Scaling Graph Convolutions for Mobile Vision

0

Sign in to get full access
Overview
- This paper proposes a novel approach to scaling graph convolutions for mobile vision applications.
- The authors introduce a lightweight graph neural network architecture that can efficiently process graph-structured data on mobile devices.
- The proposed model achieves competitive performance on various mobile vision tasks while maintaining a small footprint and low computational complexity.
Plain English Explanation
The paper focuses on developing efficient graph neural networks for mobile devices. Graph neural networks are a type of machine learning model that can work with data that has a graph-like structure, such as social networks or molecular compounds. However, traditional graph neural networks can be computationally expensive, making them challenging to run on mobile phones or other resource-constrained devices.
To address this, the authors propose a new graph neural network architecture that is much more lightweight and efficient. The key idea is to use a novel type of graph convolution operation that is faster and requires less memory than standard approaches. This allows the model to run quickly on mobile devices without sacrificing too much performance.
The authors evaluate their model on several mobile vision tasks, such as image classification and object detection. They show that their model can achieve competitive results compared to state-of-the-art models, while being much smaller and faster. This could enable a new generation of powerful yet energy-efficient computer vision applications on smartphones and other mobile devices.
Technical Explanation
The paper introduces a novel graph neural network architecture called GreedyVIG, which stands for "Greedy Vised Invariant Graph." The key innovation is a dynamic axial graph construction module that efficiently builds a graph representation of the input data.
Rather than using a fixed graph structure, GreedyVIG dynamically constructs the graph based on the input, allowing it to capture relevant relationships in a more adaptive way. This is combined with a gated graph convolution operation that is computationally efficient compared to standard graph convolution.
The authors also propose several other techniques to further reduce the model's size and complexity, including parameter sharing and dynamic channel scaling. These allow the model to be scaled to different hardware and performance requirements.
Experiments on mobile vision benchmarks show that GreedyVIG achieves state-of-the-art results while being significantly more efficient than competing approaches. For example, on the ImageNet-Mobile classification task, GreedyVIG is 2-3x smaller and 2-3x faster than other efficient models like MobileViT and ViG.
Critical Analysis
The paper presents a compelling approach to making graph neural networks more practical for mobile applications. The dynamic graph construction and gated convolution innovations seem well-justified and the experimental results are strong.
However, the paper does not address some potential limitations or areas for further research. For example, it is unclear how well the model would generalize to more complex graph-structured data beyond images, such as molecular structures or social networks.
Additionally, the paper does not provide much insight into the interpretability or explainability of the GreedyVIG model. As these aspects are becoming increasingly important for real-world AI systems, it would be valuable for future work to explore them in more depth.
Overall, this is a solid contribution to the field of efficient deep learning for mobile platforms. The techniques introduced here could have a significant impact on the development of advanced vision applications on smartphones and other resource-constrained devices.
Conclusion
This paper presents an innovative approach to scaling graph convolutions for mobile vision tasks. By introducing a dynamic graph construction module and gated convolution operation, the authors have developed a highly efficient graph neural network architecture called GreedyVIG.
Experimental results demonstrate that GreedyVIG can achieve state-of-the-art performance on mobile vision benchmarks while being significantly smaller and faster than competing models. This work represents an important step towards bringing powerful graph-based deep learning capabilities to resource-constrained devices, paving the way for a new generation of intelligent and energy-efficient mobile applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Graph Convolutions for Mobile Vision
William Avery, Mustafa Munir, Radu Marculescu
To compete with existing mobile architectures, MobileViG introduces Sparse Vision Graph Attention (SVGA), a fast token-mixing operator based on the principles of GNNs. However, MobileViG scales poorly with model size, falling at most 1% behind models with similar latency. This paper introduces Mobile Graph Convolution (MGC), a new vision graph neural network (ViG) module that solves this scaling problem. Our proposed mobile vision architecture, MobileViGv2, uses MGC to demonstrate the effectiveness of our approach. MGC improves on SVGA by increasing graph sparsity and introducing conditional positional encodings to the graph operation. Our smallest model, MobileViGv2-Ti, achieves a 77.7% top-1 accuracy on ImageNet-1K, 2% higher than MobileViG-Ti, with 0.9 ms inference latency on the iPhone 13 Mini NPU. Our largest model, MobileViGv2-B, achieves an 83.4% top-1 accuracy, 0.8% higher than MobileViG-B, with 2.7 ms inference latency. Besides image classification, we show that MobileViGv2 generalizes well to other tasks. For object detection and instance segmentation on MS COCO 2017, MobileViGv2-M outperforms MobileViG-M by 1.2 $AP^{box}$ and 0.7 $AP^{mask}$, and MobileViGv2-B outperforms MobileViG-B by 1.0 $AP^{box}$ and 0.7 $AP^{mask}$. For semantic segmentation on ADE20K, MobileViGv2-M achieves 42.9% $mIoU$ and MobileViGv2-B achieves 44.3% $mIoU$. Our code can be found at url{https://github.com/SLDGroup/MobileViGv2}.
Read more6/11/2024

0
GreedyViG: Dynamic Axial Graph Construction for Efficient Vision GNNs
Mustafa Munir, William Avery, Md Mostafijur Rahman, Radu Marculescu
Vision graph neural networks (ViG) offer a new avenue for exploration in computer vision. A major bottleneck in ViGs is the inefficient k-nearest neighbor (KNN) operation used for graph construction. To solve this issue, we propose a new method for designing ViGs, Dynamic Axial Graph Construction (DAGC), which is more efficient than KNN as it limits the number of considered graph connections made within an image. Additionally, we propose a novel CNN-GNN architecture, GreedyViG, which uses DAGC. Extensive experiments show that GreedyViG beats existing ViG, CNN, and ViT architectures in terms of accuracy, GMACs, and parameters on image classification, object detection, instance segmentation, and semantic segmentation tasks. Our smallest model, GreedyViG-S, achieves 81.1% top-1 accuracy on ImageNet-1K, 2.9% higher than Vision GNN and 2.2% higher than Vision HyperGraph Neural Network (ViHGNN), with less GMACs and a similar number of parameters. Our largest model, GreedyViG-B obtains 83.9% top-1 accuracy, 0.2% higher than Vision GNN, with a 66.6% decrease in parameters and a 69% decrease in GMACs. GreedyViG-B also obtains the same accuracy as ViHGNN with a 67.3% decrease in parameters and a 71.3% decrease in GMACs. Our work shows that hybrid CNN-GNN architectures not only provide a new avenue for designing efficient models, but that they can also exceed the performance of current state-of-the-art models.
Read more5/14/2024

0
PointViG: A Lightweight GNN-based Model for Efficient Point Cloud Analysis
Qiang Zheng, Yafei Qi, Chen Wang, Chao Zhang, Jian Sun
In the domain of point cloud analysis, despite the significant capabilities of Graph Neural Networks (GNNs) in managing complex 3D datasets, existing approaches encounter challenges like high computational costs and scalability issues with extensive scenarios. These limitations restrict the practical deployment of GNNs, notably in resource-constrained environments. To address these issues, this study introduce Point Vision GNN (PointViG), an efficient framework for point cloud analysis. PointViG incorporates a lightweight graph convolutional module to efficiently aggregate local features and mitigate over-smoothing. For large-scale point cloud scenes, we propose an adaptive dilated graph convolution technique that searches for sparse neighboring nodes within a dilated neighborhood based on semantic correlation, thereby expanding the receptive field and ensuring computational efficiency. Experiments demonstrate that PointViG achieves performance comparable to state-of-the-art models while balancing performance and complexity. On the ModelNet40 classification task, PointViG achieved 94.3% accuracy with 1.5M parameters. For the S3DIS segmentation task, it achieved an mIoU of 71.7% with 5.3M parameters. These results underscore the potential and efficiency of PointViG in point cloud analysis.
Read more9/17/2024
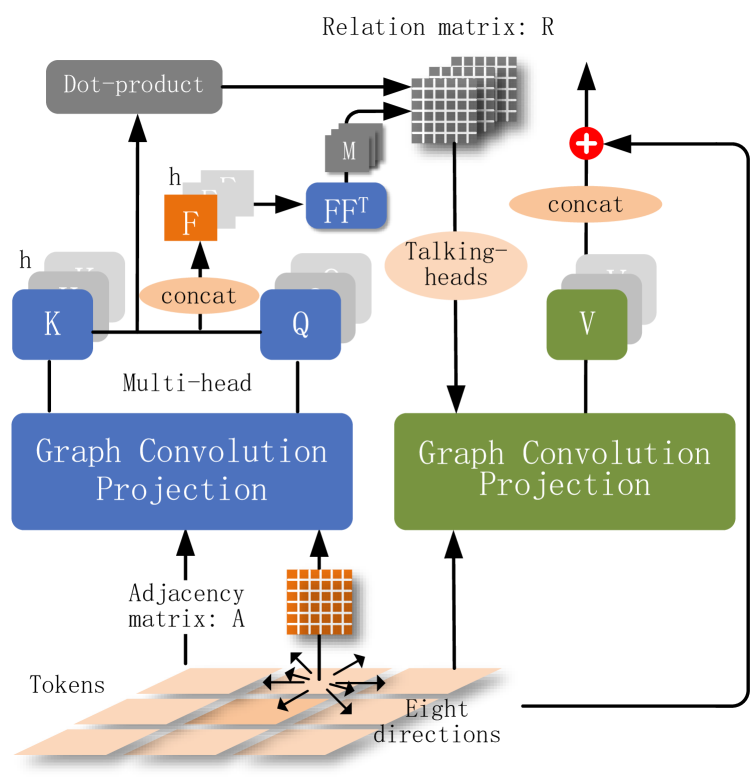
0
GvT: A Graph-based Vision Transformer with Talking-Heads Utilizing Sparsity, Trained from Scratch on Small Datasets
Dongjing Shan, guiqiang chen
Vision Transformers (ViTs) have achieved impressive results in large-scale image classification. However, when training from scratch on small datasets, there is still a significant performance gap between ViTs and Convolutional Neural Networks (CNNs), which is attributed to the lack of inductive bias. To address this issue, we propose a Graph-based Vision Transformer (GvT) that utilizes graph convolutional projection and graph-pooling. In each block, queries and keys are calculated through graph convolutional projection based on the spatial adjacency matrix, while dot-product attention is used in another graph convolution to generate values. When using more attention heads, the queries and keys become lower-dimensional, making their dot product an uninformative matching function. To overcome this low-rank bottleneck in attention heads, we employ talking-heads technology based on bilinear pooled features and sparse selection of attention tensors. This allows interaction among filtered attention scores and enables each attention mechanism to depend on all queries and keys. Additionally, we apply graph-pooling between two intermediate blocks to reduce the number of tokens and aggregate semantic information more effectively. Our experimental results show that GvT produces comparable or superior outcomes to deep convolutional networks and surpasses vision transformers without pre-training on large datasets. The code for our proposed model is publicly available on the website.
Read more4/9/2024