Policy Gradient with Active Importance Sampling

0
🤷
Sign in to get full access
Overview
- Importance sampling (IS) is a fundamental technique for off-policy reinforcement learning (RL) approaches, particularly benefiting policy gradient (PG) methods.
- Traditionally, IS has been used passively to reweight historical samples in RL, but the statistical community employs it actively by optimizing the behavioral policy to reduce the variance of the estimate.
- This paper focuses on the active use of IS, addressing the behavioral policy optimization (BPO) problem to find the best behavioral policy that minimizes the policy gradient variance.
Plain English Explanation
Reinforcement learning is a technique where an agent learns to make good decisions by interacting with an environment and receiving rewards or penalties. Off-policy reinforcement learning is a specific approach where the agent can learn from data collected by a different policy, which can be more efficient.
One key tool in off-policy RL is importance sampling (IS), which allows the agent to reuse previous data by adjusting the weights of the samples. This is particularly helpful for policy gradient methods, a type of RL algorithm that directly optimizes the policy.
Typically, IS is used in a passive way in RL, just to reweight the historical samples. However, the statistics community has found that IS can be used more actively by optimizing the behavioral policy - the policy used to collect the data. This can reduce the variance of the estimates even further, leading to faster learning.
This paper focuses on this active use of IS, trying to find the best behavioral policy to minimize the variance of the policy gradient estimates. The authors provide an algorithm that alternates between estimating the optimal behavioral policy and then using that to improve the main policy.
Technical Explanation
The paper proposes an iterative algorithm for the behavioral policy optimization (BPO) problem. This algorithm alternates between two steps:
- Cross-entropy estimation: Estimating the minimum-variance behavioral policy using defensive importance sampling.
- Policy optimization: Updating the main policy by leveraging the estimated behavioral policy.
The authors provide a theoretical analysis of this algorithm, showing that it converges to a stationary point at a rate of O(ε^-4), which is faster than standard policy gradient methods. Crucially, the variance term it optimizes is more favorable than the standard policy gradient variance.
The paper also presents a practical version of the algorithm that is numerically validated. This shows the advantages of the approach in terms of reduced policy gradient estimation variance and faster learning speed.
Critical Analysis
The paper makes a compelling case for the active use of importance sampling in reinforcement learning, going beyond the traditional passive reweighting approach. The proposed BPO algorithm and its theoretical analysis are technically sound and provide a solid foundation for further research in this direction.
However, the paper does not address some potential limitations and caveats. For example, the algorithm assumes access to the true rewards and transition dynamics, which may not be the case in real-world RL problems. Additionally, the convergence rate analysis relies on strong assumptions, such as the convexity of the problem, which may not hold in more complex settings.
Furthermore, the paper does not explore the practical challenges of implementing the BPO algorithm, such as the computational overhead of the cross-entropy estimation step or the sensitivity to hyperparameter tuning. Entropy-regularized reinforcement learning approaches may provide an interesting alternative to consider in this context.
Overall, the research presented in this paper is a valuable contribution to the field of off-policy reinforcement learning, but further investigation is needed to understand the broader applicability and limitations of the proposed techniques.
Conclusion
This paper introduces an innovative approach to using importance sampling in reinforcement learning, moving beyond the traditional passive reweighting of historical samples. By actively optimizing the behavioral policy, the proposed BPO algorithm can significantly reduce the variance of policy gradient estimates, leading to faster learning.
The theoretical analysis and practical validation of the algorithm provide a solid foundation for further research in this direction. While the approach has some limitations and caveats, it represents an important step forward in the quest for more efficient and robust off-policy RL methods, with potential implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Policy Gradient with Active Importance Sampling
Matteo Papini, Giorgio Manganini, Alberto Maria Metelli, Marcello Restelli
Importance sampling (IS) represents a fundamental technique for a large surge of off-policy reinforcement learning approaches. Policy gradient (PG) methods, in particular, significantly benefit from IS, enabling the effective reuse of previously collected samples, thus increasing sample efficiency. However, classically, IS is employed in RL as a passive tool for re-weighting historical samples. However, the statistical community employs IS as an active tool combined with the use of behavioral distributions that allow the reduction of the estimate variance even below the sample mean one. In this paper, we focus on this second setting by addressing the behavioral policy optimization (BPO) problem. We look for the best behavioral policy from which to collect samples to reduce the policy gradient variance as much as possible. We provide an iterative algorithm that alternates between the cross-entropy estimation of the minimum-variance behavioral policy and the actual policy optimization, leveraging on defensive IS. We theoretically analyze such an algorithm, showing that it enjoys a convergence rate of order $O(epsilon^{-4})$ to a stationary point, but depending on a more convenient variance term w.r.t. standard PG methods. We then provide a practical version that is numerically validated, showing the advantages in the policy gradient estimation variance and on the learning speed.
Read more5/10/2024
🤔
0
Low Variance Off-policy Evaluation with State-based Importance Sampling
David M. Bossens, Philip S. Thomas
In many domains, the exploration process of reinforcement learning will be too costly as it requires trying out suboptimal policies, resulting in a need for off-policy evaluation, in which a target policy is evaluated based on data collected from a known behaviour policy. In this context, importance sampling estimators provide estimates for the expected return by weighting the trajectory based on the probability ratio of the target policy and the behaviour policy. Unfortunately, such estimators have a high variance and therefore a large mean squared error. This paper proposes state-based importance sampling estimators which reduce the variance by dropping certain states from the computation of the importance weight. To illustrate their applicability, we demonstrate state-based variants of ordinary importance sampling, weighted importance sampling, per-decision importance sampling, incremental importance sampling, doubly robust off-policy evaluation, and stationary density ratio estimation. Experiments in four domains show that state-based methods consistently yield reduced variance and improved accuracy compared to their traditional counterparts.
Read more5/7/2024
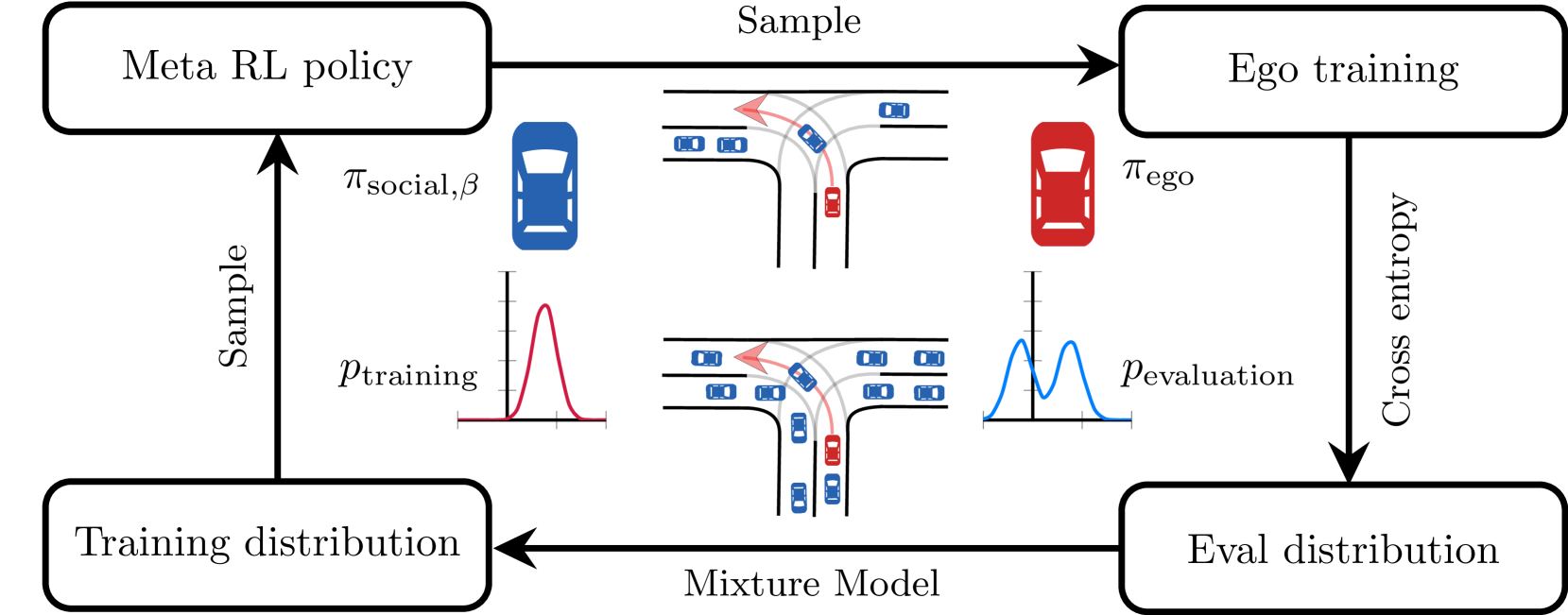
0
Importance Sampling-Guided Meta-Training for Intelligent Agents in Highly Interactive Environments
Mansur Arief, Mike Timmerman, Jiachen Li, David Isele, Mykel J Kochenderfer
Training intelligent agents to navigate highly interactive environments presents significant challenges. While guided meta reinforcement learning (RL) approach that first trains a guiding policy to train the ego agent has proven effective in improving generalizability across various levels of interaction, the state-of-the-art method tends to be overly sensitive to extreme cases, impairing the agents' performance in the more common scenarios. This study introduces a novel training framework that integrates guided meta RL with importance sampling (IS) to optimize training distributions for navigating highly interactive driving scenarios, such as T-intersections. Unlike traditional methods that may underrepresent critical interactions or overemphasize extreme cases during training, our approach strategically adjusts the training distribution towards more challenging driving behaviors using IS proposal distributions and applies the importance ratio to de-bias the result. By estimating a naturalistic distribution from real-world datasets and employing a mixture model for iterative training refinements, the framework ensures a balanced focus across common and extreme driving scenarios. Experiments conducted with both synthetic dataset and T-intersection scenarios from the InD dataset demonstrate not only accelerated training but also improvement in agent performance under naturalistic conditions, showcasing the efficacy of combining IS with meta RL in training reliable autonomous agents for highly interactive navigation tasks.
Read more7/23/2024
🗣️
0
Variational Learning of Gaussian Process Latent Variable Models through Stochastic Gradient Annealed Importance Sampling
Jian Xu, Shian Du, Junmei Yang, Qianli Ma, Delu Zeng
Gaussian Process Latent Variable Models (GPLVMs) have become increasingly popular for unsupervised tasks such as dimensionality reduction and missing data recovery due to their flexibility and non-linear nature. An importance-weighted version of the Bayesian GPLVMs has been proposed to obtain a tighter variational bound. However, this version of the approach is primarily limited to analyzing simple data structures, as the generation of an effective proposal distribution can become quite challenging in high-dimensional spaces or with complex data sets. In this work, we propose an Annealed Importance Sampling (AIS) approach to address these issues. By transforming the posterior into a sequence of intermediate distributions using annealing, we combine the strengths of Sequential Monte Carlo samplers and VI to explore a wider range of posterior distributions and gradually approach the target distribution. We further propose an efficient algorithm by reparameterizing all variables in the evidence lower bound (ELBO). Experimental results on both toy and image datasets demonstrate that our method outperforms state-of-the-art methods in terms of tighter variational bounds, higher log-likelihoods, and more robust convergence.
Read more8/14/2024