Unified Unsupervised Salient Object Detection via Knowledge Transfer

0
🤷
Sign in to get full access
Overview
- Unsupervised salient object detection (USOD) is gaining attention due to its ability to detect important objects without manual labeling.
- Current USOD methods focus on specific tasks like RGB and RGB-D, but neglect the potential for task migration.
- This paper proposes a unified USOD framework that can be applied to a variety of USOD tasks.
Plain English Explanation
The paper describes a new way to detect important objects in images without the need for manual labeling. Current methods for this task, known as unsupervised salient object detection (USOD), tend to focus on specific types of images, like those with color information (RGB) or depth information (RGB-D). However, the researchers wanted to create a more flexible method that could be applied to a wider range of USOD tasks.
The key idea is to use a progressive curriculum learning approach to extract saliency cues from a pre-trained neural network. This starts with easy examples and gradually moves to more difficult ones, to avoid the network getting confused by the hard examples early on. The saliency cues are then used to train a saliency detection model, and the researchers employ a self-rectifying pseudo-label refinement technique to improve the quality of the automatically generated training labels.
Finally, the researchers devise an adapter-tuning method to transfer the learned saliency knowledge to new USOD tasks, leveraging the shared knowledge to achieve better performance on the target tasks.
Technical Explanation
The paper proposes a unified unsupervised salient object detection (USOD) framework that can be applied to a variety of USOD tasks. The key components are:
-
Progressive Curriculum Learning-based Saliency Distilling (PCL-SD): This mechanism extracts saliency cues from a pre-trained deep network. It starts with easy samples and progressively moves towards harder ones, to avoid initial interference caused by hard samples.
-
Self-rectify Pseudo-label Refinement (SPR): The obtained saliency cues are used to train a saliency detector, and the SPR mechanism is employed to improve the quality of the automatically generated pseudo-labels.
-
Adapter-tuning for Transfer Learning: An adapter-tuning method is devised to transfer the acquired saliency knowledge to new USOD tasks, leveraging the shared knowledge to attain superior transferring performance.
The researchers evaluate their proposed framework on five representative USOD tasks, including 3D object detection for autonomous vehicles, and confirm its effectiveness and feasibility.
Critical Analysis
The paper presents a comprehensive USOD framework that addresses some key limitations of existing methods. The progressive curriculum learning approach and the self-rectifying pseudo-label refinement mechanism are novel and seem to offer significant improvements in saliency detection performance.
However, the paper does not provide a detailed analysis of the computational complexity or runtime efficiency of the proposed methods. This information would be helpful for evaluating the practical applicability of the framework, especially for real-time or resource-constrained applications.
Additionally, the paper could have explored the robustness of the framework to different types of input data, such as low-quality or noisy images, to assess its versatility and generalization capabilities.
Conclusion
This paper introduces a unified unsupervised salient object detection (USOD) framework that can be applied to a variety of USOD tasks. The key innovations include a progressive curriculum learning-based saliency distilling mechanism, a self-rectifying pseudo-label refinement technique, and an adapter-tuning method for effective transfer learning.
The experimental results demonstrate the effectiveness and feasibility of the proposed framework, suggesting it could be a valuable tool for a wide range of computer vision applications that require salient object detection without manual labeling. The framework's ability to leverage shared knowledge and adapt to new tasks also highlights its potential for improving the efficiency and scalability of USOD systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Unified Unsupervised Salient Object Detection via Knowledge Transfer
Yao Yuan, Wutao Liu, Pan Gao, Qun Dai, Jie Qin
Recently, unsupervised salient object detection (USOD) has gained increasing attention due to its annotation-free nature. However, current methods mainly focus on specific tasks such as RGB and RGB-D, neglecting the potential for task migration. In this paper, we propose a unified USOD framework for generic USOD tasks. Firstly, we propose a Progressive Curriculum Learning-based Saliency Distilling (PCL-SD) mechanism to extract saliency cues from a pre-trained deep network. This mechanism starts with easy samples and progressively moves towards harder ones, to avoid initial interference caused by hard samples. Afterwards, the obtained saliency cues are utilized to train a saliency detector, and we employ a Self-rectify Pseudo-label Refinement (SPR) mechanism to improve the quality of pseudo-labels. Finally, an adapter-tuning method is devised to transfer the acquired saliency knowledge, leveraging shared knowledge to attain superior transferring performance on the target tasks. Extensive experiments on five representative SOD tasks confirm the effectiveness and feasibility of our proposed method. Code and supplement materials are available at https://github.com/I2-Multimedia-Lab/A2S-v3.
Read more7/16/2024
0
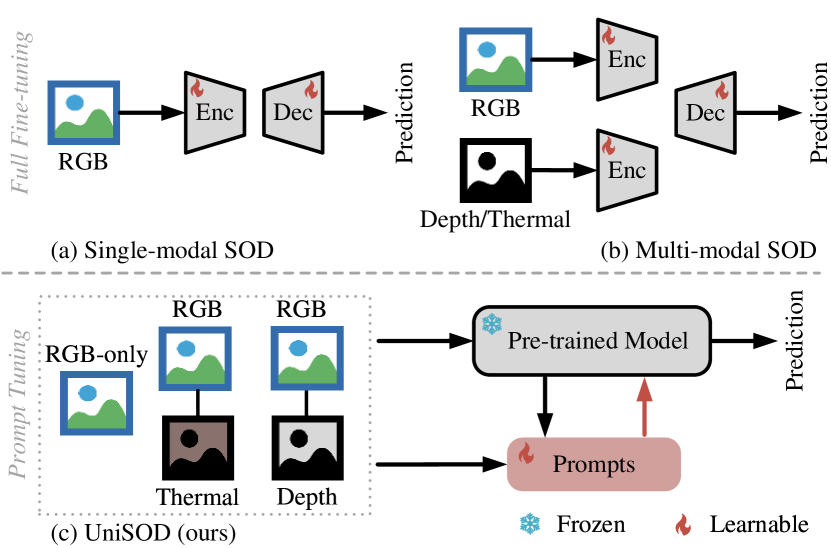
Unified-modal Salient Object Detection via Adaptive Prompt Learning
Kunpeng Wang, Chenglong Li, Zhengzheng Tu, Zhengyi Liu, Bin Luo
Existing single-modal and multi-modal salient object detection (SOD) methods focus on designing specific architectures tailored for their respective tasks. However, developing completely different models for different tasks leads to labor and time consumption, as well as high computational and practical deployment costs. In this paper, we attempt to address both single-modal and multi-modal SOD in a unified framework called UniSOD, which fully exploits the overlapping prior knowledge between different tasks. Nevertheless, assigning appropriate strategies to modality variable inputs is challenging. To this end, UniSOD learns modality-aware prompts with task-specific hints through adaptive prompt learning, which are plugged into the proposed pre-trained baseline SOD model to handle corresponding tasks, while only requiring few learnable parameters compared to training the entire model. Each modality-aware prompt is generated from a switchable prompt generation block, which adaptively performs structural switching based on single-modal and multi-modal inputs without human intervention. Through end-to-end joint training, UniSOD achieves overall performance improvement on 14 benchmark datasets for RGB, RGB-D, and RGB-T SOD, which demonstrates that our method effectively and efficiently unifies single-modal and multi-modal SOD tasks.The code and results are available at https://github.com/Angknpng/UniSOD.
Read more6/6/2024

0
Pluralistic Salient Object Detection
Xuelu Feng, Yunsheng Li, Dongdong Chen, Chunming Qiao, Junsong Yuan, Lu Yuan, Gang Hua
We introduce pluralistic salient object detection (PSOD), a novel task aimed at generating multiple plausible salient segmentation results for a given input image. Unlike conventional SOD methods that produce a single segmentation mask for salient objects, this new setting recognizes the inherent complexity of real-world images, comprising multiple objects, and the ambiguity in defining salient objects due to different user intentions. To study this task, we present two new SOD datasets DUTS-MM and DUS-MQ, along with newly designed evaluation metrics. DUTS-MM builds upon the DUTS dataset but enriches the ground-truth mask annotations from three aspects which 1) improves the mask quality especially for boundary and fine-grained structures; 2) alleviates the annotation inconsistency issue; and 3) provides multiple ground-truth masks for images with saliency ambiguity. DUTS-MQ consists of approximately 100K image-mask pairs with human-annotated preference scores, enabling the learning of real human preferences in measuring mask quality. Building upon these two datasets, we propose a simple yet effective pluralistic SOD baseline based on a Mixture-of-Experts (MOE) design. Equipped with two prediction heads, it simultaneously predicts multiple masks using different query prompts and predicts human preference scores for each mask candidate. Extensive experiments and analyses underscore the significance of our proposed datasets and affirm the effectiveness of our PSOD framework.
Read more9/5/2024
🔎
0
Salient Object Detection in RGB-D Videos
Ao Mou, Yukang Lu, Jiahao He, Dingyao Min, Keren Fu, Qijun Zhao
Given the widespread adoption of depth-sensing acquisition devices, RGB-D videos and related data/media have gained considerable traction in various aspects of daily life. Consequently, conducting salient object detection (SOD) in RGB-D videos presents a highly promising and evolving avenue. Despite the potential of this area, SOD in RGB-D videos remains somewhat under-explored, with RGB-D SOD and video SOD (VSOD) traditionally studied in isolation. To explore this emerging field, this paper makes two primary contributions: the dataset and the model. On one front, we construct the RDVS dataset, a new RGB-D VSOD dataset with realistic depth and characterized by its diversity of scenes and rigorous frame-by-frame annotations. We validate the dataset through comprehensive attribute and object-oriented analyses, and provide training and testing splits. Moreover, we introduce DCTNet+, a three-stream network tailored for RGB-D VSOD, with an emphasis on RGB modality and treats depth and optical flow as auxiliary modalities. In pursuit of effective feature enhancement, refinement, and fusion for precise final prediction, we propose two modules: the multi-modal attention module (MAM) and the refinement fusion module (RFM). To enhance interaction and fusion within RFM, we design a universal interaction module (UIM) and then integrate holistic multi-modal attentive paths (HMAPs) for refining multi-modal low-level features before reaching RFMs. Comprehensive experiments, conducted on pseudo RGB-D video datasets alongside our RDVS, highlight the superiority of DCTNet+ over 17 VSOD models and 14 RGB-D SOD models. Ablation experiments were performed on both pseudo and realistic RGB-D video datasets to demonstrate the advantages of individual modules as well as the necessity of introducing realistic depth. Our code together with RDVS dataset will be available at https://github.com/kerenfu/RDVS/.
Read more5/22/2024