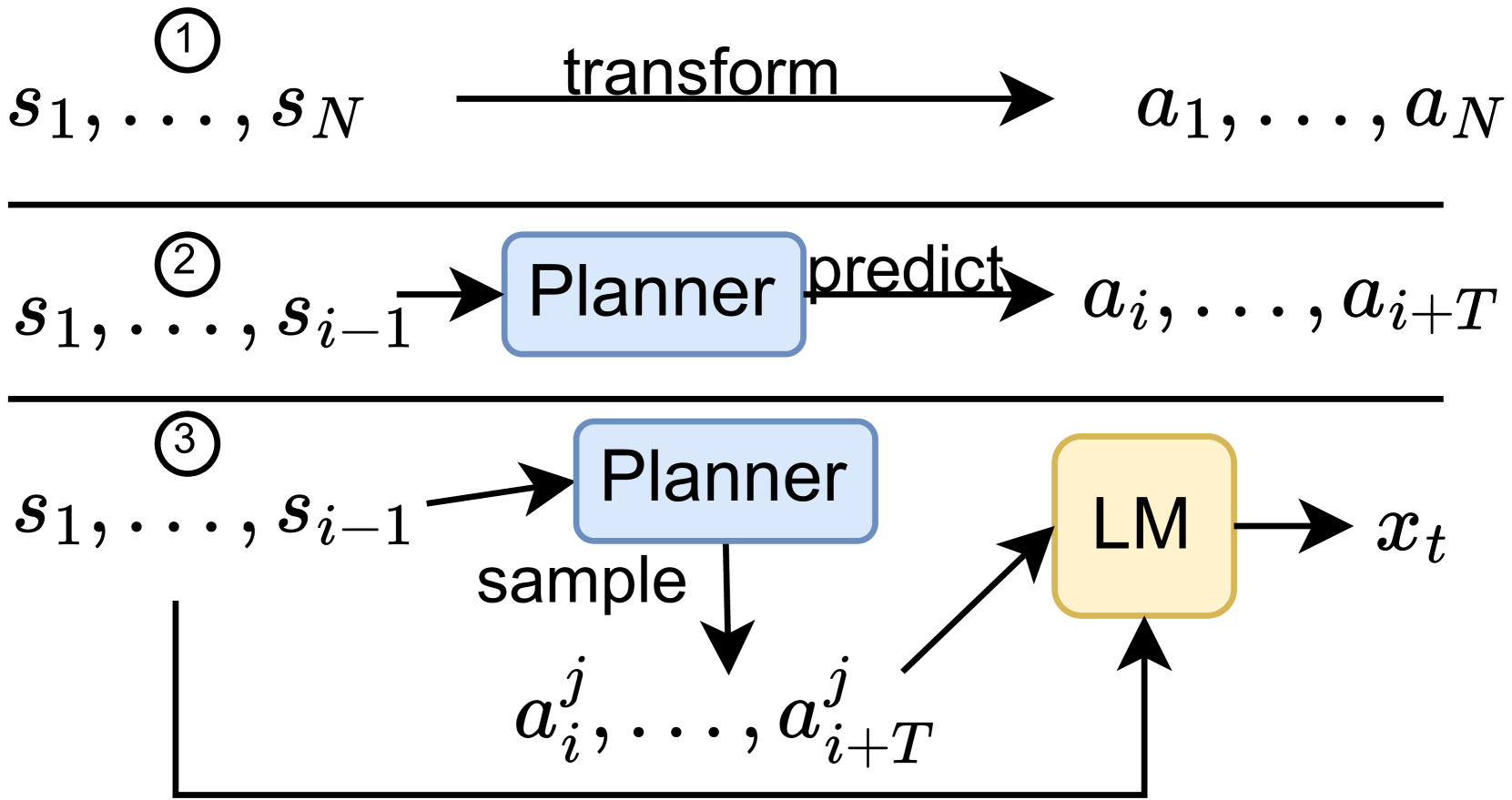
Supervised learning approaches to offline reinforcement learning, particularly those utilizing the Decision Transformer, have shown effectiveness in continuous environments and for sparse rewards. However, they often struggle with long-horizon tasks due to the high compounding error of auto-regressive models. To overcome this limitation, we go beyond next-token prediction and introduce Planning Tokens, which contain high-level, long time-scale information about the agent's future. Predicting dual time-scale tokens at regular intervals enables our model to use these long-horizon Planning Tokens as a form of implicit planning to guide its low-level policy and reduce compounding error. This architectural modification significantly enhances performance on long-horizon tasks, establishing a new state-of-the-art in complex D4RL environments. Additionally, we demonstrate that Planning Tokens improve the interpretability of the model's policy through the interpretable plan visualisations and attention map.
Read more9/17/2024
0
Learning to Plan Long-Term for Language Modeling
Florian Mai, Nathan Cornille, Marie-Francine Moens
Modern language models predict the next token in the sequence by considering the past text through a powerful function such as attention. However, language models have no explicit mechanism that allows them to spend computation time for planning long-distance future text, leading to a suboptimal token prediction. In this paper, we propose a planner that predicts a latent plan for many sentences into the future. By sampling multiple plans at once, we condition the language model on an accurate approximation of the distribution of text continuations, which leads to better next token prediction accuracy. In effect, this allows trading computation time for prediction accuracy.
Read more9/4/2024

0
QT-TDM: Planning with Transformer Dynamics Model and Autoregressive Q-Learning
Mostafa Kotb, Cornelius Weber, Muhammad Burhan Hafez, Stefan Wermter
Inspired by the success of the Transformer architecture in natural language processing and computer vision, we investigate the use of Transformers in Reinforcement Learning (RL), specifically in modeling the environment's dynamics using Transformer Dynamics Models (TDMs). We evaluate the capabilities of TDMs for continuous control in real-time planning scenarios with Model Predictive Control (MPC). While Transformers excel in long-horizon prediction, their tokenization mechanism and autoregressive nature lead to costly planning over long horizons, especially as the environment's dimensionality increases. To alleviate this issue, we use a TDM for short-term planning, and learn an autoregressive discrete Q-function using a separate Q-Transformer (QT) model to estimate a long-term return beyond the short-horizon planning. Our proposed method, QT-TDM, integrates the robust predictive capabilities of Transformers as dynamics models with the efficacy of a model-free Q-Transformer to mitigate the computational burden associated with real-time planning. Experiments in diverse state-based continuous control tasks show that QT-TDM is superior in performance and sample efficiency compared to existing Transformer-based RL models while achieving fast and computationally efficient inference.
Read more7/29/2024
🤯
0
Latent Plan Transformer: Planning as Latent Variable Inference
Deqian Kong, Dehong Xu, Minglu Zhao, Bo Pang, Jianwen Xie, Andrew Lizarraga, Yuhao Huang, Sirui Xie, Ying Nian Wu
In tasks aiming for long-term returns, planning becomes essential. We study generative modeling for planning with datasets repurposed from offline reinforcement learning. Specifically, we identify temporal consistency in the absence of step-wise rewards as one key technical challenge. We introduce the Latent Plan Transformer (LPT), a novel model that leverages a latent space to connect a Transformer-based trajectory generator and the final return. LPT can be learned with maximum likelihood estimation on trajectory-return pairs. In learning, posterior sampling of the latent variable naturally integrates sub-trajectories to form a consistent abstraction despite the finite context. At test time, the latent variable is inferred from an expected return before policy execution, realizing the idea of planning as inference. Our experiments demonstrate that LPT can discover improved decisions from suboptimal trajectories, achieving competitive performance across several benchmarks, including Gym-Mujoco, Franka Kitchen, Maze2D, and Connect Four. It exhibits capabilities in nuanced credit assignments, trajectory stitching, and adaptation to environmental contingencies. These results validate that latent variable inference can be a strong alternative to step-wise reward prompting.
Read more5/29/2024