ShapeFormer: Shape Prior Visible-to-Amodal Transformer-based Amodal Instance Segmentation

0

Sign in to get full access
Overview
- This paper presents ShapeFormer, a transformer-based model for amodal instance segmentation that leverages shape priors.
- Amodal instance segmentation is the task of detecting and segmenting objects in an image, including parts that may be occluded or outside the visible frame.
- ShapeFormer uses a transformer-based architecture to predict visible-to-amodal object masks, incorporating shape priors to improve performance on occluded or partially visible objects.
Plain English Explanation
ShapeFormer is a new artificial intelligence (AI) model that can identify and outline objects in images, even if parts of those objects are hidden or outside the camera's view. This is called "amodal instance segmentation."
The key innovation in ShapeFormer is that it uses information about the typical shapes of different objects to help it recognize them when they are only partially visible. For example, if the model sees the top half of a car, it can use its knowledge of what a full car shape looks like to infer the missing bottom half.
This shape-aware approach allows ShapeFormer to do a better job of detecting and outlining objects compared to previous amodal segmentation models, especially for objects that are obstructed or only partially shown in the image.
Technical Explanation
ShapeFormer is a transformer-based model for amodal instance segmentation that incorporates shape priors to improve performance on occluded or partially visible objects. The model takes a visible image as input and predicts a corresponding amodal instance segmentation mask, which includes both the visible and occluded parts of each object.
The key components of ShapeFormer include:
- A transformer encoder that encodes the input image
- A transformer decoder that predicts the amodal segmentation mask for each instance
- A shape prior module that encodes shape information and integrates it into the decoder
The shape prior module learns representations of common object shapes and uses these to guide the decoder in hallucinating the occluded parts of each object. This shape-aware approach allows ShapeFormer to outperform previous amodal segmentation methods, particularly on challenging cases with heavy occlusion.
Critical Analysis
The TAO benchmark for amodal segmentation provides a valuable testbed for evaluating the performance of ShapeFormer and other related models. While ShapeFormer demonstrates state-of-the-art results on this benchmark, the paper acknowledges that there is still significant room for improvement, especially for highly occluded objects.
One potential limitation of the current approach is that the shape prior module is based on a predefined set of shape templates. An interesting avenue for future research could be to explore more flexible and generative shape representations, potentially drawing inspiration from mixed-query transformer models that can handle diverse and complex shapes.
Additionally, the authors note that ShapeFormer relies on strong supervision during training, with ground truth amodal instance segmentation masks required. Developing bootstrapping techniques to learn amodal segmentation from weaker forms of supervision could further improve the practicality and scalability of this approach.
Conclusion
ShapeFormer represents an important step forward in amodal instance segmentation by leveraging shape priors to better handle occluded and partially visible objects. The incorporation of shape information allows the model to make more accurate predictions, particularly in challenging scenarios.
While the current results are promising, there remains significant potential for further advancements in this area. Continued research into more flexible shape representations, as well as techniques for learning amodal segmentation from limited supervision, could lead to even more robust and capable amodal instance segmentation models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ShapeFormer: Shape Prior Visible-to-Amodal Transformer-based Amodal Instance Segmentation
Minh Tran, Winston Bounsavy, Khoa Vo, Anh Nguyen, Tri Nguyen, Ngan Le
Amodal Instance Segmentation (AIS) presents a challenging task as it involves predicting both visible and occluded parts of objects within images. Existing AIS methods rely on a bidirectional approach, encompassing both the transition from amodal features to visible features (amodal-to-visible) and from visible features to amodal features (visible-to-amodal). Our observation shows that the utilization of amodal features through the amodal-to-visible can confuse the visible features due to the extra information of occluded/hidden segments not presented in visible display. Consequently, this compromised quality of visible features during the subsequent visible-to-amodal transition. To tackle this issue, we introduce ShapeFormer, a decoupled Transformer-based model with a visible-to-amodal transition. It facilitates the explicit relationship between output segmentations and avoids the need for amodal-to-visible transitions. ShapeFormer comprises three key modules: (i) Visible-Occluding Mask Head for predicting visible segmentation with occlusion awareness, (ii) Shape-Prior Amodal Mask Head for predicting amodal and occluded masks, and (iii) Category-Specific Shape Prior Retriever aims to provide shape prior knowledge. Comprehensive experiments and extensive ablation studies across various AIS benchmarks demonstrate the effectiveness of our ShapeFormer. The code is available at: https://github.com/UARK-AICV/ShapeFormer
Read more4/16/2024

0
Hyper-Transformer for Amodal Completion
Jianxiong Gao, Xuelin Qian, Longfei Liang, Junwei Han, Yanwei Fu
Amodal object completion is a complex task that involves predicting the invisible parts of an object based on visible segments and background information. Learning shape priors is crucial for effective amodal completion, but traditional methods often rely on two-stage processes or additional information, leading to inefficiencies and potential error accumulation. To address these shortcomings, we introduce a novel framework named the Hyper-Transformer Amodal Network (H-TAN). This framework utilizes a hyper transformer equipped with a dynamic convolution head to directly learn shape priors and accurately predict amodal masks. Specifically, H-TAN uses a dual-branch structure to extract multi-scale features from both images and masks. The multi-scale features from the image branch guide the hyper transformer in learning shape priors and in generating the weights for dynamic convolution tailored to each instance. The dynamic convolution head then uses the features from the mask branch to predict precise amodal masks. We extensively evaluate our model on three benchmark datasets: KINS, COCOA-cls, and D2SA, where H-TAN demonstrated superior performance compared to existing methods. Additional experiments validate the effectiveness and stability of the novel hyper transformer in our framework.
Read more5/31/2024
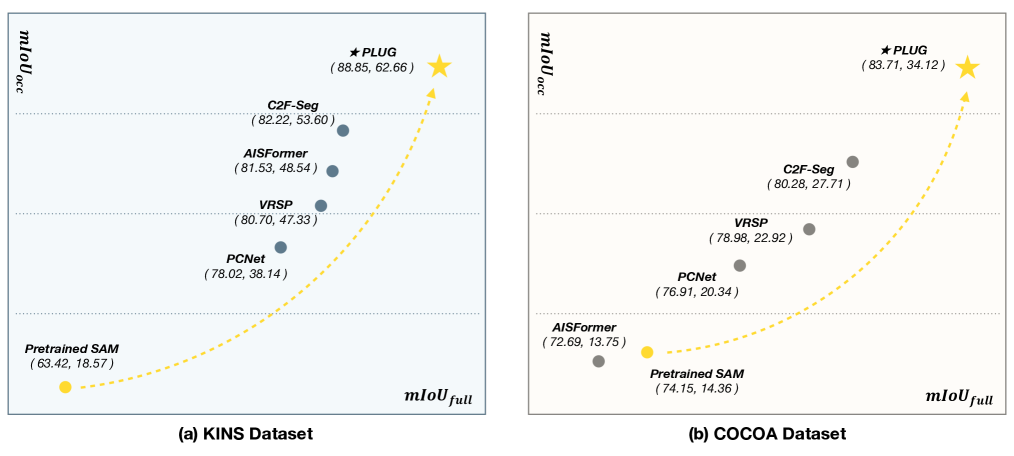
0
PLUG: Revisiting Amodal Segmentation with Foundation Model and Hierarchical Focus
Zhaochen Liu, Limeng Qiao, Xiangxiang Chu, Tingting Jiang
Aiming to predict the complete shapes of partially occluded objects, amodal segmentation is an important step towards visual intelligence. With crucial significance, practical prior knowledge derives from sufficient training, while limited amodal annotations pose challenges to achieve better performance. To tackle this problem, utilizing the mighty priors accumulated in the foundation model, we propose the first SAM-based amodal segmentation approach, PLUG. Methodologically, a novel framework with hierarchical focus is presented to better adapt the task characteristics and unleash the potential capabilities of SAM. In the region level, due to the association and division in visible and occluded areas, inmodal and amodal regions are assigned as the focuses of distinct branches to avoid mutual disturbance. In the point level, we introduce the concept of uncertainty to explicitly assist the model in identifying and focusing on ambiguous points. Guided by the uncertainty map, a computation-economic point loss is applied to improve the accuracy of predicted boundaries. Experiments are conducted on several prominent datasets, and the results show that our proposed method outperforms existing methods with large margins. Even with fewer total parameters, our method still exhibits remarkable advantages.
Read more6/4/2024
🏷️
0
ShapeFormer: Shapelet Transformer for Multivariate Time Series Classification
Xuan-May Le, Ling Luo, Uwe Aickelin, Minh-Tuan Tran
Multivariate time series classification (MTSC) has attracted significant research attention due to its diverse real-world applications. Recently, exploiting transformers for MTSC has achieved state-of-the-art performance. However, existing methods focus on generic features, providing a comprehensive understanding of data, but they ignore class-specific features crucial for learning the representative characteristics of each class. This leads to poor performance in the case of imbalanced datasets or datasets with similar overall patterns but differing in minor class-specific details. In this paper, we propose a novel Shapelet Transformer (ShapeFormer), which comprises class-specific and generic transformer modules to capture both of these features. In the class-specific module, we introduce the discovery method to extract the discriminative subsequences of each class (i.e. shapelets) from the training set. We then propose a Shapelet Filter to learn the difference features between these shapelets and the input time series. We found that the difference feature for each shapelet contains important class-specific features, as it shows a significant distinction between its class and others. In the generic module, convolution filters are used to extract generic features that contain information to distinguish among all classes. For each module, we employ the transformer encoder to capture the correlation between their features. As a result, the combination of two transformer modules allows our model to exploit the power of both types of features, thereby enhancing the classification performance. Our experiments on 30 UEA MTSC datasets demonstrate that ShapeFormer has achieved the highest accuracy ranking compared to state-of-the-art methods. The code is available at https://github.com/xuanmay2701/shapeformer.
Read more5/24/2024