PLUG: Revisiting Amodal Segmentation with Foundation Model and Hierarchical Focus

0
Sign in to get full access
Overview
- This paper proposes a new method called PLUG (Perceiving Latent Underlying Geometry) for amodal segmentation, which involves inferring the complete shape of an object beyond what is visible in an image.
- PLUG leverages a foundation model, a large pre-trained neural network, and a hierarchical focus mechanism to improve amodal segmentation performance.
- The paper evaluates PLUG on several amodal segmentation benchmarks and shows that it outperforms previous state-of-the-art methods.
Plain English Explanation
PLUG is a new technique for amodal segmentation, which means understanding the complete shape of an object, including the parts that are hidden or occluded. This is an important task in computer vision, as it allows systems to better comprehend the 3D structure of the world from 2D images.
The key innovations in PLUG are:
-
Using a "foundation model" - a large, pre-trained neural network that has learned general visual representations. This gives PLUG a strong starting point for understanding images.
-
Employing a "hierarchical focus" mechanism, which allows the model to attend to different levels of detail in the image as needed, from low-level edges to high-level object shapes.
By combining these two techniques, PLUG is able to outperform previous state-of-the-art methods on standard amodal segmentation benchmarks. This suggests that foundation models and hierarchical attention can be powerful tools for tackling this challenging computer vision problem.
The PLUG paper builds on prior work in amodal segmentation, such as Amodal Ground Truth Completion in the Wild, Sequential Amodal Segmentation via Cumulative Occlusion Learning, and TAO: A Large-scale Benchmark for Tracking Any Object. It also relates to research on ShapeFormer, which explores using transformer models for amodal segmentation.
Technical Explanation
The PLUG method consists of several key components:
-
Foundation Model: PLUG uses a large, pre-trained neural network as its backbone, which has learned general visual representations from a vast amount of data. This provides a strong starting point for understanding the input image.
-
Hierarchical Focus: PLUG employs a hierarchical attention mechanism that allows the model to focus on different levels of detail in the image, from low-level edges to high-level object shapes. This helps the model reason about the complete, amodal structure of objects.
-
Amodal Segmentation Head: Built on top of the foundation model and hierarchical focus, PLUG includes a specialized segmentation head that predicts the amodal masks of objects in the image.
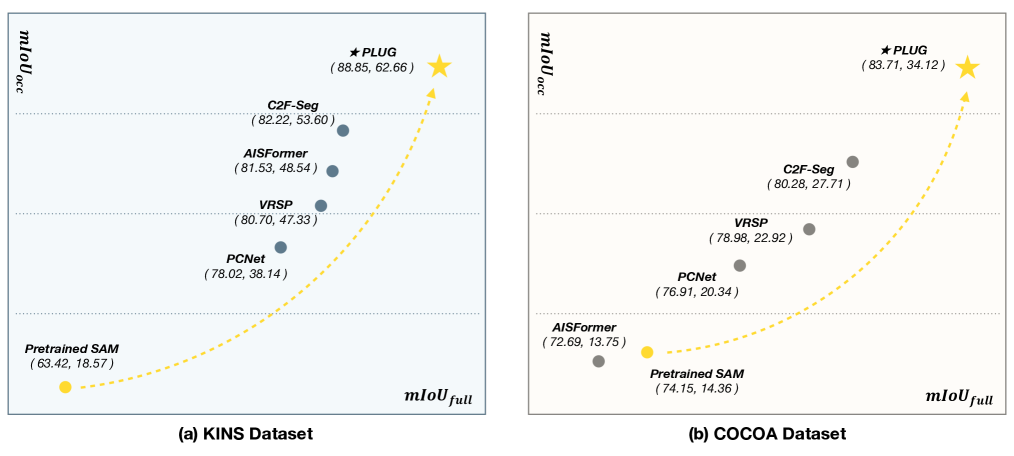
The paper evaluates PLUG on several amodal segmentation benchmarks, including KINS, SOBA, and TAO. The results show that PLUG outperforms previous state-of-the-art methods, demonstrating the effectiveness of its foundation model and hierarchical focus approach.
Critical Analysis
The PLUG paper presents a compelling approach to amodal segmentation, but there are a few potential areas for improvement or further research:
-
Interpretability: While the foundation model and hierarchical focus mechanisms seem to be effective, it would be helpful to better understand how they contribute to the model's amodal reasoning capabilities. Providing more insights into the inner workings of PLUG could make the model more interpretable and open up new research directions.
-
Generalization: The paper focuses on evaluating PLUG on existing amodal segmentation benchmarks. It would be interesting to see how well the method generalizes to real-world scenarios, where the distribution of objects and occlusions may differ from the training data.
-
Computational Efficiency: Large foundation models can be computationally expensive, which may limit the practical deployment of PLUG in certain applications. Exploring more efficient architectures or model compression techniques could help address this concern.
-
Synergy with Other Approaches: The paper mentions that PLUG builds on prior work in amodal segmentation. Investigating how PLUG could be combined with other techniques, such as ShapeFormer or Beyond Pixel-Wise Supervision for Medical Image Segmentation, could lead to further performance improvements and new research directions.
Conclusion
The PLUG method represents an important advancement in amodal segmentation, leveraging foundation models and hierarchical attention to better understand the complete structure of objects in images. By outperforming previous state-of-the-art approaches on standard benchmarks, PLUG demonstrates the potential of these techniques for tackling this challenging computer vision task.
While the paper raises some avenues for further exploration, the core ideas behind PLUG are a significant step forward in enabling machines to perceive the world more like humans do, by inferring the hidden or occluded parts of objects. As research in this area continues, we may see amodal segmentation play an increasingly important role in applications ranging from robotics and autonomous driving to augmented reality and medical imaging.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PLUG: Revisiting Amodal Segmentation with Foundation Model and Hierarchical Focus
Zhaochen Liu, Limeng Qiao, Xiangxiang Chu, Tingting Jiang
Aiming to predict the complete shapes of partially occluded objects, amodal segmentation is an important step towards visual intelligence. With crucial significance, practical prior knowledge derives from sufficient training, while limited amodal annotations pose challenges to achieve better performance. To tackle this problem, utilizing the mighty priors accumulated in the foundation model, we propose the first SAM-based amodal segmentation approach, PLUG. Methodologically, a novel framework with hierarchical focus is presented to better adapt the task characteristics and unleash the potential capabilities of SAM. In the region level, due to the association and division in visible and occluded areas, inmodal and amodal regions are assigned as the focuses of distinct branches to avoid mutual disturbance. In the point level, we introduce the concept of uncertainty to explicitly assist the model in identifying and focusing on ambiguous points. Guided by the uncertainty map, a computation-economic point loss is applied to improve the accuracy of predicted boundaries. Experiments are conducted on several prominent datasets, and the results show that our proposed method outperforms existing methods with large margins. Even with fewer total parameters, our method still exhibits remarkable advantages.
Read more6/4/2024

0
Amodal Ground Truth and Completion in the Wild
Guanqi Zhan, Chuanxia Zheng, Weidi Xie, Andrew Zisserman
This paper studies amodal image segmentation: predicting entire object segmentation masks including both visible and invisible (occluded) parts. In previous work, the amodal segmentation ground truth on real images is usually predicted by manual annotaton and thus is subjective. In contrast, we use 3D data to establish an automatic pipeline to determine authentic ground truth amodal masks for partially occluded objects in real images. This pipeline is used to construct an amodal completion evaluation benchmark, MP3D-Amodal, consisting of a variety of object categories and labels. To better handle the amodal completion task in the wild, we explore two architecture variants: a two-stage model that first infers the occluder, followed by amodal mask completion; and a one-stage model that exploits the representation power of Stable Diffusion for amodal segmentation across many categories. Without bells and whistles, our method achieves a new state-of-the-art performance on Amodal segmentation datasets that cover a large variety of objects, including COCOA and our new MP3D-Amodal dataset. The dataset, model, and code are available at https://www.robots.ox.ac.uk/~vgg/research/amodal/.
Read more4/30/2024

0
Sequential Amodal Segmentation via Cumulative Occlusion Learning
Jiayang Ao, Qiuhong Ke, Krista A. Ehinger
To fully understand the 3D context of a single image, a visual system must be able to segment both the visible and occluded regions of objects, while discerning their occlusion order. Ideally, the system should be able to handle any object and not be restricted to segmenting a limited set of object classes, especially in robotic applications. Addressing this need, we introduce a diffusion model with cumulative occlusion learning designed for sequential amodal segmentation of objects with uncertain categories. This model iteratively refines the prediction using the cumulative mask strategy during diffusion, effectively capturing the uncertainty of invisible regions and adeptly reproducing the complex distribution of shapes and occlusion orders of occluded objects. It is akin to the human capability for amodal perception, i.e., to decipher the spatial ordering among objects and accurately predict complete contours for occluded objects in densely layered visual scenes. Experimental results across three amodal datasets show that our method outperforms established baselines.
Read more5/10/2024

0
TAO-Amodal: A Benchmark for Tracking Any Object Amodally
Cheng-Yen Hsieh, Kaihua Chen, Achal Dave, Tarasha Khurana, Deva Ramanan
Amodal perception, the ability to comprehend complete object structures from partial visibility, is a fundamental skill, even for infants. Its significance extends to applications like autonomous driving, where a clear understanding of heavily occluded objects is essential. However, modern detection and tracking algorithms often overlook this critical capability, perhaps due to the prevalence of textit{modal} annotations in most benchmarks. To address the scarcity of amodal benchmarks, we introduce TAO-Amodal, featuring 833 diverse categories in thousands of video sequences. Our dataset includes textit{amodal} and modal bounding boxes for visible and partially or fully occluded objects, including those that are partially out of the camera frame. We investigate the current lay of the land in both amodal tracking and detection by benchmarking state-of-the-art modal trackers and amodal segmentation methods. We find that existing methods, even when adapted for amodal tracking, struggle to detect and track objects under heavy occlusion. To mitigate this, we explore simple finetuning schemes that can increase the amodal tracking and detection metrics of occluded objects by 2.1% and 3.3%.
Read more4/4/2024