PointViG: A Lightweight GNN-based Model for Efficient Point Cloud Analysis

0

Sign in to get full access
Overview
- Introduces a lightweight Graph Neural Network (GNN) model called PointViG for efficient point cloud analysis
- Focuses on developing a computationally efficient model for 3D point cloud processing tasks like classification and segmentation
- Aims to address the limitations of existing GNN-based methods in terms of complexity and inference speed
Plain English Explanation
PointViG is a new model for processing 3D point cloud data that uses a Graph Neural Network (GNN) architecture. The researchers designed PointViG to be more lightweight and efficient compared to other GNN-based approaches, making it better suited for real-world applications where computational resources are limited.
Point clouds are 3D data representations commonly used in applications like autonomous vehicles, robotics, and augmented reality. Analyzing point cloud data is challenging due to its irregular structure. GNNs have shown promise for point cloud processing tasks like classification and segmentation, but existing GNN models can be computationally expensive and slow.
The key innovation in PointViG is a novel graph construction method that reduces the model's complexity without sacrificing performance. By using a more efficient graph structure, PointViG can process point clouds faster and with less memory compared to previous GNN-based methods. This makes PointViG a good fit for deploying on edge devices or other resource-constrained environments.
Technical Explanation
The PointViG model uses a GNN architecture to process 3D point cloud data. The researchers developed a new graph construction method called Geometrically-Driven Aggregation that reduces the complexity of the graph while preserving important geometric information.
Typical GNN-based point cloud models construct a dense graph, where each point is connected to all of its neighbors. PointViG instead builds a sparser graph by selectively connecting points based on their geometric relationships. This reduces the number of graph edges, leading to faster inference and lower memory usage.
The PointViG architecture also includes several other optimizations, such as dynamic axial graph convolutions and attention-based pooling, to further improve efficiency without sacrificing performance.
The researchers evaluated PointViG on standard point cloud benchmarks for classification and segmentation tasks. They found that PointViG achieves comparable or better accuracy compared to state-of-the-art GNN models, while being significantly faster and more memory-efficient.
Critical Analysis
The PointViG paper makes a strong case for the need to develop more efficient GNN models for point cloud processing. The researchers' emphasis on balancing performance and computational cost is well-justified, as many real-world applications have strict latency and resource requirements.
One potential limitation of the PointViG approach is that the graph construction method may not be as effective for point clouds with highly irregular or heterogeneous distributions. The paper does not explore this in depth, and it would be valuable to see how PointViG performs on a wider range of point cloud datasets.
Additionally, the paper focuses primarily on classification and segmentation tasks, which are important but not the only applications of point cloud analysis. It would be interesting to see how PointViG fares on other tasks, such as object detection or 3D reconstruction, where the efficient use of computational resources may be even more critical.
Overall, the PointViG paper presents a promising step towards making GNN-based point cloud analysis more practical and accessible for real-world use cases. The researchers' focus on efficiency and performance trade-offs is a valuable contribution to the field.
Conclusion
The PointViG model introduces a lightweight and efficient GNN-based approach for processing 3D point cloud data. By developing a novel graph construction method that reduces complexity without sacrificing accuracy, the researchers have created a model that can be more easily deployed in resource-constrained environments.
The strong performance of PointViG on standard benchmarks, coupled with its significant efficiency gains, suggest that it could be a valuable tool for a wide range of applications, from autonomous vehicles to augmented reality. As the demand for real-time 3D perception continues to grow, models like PointViG will play an increasingly important role in enabling these technologies to become more practical and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PointViG: A Lightweight GNN-based Model for Efficient Point Cloud Analysis
Qiang Zheng, Yafei Qi, Chen Wang, Chao Zhang, Jian Sun
In the domain of point cloud analysis, despite the significant capabilities of Graph Neural Networks (GNNs) in managing complex 3D datasets, existing approaches encounter challenges like high computational costs and scalability issues with extensive scenarios. These limitations restrict the practical deployment of GNNs, notably in resource-constrained environments. To address these issues, this study introduce Point Vision GNN (PointViG), an efficient framework for point cloud analysis. PointViG incorporates a lightweight graph convolutional module to efficiently aggregate local features and mitigate over-smoothing. For large-scale point cloud scenes, we propose an adaptive dilated graph convolution technique that searches for sparse neighboring nodes within a dilated neighborhood based on semantic correlation, thereby expanding the receptive field and ensuring computational efficiency. Experiments demonstrate that PointViG achieves performance comparable to state-of-the-art models while balancing performance and complexity. On the ModelNet40 classification task, PointViG achieved 94.3% accuracy with 1.5M parameters. For the S3DIS segmentation task, it achieved an mIoU of 71.7% with 5.3M parameters. These results underscore the potential and efficiency of PointViG in point cloud analysis.
Read more9/17/2024

0
GreedyViG: Dynamic Axial Graph Construction for Efficient Vision GNNs
Mustafa Munir, William Avery, Md Mostafijur Rahman, Radu Marculescu
Vision graph neural networks (ViG) offer a new avenue for exploration in computer vision. A major bottleneck in ViGs is the inefficient k-nearest neighbor (KNN) operation used for graph construction. To solve this issue, we propose a new method for designing ViGs, Dynamic Axial Graph Construction (DAGC), which is more efficient than KNN as it limits the number of considered graph connections made within an image. Additionally, we propose a novel CNN-GNN architecture, GreedyViG, which uses DAGC. Extensive experiments show that GreedyViG beats existing ViG, CNN, and ViT architectures in terms of accuracy, GMACs, and parameters on image classification, object detection, instance segmentation, and semantic segmentation tasks. Our smallest model, GreedyViG-S, achieves 81.1% top-1 accuracy on ImageNet-1K, 2.9% higher than Vision GNN and 2.2% higher than Vision HyperGraph Neural Network (ViHGNN), with less GMACs and a similar number of parameters. Our largest model, GreedyViG-B obtains 83.9% top-1 accuracy, 0.2% higher than Vision GNN, with a 66.6% decrease in parameters and a 69% decrease in GMACs. GreedyViG-B also obtains the same accuracy as ViHGNN with a 67.3% decrease in parameters and a 71.3% decrease in GMACs. Our work shows that hybrid CNN-GNN architectures not only provide a new avenue for designing efficient models, but that they can also exceed the performance of current state-of-the-art models.
Read more5/14/2024

0
Scaling Graph Convolutions for Mobile Vision
William Avery, Mustafa Munir, Radu Marculescu
To compete with existing mobile architectures, MobileViG introduces Sparse Vision Graph Attention (SVGA), a fast token-mixing operator based on the principles of GNNs. However, MobileViG scales poorly with model size, falling at most 1% behind models with similar latency. This paper introduces Mobile Graph Convolution (MGC), a new vision graph neural network (ViG) module that solves this scaling problem. Our proposed mobile vision architecture, MobileViGv2, uses MGC to demonstrate the effectiveness of our approach. MGC improves on SVGA by increasing graph sparsity and introducing conditional positional encodings to the graph operation. Our smallest model, MobileViGv2-Ti, achieves a 77.7% top-1 accuracy on ImageNet-1K, 2% higher than MobileViG-Ti, with 0.9 ms inference latency on the iPhone 13 Mini NPU. Our largest model, MobileViGv2-B, achieves an 83.4% top-1 accuracy, 0.8% higher than MobileViG-B, with 2.7 ms inference latency. Besides image classification, we show that MobileViGv2 generalizes well to other tasks. For object detection and instance segmentation on MS COCO 2017, MobileViGv2-M outperforms MobileViG-M by 1.2 $AP^{box}$ and 0.7 $AP^{mask}$, and MobileViGv2-B outperforms MobileViG-B by 1.0 $AP^{box}$ and 0.7 $AP^{mask}$. For semantic segmentation on ADE20K, MobileViGv2-M achieves 42.9% $mIoU$ and MobileViGv2-B achieves 44.3% $mIoU$. Our code can be found at url{https://github.com/SLDGroup/MobileViGv2}.
Read more6/11/2024
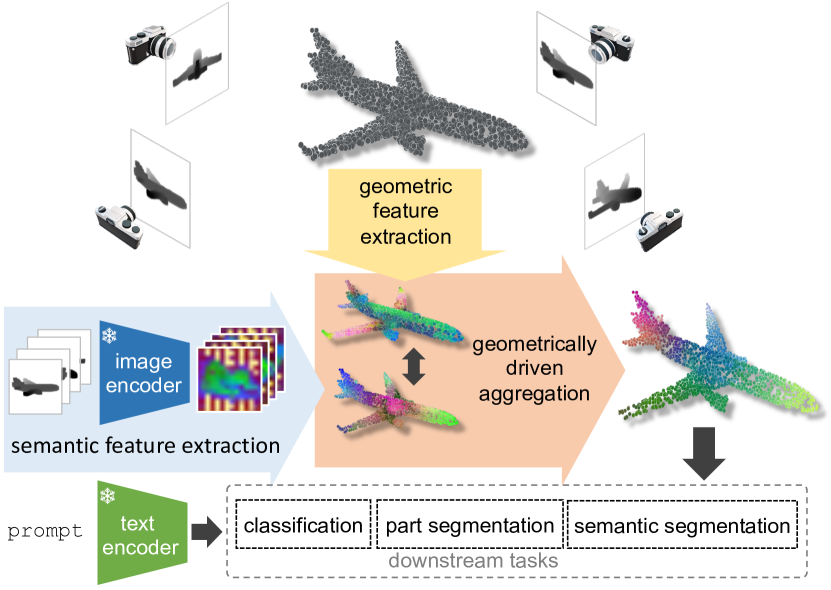
0
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
Read more4/16/2024