A Portable Framework for Accelerating Stencil Computations on Modern Node Architectures

0
🤷
Sign in to get full access
Overview
- Finite-difference methods using high-order stencils are widely used in scientific computing
- Achieving high performance on diverse hardware architectures is challenging, especially as the number of architectures grows
- To address this, the researchers developed StencilPy, a tool that allows developers to write stencil computations in a high-level domain-specific language
- StencilPy generates efficient code for a variety of modern CPU, GPU, and accelerator architectures, including AMD, NVIDIA, Intel, Cerebras, and STX
Plain English Explanation
Stencil computations are a type of mathematical operation that are commonly used in scientific simulations, such as those used in weather forecasting, fluid dynamics, and seismic analysis. These computations involve applying a predefined pattern or "stencil" to a grid of data points, performing calculations, and updating the values at each point.
Achieving high-performance stencil computations on a single hardware architecture can be difficult, and porting the code to run efficiently on a different architecture, such as a newer CPU, GPU, or specialized accelerator, often requires significant effort. This is especially true as the number of diverse computing architectures continues to grow.
To help address this challenge, the researchers developed a tool called StencilPy. With StencilPy, developers can write their stencil computations using a high-level, domain-specific language, which makes the code more concise and easier to work with. StencilPy then automatically generates efficient, optimized code that can run on a variety of modern hardware platforms, including AMD and Intel CPUs, NVIDIA and AMD GPUs, and specialized accelerators like those from Cerebras and STX.
The researchers demonstrate that the performance of the code generated by StencilPy is on par with hand-optimized, architecture-specific code, while requiring much less development effort. For example, a 25-point stencil written in StencilPy is about one-quarter the length of a hand-crafted CUDA implementation for an NVIDIA GPU, yet achieves similar performance. The same stencil written with StencilPy is also 7 times shorter than hand-optimized code for the Cerebras CS-2 accelerator, while delivering comparable performance.
Technical Explanation
The paper describes the development of StencilPy, a tool that aims to simplify the process of writing and optimizing stencil computations for a variety of modern hardware architectures, including CPUs, GPUs, and specialized accelerators.
The key elements of the StencilPy approach include:
-
Domain-Specific Language: Developers write their stencil computations using a high-level, domain-specific language provided by StencilPy. This promotes productivity by allowing them to focus on the mathematical aspects of the problem rather than low-level implementation details.
-
Backend Code Generation: StencilPy's modular design includes multiple backend components that generate efficient, optimized code for the target hardware architecture. This includes support for modern CPUs (e.g., AMD Genoa-X, Fujitsu A64FX, Intel Sapphire Rapids), the latest GPU architectures (NVIDIA H100 and A100, AMD MI200, Intel Ponte Vecchio), and specialized accelerators (Cerebras, STX).
-
Performance Portability: The researchers demonstrate that the performance of the code generated by StencilPy is on par with hand-optimized, architecture-specific implementations, while requiring much less development effort. For example, a 25-point stencil written in StencilPy is about one-quarter the length of a hand-crafted CUDA implementation for an NVIDIA GPU, yet achieves similar performance. The same stencil written with StencilPy is also 7 times shorter than hand-optimized code for the Cerebras CS-2 accelerator, while delivering comparable performance.
-
Modular Design: StencilPy's modular architecture allows for easy configuration, customization, and extension, enabling developers to adapt the tool to their specific needs and integrate it into their existing workflows.
The researchers evaluated the performance of StencilPy-generated code across a range of hardware platforms, including AMD and NVIDIA GPUs, and found that it achieved results on par with hand-optimized, architecture-specific implementations. This demonstrates the tool's ability to deliver both high performance and cross-architectural portability, which can be a significant advantage for scientific computing applications that need to run efficiently on a variety of hardware.
Critical Analysis
The paper presents a compelling solution to the challenge of achieving high-performance stencil computations across diverse hardware architectures. The researchers have developed a robust and flexible tool in StencilPy, which allows developers to write their stencil computations in a high-level domain-specific language, while generating efficient, optimized code for a wide range of modern CPUs, GPUs, and accelerators.
One potential limitation of the research is that it focuses primarily on the performance and portability aspects of StencilPy, without delving deeply into the details of the code generation process or the specific optimization techniques employed. While the paper does mention that StencilPy's modular design enables easy customization and extension, it would be helpful to have more information on the internal workings of the tool and how developers can further optimize the generated code for their specific use cases.
Additionally, the evaluation of StencilPy's performance is limited to a single 25-point stencil example. It would be valuable to see the tool's performance and productivity benefits tested across a wider range of stencil patterns and scientific computing applications, to better understand its broader applicability and potential impact on the field.
Overall, the StencilPy research represents a significant contribution to the challenge of enabling high-performance, cross-architectural stencil computations. The tool's potential to enhance developer productivity and deliver robust performance portability makes it an interesting and promising development in the field of scientific computing.
Conclusion
The StencilPy research tackles the challenge of achieving high-performance stencil computations on a variety of modern hardware architectures, including CPUs, GPUs, and specialized accelerators. By providing a high-level, domain-specific language for writing stencil computations and automatically generating efficient, optimized code, StencilPy aims to enhance developer productivity while maintaining cross-architectural performance portability.
The researchers demonstrate that the code generated by StencilPy can achieve results on par with hand-optimized, architecture-specific implementations, while requiring much less development effort. This suggests that StencilPy could be a valuable tool for scientific computing applications that need to run efficiently on a diverse range of hardware platforms, from traditional CPUs to the latest GPUs and accelerators.
As the landscape of computing architectures continues to evolve, tools like StencilPy that can simplify the process of porting and optimizing code across different hardware will become increasingly important. The researchers' work represents a significant step forward in addressing this challenge and could have far-reaching implications for the field of scientific computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
A Portable Framework for Accelerating Stencil Computations on Modern Node Architectures
Ryuichi Sai, John Mellor-Crummey, Jinfan Xu, Mauricio Araya-Polo
Finite-difference methods based on high-order stencils are widely used in seismic simulations, weather forecasting, computational fluid dynamics, and other scientific applications. Achieving HPC-level stencil computations on one architecture is challenging, porting to other architectures without sacrificing performance requires significant effort, especially in this golden age of many distinctive architectures. To help developers achieve performance, portability, and productivity with stencil computations, we developed StencilPy. With StencilPy, developers write stencil computations in a high-level domain-specific language, which promotes productivity, while its backends generate efficient code for existing and emerging architectures, including modern many-core CPUs (such as AMD Genoa-X, Fujitsu A64FX, and Intel Sapphire Rapids), latest generations of GPUs (including NVIDIA H100 and A100, AMD MI200, and Intel Ponte Vecchio), and accelerators (including Cerebras and STX). StencilPy demonstrates promising performance results on par with hand-written code, maintains cross-architectural performance portability, and enhances productivity. Its modular design enables easy configuration, customization, and extension. A 25-point star-shaped stencil written in StencilPy is one-quarter of the length of a hand-crafted CUDA code and achieves similar performance on an NVIDIA H100 GPU. In addition, the same kernel written using our tool is 7x shorter than hand-optimized code written in Cerebras Software Language (CSL), and it delivers comparable performance that code on a Cerebras CS-2.
Read more7/9/2024
🚀
2
Stencil Computations on AMD and Nvidia Graphics Processors: Performance and Tuning Strategies
Johannes Pekkila, Oskar Lappi, Fredrik Roberts'en, Maarit J. Korpi-Lagg
Over the last ten years, graphics processors have become the de facto accelerator for data-parallel tasks in various branches of high-performance computing, including machine learning and computational sciences. However, with the recent introduction of AMD-manufactured graphics processors to the world's fastest supercomputers, tuning strategies established for previous hardware generations must be re-evaluated. In this study, we evaluate the performance and energy efficiency of stencil computations on modern datacenter graphics processors, and propose a tuning strategy for fusing cache-heavy stencil kernels. The studied cases comprise both synthetic and practical applications, which involve the evaluation of linear and nonlinear stencil functions in one to three dimensions. Our experiments reveal that AMD and Nvidia graphics processors exhibit key differences in both hardware and software, necessitating platform-specific tuning to reach their full computational potential.
Read more6/14/2024
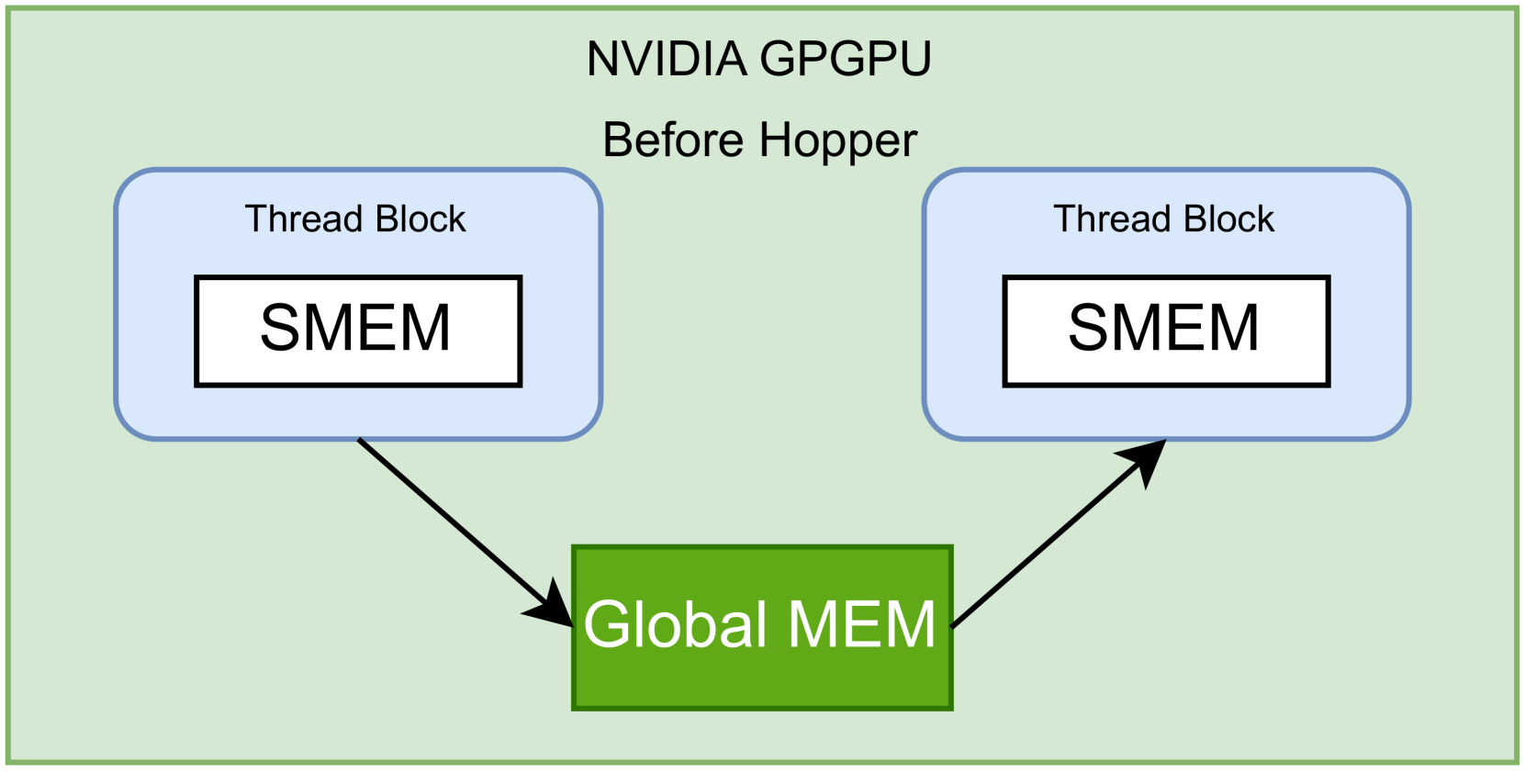
0
Evaluation of Programming Models and Performance for Stencil Computation on Current GPU Architectures
Baodi Shan, Mauricio Araya-Polo
Accelerated computing is widely used in high-performance computing. Therefore, it is crucial to experiment and discover how to better utilize GPUGPUs latest generations on relevant applications. In this paper, we present results and share insights about highly tuned stencil-based kernels for NVIDIA Ampere (A100) and Hopper (GH200) architectures. Performance results yield useful insights into the behavior of this type of algorithms for these new accelerators. This knowledge can be leveraged by many scientific applications which involve stencils computations. Further, evaluation of three different programming models: CUDA, OpenACC, and OpenMP target offloading is conducted on aforementioned accelerators. We extensively study the performance and portability of various kernels under each programming model and provide corresponding optimization recommendations. Furthermore, we compare the performance of different programming models on the mentioned architectures. Up to 58% performance improvement was achieved against the previous GPGPU's architecture generation for an highly optimized kernel of the same class, and up to 42% for all classes. In terms of programming models, and keeping portability in mind, optimized OpenACC implementation outperforms OpenMP implementation by 33%. If portability is not a factor, our best tuned CUDA implementation outperforms the optimized OpenACC one by 2.1x.
Read more8/13/2024
0
Taking GPU Programming Models to Task for Performance Portability
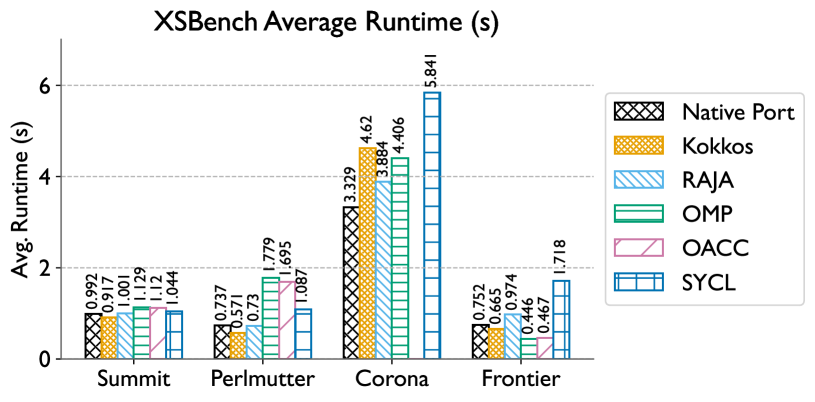
Joshua H. Davis, Pranav Sivaraman, Joy Kitson, Konstantinos Parasyris, Harshitha Menon, Isaac Minn, Giorgis Georgakoudis, Abhinav Bhatele
Portability is critical to ensuring high productivity in developing and maintaining scientific software as the diversity in on-node hardware architectures increases. While several programming models provide portability for diverse GPU platforms, they don't make any guarantees about performance portability. In this work, we explore several programming models -- CUDA, HIP, Kokkos, RAJA, OpenMP, OpenACC, and SYCL, to study if the performance of these models is consistently good across NVIDIA and AMD GPUs. We use five proxy applications from different scientific domains, create implementations where missing, and use them to present a comprehensive comparative evaluation of the programming models. We provide a Spack scripting-based methodology to ensure reproducibility of experiments conducted in this work. Finally, we attempt to answer the question -- to what extent does each programming model provide performance portability for heterogeneous systems in real-world usage?
Read more5/22/2024