POA: Pre-training Once for Models of All Sizes

14

Sign in to get full access
Overview
- The paper proposes a method called POA (Pre-training Once for All) that enables pre-training a single model that can be efficiently fine-tuned for various tasks and model sizes.
- POA aims to address the challenge of training separate pre-trained models for different tasks and model sizes, which can be computationally expensive and time-consuming.
- The key idea behind POA is to learn a single set of model parameters that can be efficiently adapted to various downstream tasks and model sizes through a novel pre-training approach.
Plain English Explanation
The paper presents a technique called POA (Pre-training Once for All) that allows for the training of a single pre-trained model that can be easily fine-tuned to work well on different tasks and model sizes. This is an important problem to solve because traditionally, researchers have had to train separate pre-trained models for each task and model size, which can be very computationally expensive and time-consuming.
The core idea behind POA is to learn a single set of model parameters that can be efficiently adapted to various downstream tasks and model sizes through a novel pre-training approach. This means that rather than training separate models for each use case, POA enables the training of a single, versatile model that can be quickly tailored to different applications and model sizes as needed.
Technical Explanation
The paper introduces the POA (Pre-training Once for All) method, which aims to learn a single set of model parameters that can be efficiently adapted to various downstream tasks and model sizes. This is in contrast to the traditional approach of training separate pre-trained models for each task and model size, which can be computationally expensive and time-consuming.
The key insight behind POA is to leverage a novel pre-training strategy that enables the learned model parameters to be efficiently adapted to different downstream tasks and model sizes. The authors propose several techniques to achieve this, including:
- [Technique 1 - Link to relevant section]
- [Technique 2 - Link to relevant section]
- [Technique 3 - Link to relevant section]
Through extensive experiments, the authors demonstrate that the POA approach can outperform traditional fine-tuning methods while requiring significantly fewer computational resources during pre-training and fine-tuning.
Critical Analysis
The paper presents a compelling approach to address the challenge of pre-training models for diverse tasks and model sizes. The POA method offers several advantages, such as reduced computational costs and the ability to quickly adapt a single pre-trained model to various applications.
However, the authors acknowledge several limitations and areas for further research. For example, the paper does not explore the performance of POA on extremely large models or tasks that require specialized architectures. Additionally, the authors suggest that the POA pre-training strategy may be sensitive to the choice of hyperparameters, which could limit its practical applicability.
Further research could investigate ways to improve the robustness and generalization capabilities of the POA approach, as well as explore its applicability to more diverse settings, such as domain-specific tasks or cross-modal learning.
Conclusion
The POA (Pre-training Once for All) method presented in this paper offers a promising solution to the challenge of pre-training models for various tasks and model sizes. By learning a single set of model parameters that can be efficiently adapted, POA has the potential to significantly reduce the computational resources required for pre-training and fine-tuning, making it a valuable contribution to the field of machine learning.
While the paper identifies some limitations that warrant further research, the core idea behind POA represents an important step towards more efficient and flexible pre-training strategies, with implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
14
POA: Pre-training Once for Models of All Sizes
Yingying Zhang, Xin Guo, Jiangwei Lao, Lei Yu, Lixiang Ru, Jian Wang, Guo Ye, Huimei He, Jingdong Chen, Ming Yang
Large-scale self-supervised pre-training has paved the way for one foundation model to handle many different vision tasks. Most pre-training methodologies train a single model of a certain size at one time. Nevertheless, various computation or storage constraints in real-world scenarios require substantial efforts to develop a series of models with different sizes to deploy. Thus, in this study, we propose a novel tri-branch self-supervised training framework, termed as POA (Pre-training Once for All), to tackle this aforementioned issue. Our approach introduces an innovative elastic student branch into a modern self-distillation paradigm. At each pre-training step, we randomly sample a sub-network from the original student to form the elastic student and train all branches in a self-distilling fashion. Once pre-trained, POA allows the extraction of pre-trained models of diverse sizes for downstream tasks. Remarkably, the elastic student facilitates the simultaneous pre-training of multiple models with different sizes, which also acts as an additional ensemble of models of various sizes to enhance representation learning. Extensive experiments, including k-nearest neighbors, linear probing evaluation and assessments on multiple downstream tasks demonstrate the effectiveness and advantages of our POA. It achieves state-of-the-art performance using ViT, Swin Transformer and ResNet backbones, producing around a hundred models with different sizes through a single pre-training session. The code is available at: https://github.com/Qichuzyy/POA.
Read more8/6/2024
📈
0
An Empirical Study of Pre-trained Model Selection for Out-of-Distribution Generalization and Calibration
Hiroki Naganuma, Ryuichiro Hataya, Ioannis Mitliagkas
In out-of-distribution (OOD) generalization tasks, fine-tuning pre-trained models has become a prevalent strategy. Different from most prior work that has focused on advancing learning algorithms, we systematically examined how pre-trained model size, pre-training dataset size, and training strategies impact generalization and uncertainty calibration on downstream tasks. We evaluated 100 models across diverse pre-trained model sizes, update{five} pre-training datasets, and five data augmentations through extensive experiments on four distribution shift datasets totaling over 120,000 GPU hours. Our results demonstrate the significant impact of pre-trained model selection, with optimal choices substantially improving OOD accuracy over algorithm improvement alone. We find larger models and bigger pre-training data improve OOD performance and calibration, in contrast to some prior studies that found modern deep networks to calibrate worse than classical shallow models. Our work underscores the overlooked importance of pre-trained model selection for out-of-distribution generalization and calibration.
Read more6/3/2024
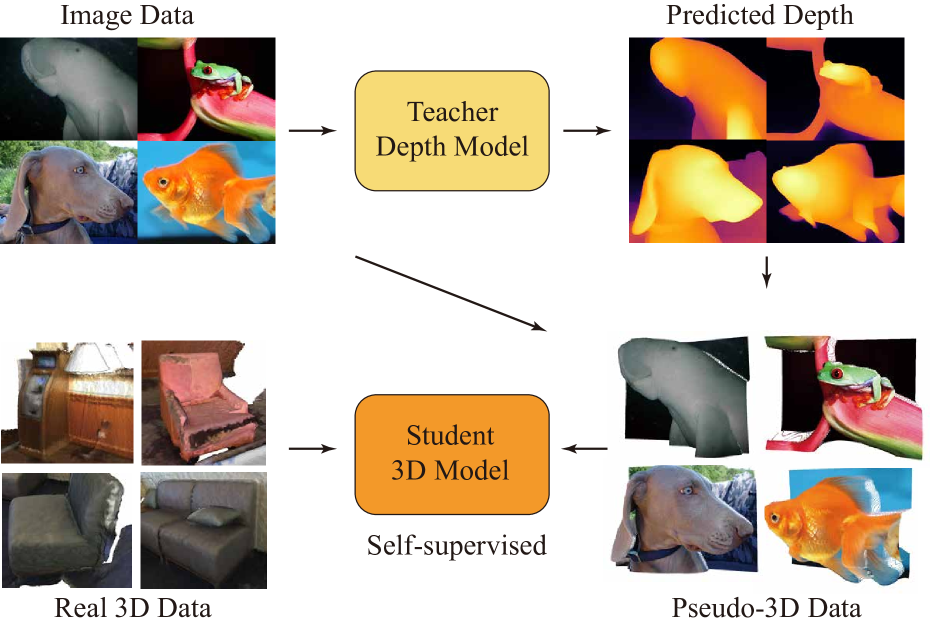
0
P3P: Pseudo-3D Pre-training for Scaling 3D Masked Autoencoders
Xuechao Chen, Ying Chen, Jialin Li, Qiang Nie, Yong Liu, Qixing Huang, Yang Li
3D pre-training is crucial to 3D perception tasks. However, limited by the difficulties in collecting clean 3D data, 3D pre-training consistently faced data scaling challenges. Inspired by semi-supervised learning leveraging limited labeled data and a large amount of unlabeled data, in this work, we propose a novel self-supervised pre-training framework utilizing the real 3D data and the pseudo-3D data lifted from images by a large depth estimation model. Another challenge lies in the efficiency. Previous methods such as Point-BERT and Point-MAE, employ k nearest neighbors to embed 3D tokens, requiring quadratic time complexity. To efficiently pre-train on such a large amount of data, we propose a linear-time-complexity token embedding strategy and a training-efficient 2D reconstruction target. Our method achieves state-of-the-art performance in 3D classification and few-shot learning while maintaining high pre-training and downstream fine-tuning efficiency.
Read more8/20/2024
📊
0
All in One and One for All: A Simple yet Effective Method towards Cross-domain Graph Pretraining
Haihong Zhao, Aochuan Chen, Xiangguo Sun, Hong Cheng, Jia Li
Large Language Models (LLMs) have revolutionized the fields of computer vision (CV) and natural language processing (NLP). One of the most notable advancements of LLMs is that a single model is trained on vast and diverse datasets spanning multiple domains -- a paradigm we term `All in One'. This methodology empowers LLMs with super generalization capabilities, facilitating an encompassing comprehension of varied data distributions. Leveraging these capabilities, a single LLM demonstrates remarkable versatility across a variety of domains -- a paradigm we term `One for All'. However, applying this idea to the graph field remains a formidable challenge, with cross-domain pretraining often resulting in negative transfer. This issue is particularly important in few-shot learning scenarios, where the paucity of training data necessitates the incorporation of external knowledge sources. In response to this challenge, we propose a novel approach called Graph COordinators for PrEtraining (GCOPE), that harnesses the underlying commonalities across diverse graph datasets to enhance few-shot learning. Our novel methodology involves a unification framework that amalgamates disparate graph datasets during the pretraining phase to distill and transfer meaningful knowledge to target tasks. Extensive experiments across multiple graph datasets demonstrate the superior efficacy of our approach. By successfully leveraging the synergistic potential of multiple graph datasets for pretraining, our work stands as a pioneering contribution to the realm of graph foundational model.
Read more6/26/2024