Pluralistic Salient Object Detection

0

Sign in to get full access
Overview
- Pluralistic Salient Object Detection is a research paper that explores a novel approach to detecting salient objects in images.
- The key focus is on developing a system that can handle the pluralistic nature of saliency, where different observers may perceive different objects as salient in the same image.
- The paper proposes a new architecture and training strategy to address this challenge, with the goal of improving the quality and robustness of salient object detection.
Plain English Explanation
The researchers behind this paper recognized that traditional salient object detection methods often struggle to capture the nuanced and subjective nature of how people perceive saliency in images. Different people may look at the same image and focus on different objects as being the most interesting or important. To address this, the researchers developed a new approach called "Pluralistic Salient Object Detection."
The key idea is to train the system to learn multiple plausible saliency maps for a single image, rather than just a single "correct" saliency map. This allows the system to capture the inherent diversity in how humans perceive saliency. By learning this pluralistic representation of saliency, the researchers hoped to create a more robust and reliable salient object detection system.
The technical details involve designing a new neural network architecture and training strategy to enable this pluralistic approach. The system needs to learn to generate multiple distinct saliency maps for each input image, rather than just a single saliency map. This added complexity allows the system to better reflect the subjective and diverse nature of human saliency perception.
Overall, the goal of this research is to advance the state-of-the-art in salient object detection, making it more aligned with how humans actually perceive and focus on important elements in images. This could have applications in areas like image editing, video summarization, and visual attention modeling.
Technical Explanation
The core innovation in this paper is the introduction of a Pluralistic Salient Object Detection framework. Rather than training a model to predict a single saliency map for an input image, the researchers developed an approach that learns to generate multiple plausible saliency maps for each image.
This is achieved through a new network architecture that consists of a Saliency Generator and a Saliency Discriminator. The Saliency Generator is tasked with producing a diverse set of saliency maps, while the Discriminator is trained to evaluate the quality and realism of these generated saliency maps.
The training process involves a two-stage adversarial learning strategy. First, the Saliency Generator is trained to produce diverse saliency maps that fool the Discriminator. Then, the Discriminator is trained to better distinguish between the generated saliency maps and ground truth saliency maps. This iterative process encourages the Generator to learn a pluralistic representation of saliency.
The researchers also introduced a new ,[object Object], to guide the training of the Saliency Generator. This loss function evaluates the generated saliency maps not only on their similarity to ground truth, but also on their diversity and perceptual quality.
Through extensive experiments on benchmark salient object detection datasets, the researchers demonstrated that their Pluralistic Salient Object Detection approach outperforms state-of-the-art single-saliency-map models in terms of both quantitative metrics and human evaluation.
Critical Analysis
The key strength of the Pluralistic Salient Object Detection approach is its ability to capture the inherent subjectivity and diversity in human saliency perception. By learning to generate multiple plausible saliency maps for each image, the system can better reflect the nuanced and pluralistic nature of how people focus on and perceive important elements in images.
However, one potential limitation of this approach is the increased complexity and computational cost associated with generating and evaluating multiple saliency maps per image. The authors note that this added complexity could make the system less practical for real-time or resource-constrained applications.
Additionally, while the Mask Quality (MQ) loss function helps to guide the training of the Saliency Generator, there may be room for further research into more effective ways of evaluating the quality and diversity of the generated saliency maps. The authors acknowledge that their current approach could still be improved in terms of producing saliency maps that are truly perceptually aligned with human judgments.
Future work could also explore ways to leverage unlabeled data or alternative training strategies to further boost the performance and robustness of the Pluralistic Salient Object Detection system. Additionally, extending the approach to handle salient object detection in other modalities, such as video or multi-modal data, could further expand the practical applicability of this research.
Conclusion
The Pluralistic Salient Object Detection paper presents a novel and promising approach to salient object detection that aims to better capture the subjective and diverse nature of human saliency perception. By learning to generate multiple plausible saliency maps per image, the system demonstrates improved performance over traditional single-saliency-map models.
This research advances the state-of-the-art in salient object detection and opens up new avenues for exploring the complex and pluralistic nature of visual attention. While there are still some limitations to address, the core ideas and techniques introduced in this paper have the potential to significantly impact applications that rely on robust and humanlike saliency detection, such as image editing, video summarization, and visual attention modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pluralistic Salient Object Detection
Xuelu Feng, Yunsheng Li, Dongdong Chen, Chunming Qiao, Junsong Yuan, Lu Yuan, Gang Hua
We introduce pluralistic salient object detection (PSOD), a novel task aimed at generating multiple plausible salient segmentation results for a given input image. Unlike conventional SOD methods that produce a single segmentation mask for salient objects, this new setting recognizes the inherent complexity of real-world images, comprising multiple objects, and the ambiguity in defining salient objects due to different user intentions. To study this task, we present two new SOD datasets DUTS-MM and DUS-MQ, along with newly designed evaluation metrics. DUTS-MM builds upon the DUTS dataset but enriches the ground-truth mask annotations from three aspects which 1) improves the mask quality especially for boundary and fine-grained structures; 2) alleviates the annotation inconsistency issue; and 3) provides multiple ground-truth masks for images with saliency ambiguity. DUTS-MQ consists of approximately 100K image-mask pairs with human-annotated preference scores, enabling the learning of real human preferences in measuring mask quality. Building upon these two datasets, we propose a simple yet effective pluralistic SOD baseline based on a Mixture-of-Experts (MOE) design. Equipped with two prediction heads, it simultaneously predicts multiple masks using different query prompts and predicts human preference scores for each mask candidate. Extensive experiments and analyses underscore the significance of our proposed datasets and affirm the effectiveness of our PSOD framework.
Read more9/5/2024
🤷
0
Unified Unsupervised Salient Object Detection via Knowledge Transfer
Yao Yuan, Wutao Liu, Pan Gao, Qun Dai, Jie Qin
Recently, unsupervised salient object detection (USOD) has gained increasing attention due to its annotation-free nature. However, current methods mainly focus on specific tasks such as RGB and RGB-D, neglecting the potential for task migration. In this paper, we propose a unified USOD framework for generic USOD tasks. Firstly, we propose a Progressive Curriculum Learning-based Saliency Distilling (PCL-SD) mechanism to extract saliency cues from a pre-trained deep network. This mechanism starts with easy samples and progressively moves towards harder ones, to avoid initial interference caused by hard samples. Afterwards, the obtained saliency cues are utilized to train a saliency detector, and we employ a Self-rectify Pseudo-label Refinement (SPR) mechanism to improve the quality of pseudo-labels. Finally, an adapter-tuning method is devised to transfer the acquired saliency knowledge, leveraging shared knowledge to attain superior transferring performance on the target tasks. Extensive experiments on five representative SOD tasks confirm the effectiveness and feasibility of our proposed method. Code and supplement materials are available at https://github.com/I2-Multimedia-Lab/A2S-v3.
Read more7/16/2024
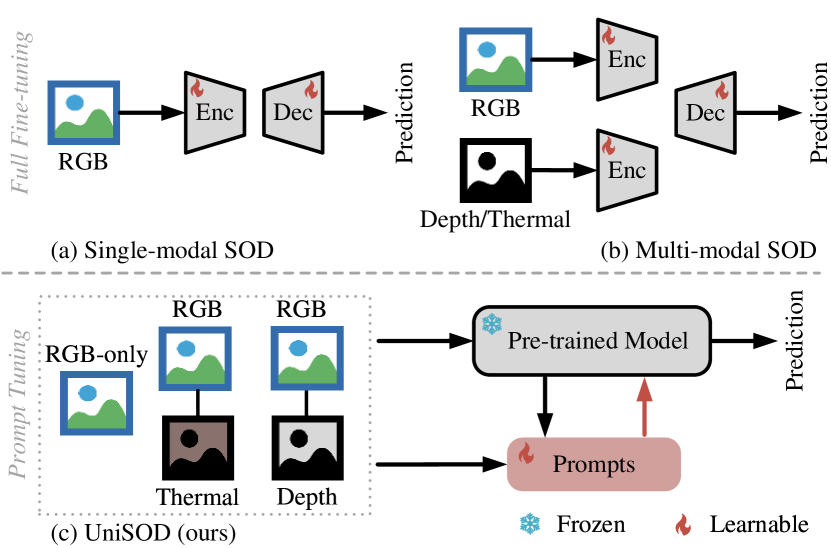
0
Unified-modal Salient Object Detection via Adaptive Prompt Learning
Kunpeng Wang, Chenglong Li, Zhengzheng Tu, Zhengyi Liu, Bin Luo
Existing single-modal and multi-modal salient object detection (SOD) methods focus on designing specific architectures tailored for their respective tasks. However, developing completely different models for different tasks leads to labor and time consumption, as well as high computational and practical deployment costs. In this paper, we attempt to address both single-modal and multi-modal SOD in a unified framework called UniSOD, which fully exploits the overlapping prior knowledge between different tasks. Nevertheless, assigning appropriate strategies to modality variable inputs is challenging. To this end, UniSOD learns modality-aware prompts with task-specific hints through adaptive prompt learning, which are plugged into the proposed pre-trained baseline SOD model to handle corresponding tasks, while only requiring few learnable parameters compared to training the entire model. Each modality-aware prompt is generated from a switchable prompt generation block, which adaptively performs structural switching based on single-modal and multi-modal inputs without human intervention. Through end-to-end joint training, UniSOD achieves overall performance improvement on 14 benchmark datasets for RGB, RGB-D, and RGB-T SOD, which demonstrates that our method effectively and efficiently unifies single-modal and multi-modal SOD tasks.The code and results are available at https://github.com/Angknpng/UniSOD.
Read more6/6/2024

0
SOOD++: Leveraging Unlabeled Data to Boost Oriented Object Detection
Dingkang Liang, Wei Hua, Chunsheng Shi, Zhikang Zou, Xiaoqing Ye, Xiang Bai
Semi-supervised object detection (SSOD), leveraging unlabeled data to boost object detectors, has become a hot topic recently. However, existing SSOD approaches mainly focus on horizontal objects, leaving multi-oriented objects common in aerial images unexplored. At the same time, the annotation cost of multi-oriented objects is significantly higher than that of their horizontal counterparts. Therefore, in this paper, we propose a simple yet effective Semi-supervised Oriented Object Detection method termed SOOD++. Specifically, we observe that objects from aerial images are usually arbitrary orientations, small scales, and aggregation, which inspires the following core designs: a Simple Instance-aware Dense Sampling (SIDS) strategy is used to generate comprehensive dense pseudo-labels; the Geometry-aware Adaptive Weighting (GAW) loss dynamically modulates the importance of each pair between pseudo-label and corresponding prediction by leveraging the intricate geometric information of aerial objects; we treat aerial images as global layouts and explicitly build the many-to-many relationship between the sets of pseudo-labels and predictions via the proposed Noise-driven Global Consistency (NGC). Extensive experiments conducted on various multi-oriented object datasets under various labeled settings demonstrate the effectiveness of our method. For example, on the DOTA-V1.5 benchmark, the proposed method outperforms previous state-of-the-art (SOTA) by a large margin (+2.92, +2.39, and +2.57 mAP under 10%, 20%, and 30% labeled data settings, respectively) with single-scale training and testing. More importantly, it still improves upon a strong supervised baseline with 70.66 mAP, trained using the full DOTA-V1.5 train-val set, by +1.82 mAP, resulting in a 72.48 mAP, pushing the new state-of-the-art. The code will be made available.
Read more7/2/2024