PocketLLM: Enabling On-Device Fine-Tuning for Personalized LLMs
2407.01031
0
0

Abstract
Recent advancements in large language models (LLMs) have indeed showcased their impressive capabilities. On mobile devices, the wealth of valuable, non-public data generated daily holds great promise for locally fine-tuning personalized LLMs, while maintaining privacy through on-device processing. However, the constraints of mobile device resources pose challenges to direct on-device LLM fine-tuning, mainly due to the memory-intensive nature of derivative-based optimization required for saving gradients and optimizer states. To tackle this, we propose employing derivative-free optimization techniques to enable on-device fine-tuning of LLM, even on memory-limited mobile devices. Empirical results demonstrate that the RoBERTa-large model and OPT-1.3B can be fine-tuned locally on the OPPO Reno 6 smartphone using around 4GB and 6.5GB of memory respectively, using derivative-free optimization techniques. This highlights the feasibility of on-device LLM fine-tuning on mobile devices, paving the way for personalized LLMs on resource-constrained devices while safeguarding data privacy.
Create account to get full access
Overview
- Proposes a system called PocketLLM that enables on-device fine-tuning of large language models (LLMs) for personalized use cases
- Aims to make LLMs more accessible and customizable for edge devices with limited computational resources
- Leverages techniques like parameter-efficient fine-tuning and model compression to reduce the memory and compute requirements of fine-tuning LLMs
Plain English Explanation
PocketLLM is a system that allows you to take a large language model, like the ones used in chatbots or virtual assistants, and customize it to work better for your specific needs on your own device.
Normally, these large language models are trained on a huge amount of data and need a lot of computing power to run. PocketLLM uses some special techniques to make the process of fine-tuning, or customizing, the model much more efficient. This means you can take a general-purpose language model and adapt it to your personal preferences or the tasks you want to use it for, all without needing a powerful server or cloud computing resources.
The key ideas behind PocketLLM are using "parameter-efficient" fine-tuning, which modifies only a small part of the original model, and model compression, which shrinks down the size of the model so it can run on devices with limited memory and processing power. This makes it possible to have a customized language model right on your phone, tablet, or other edge device.
The goal is to make large language models more accessible and useful for a wider range of applications, beyond just the biggest tech companies and research labs. By enabling on-device fine-tuning, PocketLLM could lead to more personalized and specialized language AI that can run locally on your own devices.
Technical Explanation
PocketLLM builds on prior work in parameter-efficient fine-tuning and model compression to enable efficient on-device fine-tuning of large language models (LLMs).
The key components of PocketLLM include:
- Parameter-efficient Fine-tuning: Instead of updating all the parameters of the original LLM, PocketLLM fine-tunes only a small subset of the parameters, reducing the memory and compute requirements.
- Model Compression: PocketLLM applies various compression techniques, such as weight pruning and quantization, to further reduce the size and inference cost of the fine-tuned model.
- Efficient Fine-tuning Algorithms: The system uses optimization algorithms designed for resource-constrained devices, like AdamW, to enable fast and stable fine-tuning on the edge.
The authors evaluate PocketLLM on a variety of benchmarks, including MobileAIBench, and demonstrate its ability to fine-tune LLMs like GPT-2 and BERT on edge devices with limited memory and compute resources.
Critical Analysis
The PocketLLM paper makes a compelling case for enabling on-device fine-tuning of LLMs, but there are a few areas that could be explored further:
- Generalization and Transfer Learning: The paper focuses on fine-tuning LLMs for specific tasks, but it would be interesting to see how well the compressed and fine-tuned models can generalize to new tasks or transfer knowledge to related domains.
- Privacy and Security: While on-device fine-tuning can improve personalization, it raises questions about data privacy and the security of the fine-tuned models when deployed on end-user devices.
- Scalability and Deployment Challenges: The authors demonstrate PocketLLM on relatively small LLMs like GPT-2. Scaling the system to handle larger, more capable models, and deploying it in real-world scenarios, may present additional engineering challenges.
Overall, PocketLLM represents an important step towards making LLMs more accessible and customizable for a wider range of applications and users. The techniques developed in this work could have significant implications for the future of personalized and edge-deployed language AI.
Conclusion
The PocketLLM system addresses a key challenge in the adoption of large language models: enabling efficient on-device fine-tuning and deployment. By combining parameter-efficient fine-tuning and model compression, PocketLLM allows users to customize LLMs to their specific needs without requiring powerful computing resources.
This work has the potential to democratize access to advanced language AI, making it more feasible for individual users, small businesses, and resource-constrained organizations to benefit from the capabilities of LLMs. As the authors note, further research is needed to address scalability, privacy, and other deployment challenges, but PocketLLM represents an important step forward in bringing personalized language AI to the edge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra
0
0
This paper addresses the growing need for efficient large language models (LLMs) on mobile devices, driven by increasing cloud costs and latency concerns. We focus on designing top-quality LLMs with fewer than a billion parameters, a practical choice for mobile deployment. Contrary to prevailing belief emphasizing the pivotal role of data and parameter quantity in determining model quality, our investigation underscores the significance of model architecture for sub-billion scale LLMs. Leveraging deep and thin architectures, coupled with embedding sharing and grouped-query attention mechanisms, we establish a strong baseline network denoted as MobileLLM, which attains a remarkable 2.7%/4.3% accuracy boost over preceding 125M/350M state-of-the-art models. Additionally, we propose an immediate block-wise weight-sharing approach with no increase in model size and only marginal latency overhead. The resultant models, denoted as MobileLLM-LS, demonstrate a further accuracy enhancement of 0.7%/0.8% than MobileLLM 125M/350M. Moreover, MobileLLM model family shows significant improvements compared to previous sub-billion models on chat benchmarks, and demonstrates close correctness to LLaMA-v2 7B in API calling tasks, highlighting the capability of small models for common on-device use cases.
6/28/2024
📉
Empirical Guidelines for Deploying LLMs onto Resource-constrained Edge Devices
Ruiyang Qin, Dancheng Liu, Zheyu Yan, Zhaoxuan Tan, Zixuan Pan, Zhenge Jia, Meng Jiang, Ahmed Abbasi, Jinjun Xiong, Yiyu Shi
0
0
The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and inference. As LLMs are increasingly used as personalized intelligent assistants, their customization (i.e., learning through fine-tuning) and deployment onto resource-constrained edge devices will become more and more prevalent. An urging but open question is how a resource-constrained computing environment would affect the design choices for a personalized LLM. We study this problem empirically in this work. In particular, we consider the tradeoffs among a number of key design factors and their intertwined impacts on learning efficiency and accuracy. The factors include the learning methods for LLM customization, the amount of personalized data used for learning customization, the types and sizes of LLMs, the compression methods of LLMs, the amount of time afforded to learn, and the difficulty levels of the target use cases. Through extensive experimentation and benchmarking, we draw a number of surprisingly insightful guidelines for deploying LLMs onto resource-constrained devices. For example, an optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task, the longer fine-tuning time does not necessarily help the model, and a compressed LLM may be a better choice than an uncompressed LLM to learn from limited personalized data.
6/17/2024

Full Parameter Fine-tuning for Large Language Models with Limited Resources
Kai Lv, Yuqing Yang, Tengxiao Liu, Qinghui Gao, Qipeng Guo, Xipeng Qiu
0
0
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but demand massive GPU resources for training. Lowering the threshold for LLMs training would encourage greater participation from researchers, benefiting both academia and society. While existing approaches have focused on parameter-efficient fine-tuning, which tunes or adds a small number of parameters, few have addressed the challenge of tuning the full parameters of LLMs with limited resources. In this work, we propose a new optimizer, LOw-Memory Optimization (LOMO), which fuses the gradient computation and the parameter update in one step to reduce memory usage. By integrating LOMO with existing memory saving techniques, we reduce memory usage to 10.8% compared to the standard approach (DeepSpeed solution). Consequently, our approach enables the full parameter fine-tuning of a 65B model on a single machine with 8 RTX 3090, each with 24GB memory.Code and data are available at https://github.com/OpenLMLab/LOMO.
6/7/2024
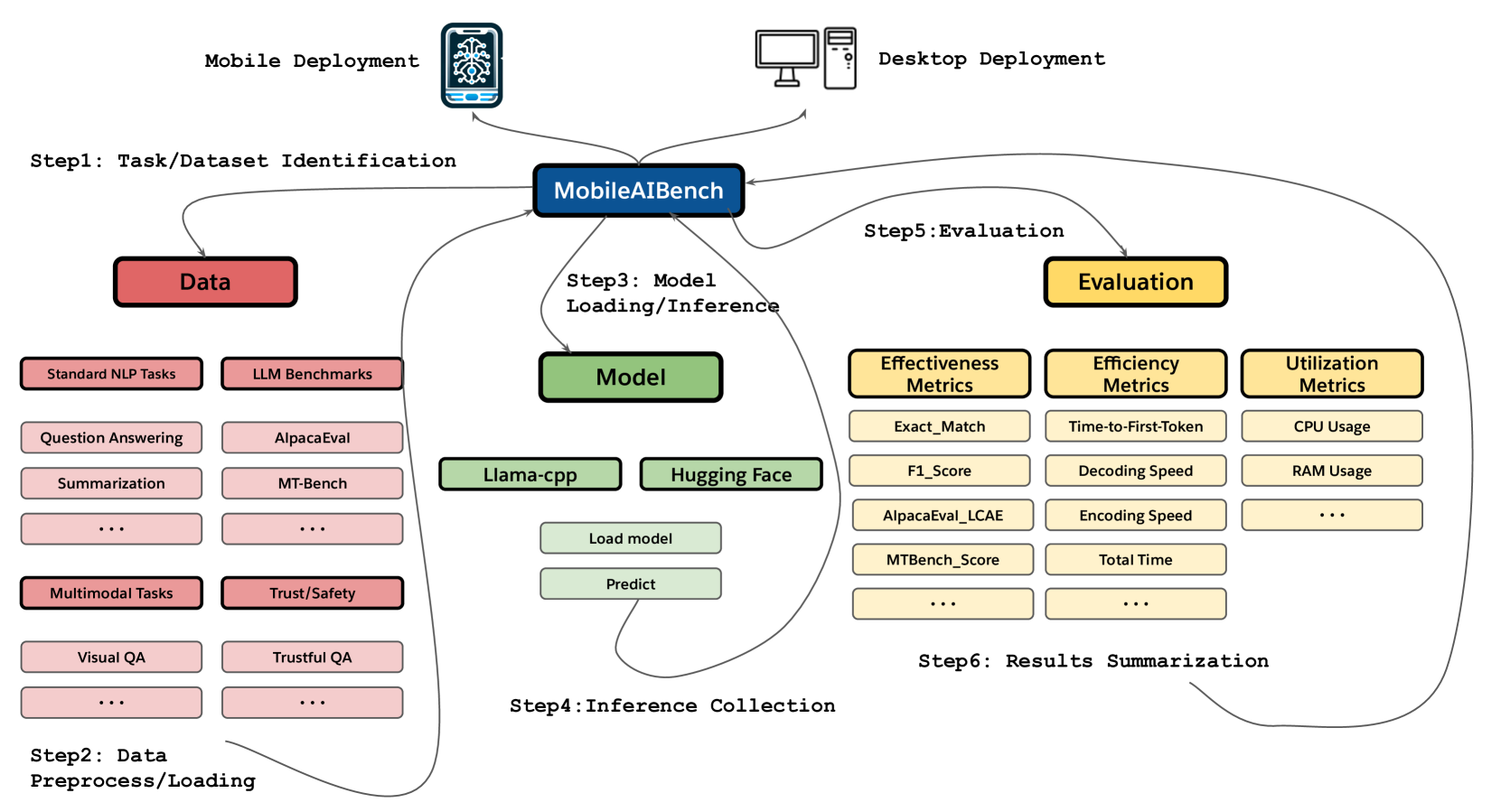
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savarese
0
0
The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
6/18/2024