Position: Insights from Survey Methodology can Improve Training Data
2403.01208
0
0
Abstract
Whether future AI models are fair, trustworthy, and aligned with the public's interests rests in part on our ability to collect accurate data about what we want the models to do. However, collecting high-quality data is difficult, and few AI/ML researchers are trained in data collection methods. Recent research in data-centric AI has show that higher quality training data leads to better performing models, making this the right moment to introduce AI/ML researchers to the field of survey methodology, the science of data collection. We summarize insights from the survey methodology literature and discuss how they can improve the quality of training and feedback data. We also suggest collaborative research ideas into how biases in data collection can be mitigated, making models more accurate and human-centric.
Create account to get full access
Overview
- The paper examines how the principles of survey design can be applied to improve the quality and usefulness of data collection for machine learning models.
- It draws parallels between the process of labeling data for machine learning and conducting surveys, highlighting key similarities in how respondents (or labelers) can introduce biases and errors.
- The paper proposes ways to leverage survey methodology to enhance the reliability and generalizability of machine learning datasets.
Plain English Explanation
Machine learning models rely on high-quality data to make accurate predictions. However, the process of collecting and labeling that data can be challenging and fraught with potential biases. This paper explores how the principles of survey design can be applied to improve the data collection process for machine learning.
Just like survey respondents can introduce biases based on their own perspectives and experiences, the people who label data for machine learning models (called "labelers") can also introduce similar biases. The paper argues that by understanding the labelers as respondents, researchers can design more robust and reliable data collection processes, similar to how survey designers account for respondent biases.
For example, the way a survey question is phrased can significantly influence how a respondent answers. Similarly, the instructions and guidelines given to labelers can shape how they interpret and label the data. By applying techniques from survey methodology, such as pilot testing and statistical analysis, machine learning researchers can identify and mitigate these biases, leading to higher-quality datasets that produce more accurate and generalizable models.
The paper also explores how large language models can be leveraged to enhance the data collection process, such as by automatically generating survey questions or providing real-time feedback to labelers. This integration of AI and survey methodology could lead to significant improvements in the quality and efficiency of data collection for machine learning.
Technical Explanation
The paper draws parallels between the process of labeling data for machine learning and conducting surveys, highlighting key similarities in how respondents (or labelers) can introduce biases and errors. It argues that by understanding the labelers as respondents, researchers can design more robust and reliable data collection processes, similar to how survey designers account for respondent biases.
The authors discuss how the instructions and guidelines given to labelers can shape their interpretations and labeling decisions, much like how the phrasing of survey questions can influence respondents' answers. They propose applying techniques from survey methodology, such as pilot testing and statistical analysis, to identify and mitigate these biases in the data collection process.
The paper also explores the potential for large language models to enhance the data collection process, such as by automatically generating survey questions or providing real-time feedback to labelers. This integration of AI and survey methodology could lead to significant improvements in the quality and efficiency of data collection for machine learning.
Critical Analysis
The paper presents a compelling argument for applying survey methodology to improve the quality and reliability of machine learning datasets. By acknowledging the labelers as respondents and accounting for potential biases, the proposed approach offers a more rigorous and systematic way to collect high-quality data.
However, the paper does not delve into the practical challenges of implementing these survey-based techniques in real-world machine learning projects. Factors such as the scale of data collection, the diversity of labeling tasks, and the availability of resources may pose significant hurdles. Further research is needed to explore the feasibility and scalability of these methods in various machine learning contexts.
Additionally, the paper does not address the potential ethical implications of the proposed approach. While mitigating biases in data collection is crucial, there may be concerns around the privacy and autonomy of labelers, especially in the context of crowdsourcing or outsourced labeling. Careful consideration of these ethical issues would be necessary to ensure the responsible implementation of these techniques.
Conclusion
The paper presents a compelling case for applying the principles of survey design to improve the quality and reliability of machine learning datasets. By understanding labelers as respondents and leveraging techniques from survey methodology, the proposed approach offers a promising way to mitigate biases and enhance the generalizability of machine learning models.
The integration of large language models in the data collection process further suggests that the field of machine learning can benefit from cross-pollination with other disciplines, such as social science research. As the demand for high-quality data continues to grow, the insights from this paper could pave the way for more rigorous and effective data collection practices in the machine learning community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AI Competitions and Benchmarks: Dataset Development
Romain Egele, Julio C. S. Jacques Junior, Jan N. van Rijn, Isabelle Guyon, Xavier Bar'o, Albert Clap'es, Prasanna Balaprakash, Sergio Escalera, Thomas Moeslund, Jun Wan
0
0
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
4/16/2024

Data Readiness for AI: A 360-Degree Survey
Kaveen Hiniduma, Suren Byna, Jean Luca Bez
0
0
Data are the critical fuel for Artificial Intelligence (AI) models. Poor quality data produces inaccurate and ineffective AI models that may lead to incorrect or unsafe use. Checking for data readiness is a crucial step in improving data quality. Numerous R&D efforts have been spent on improving data quality. However, standardized metrics for evaluating data readiness for use in AI training are still evolving. In this study, we perform a comprehensive survey of metrics used for verifying AI's data readiness. This survey examines more than 120 papers that are published by ACM Digital Library, IEEE Xplore, other reputable journals, and articles published on the web by prominent AI experts. This survey aims to propose a taxonomy of data readiness for AI (DRAI) metrics for structured and unstructured datasets. We anticipate that this taxonomy can lead to new standards for DRAI metrics that would be used for enhancing the quality and accuracy of AI training and inference.
4/10/2024
Understanding the Dataset Practitioners Behind Large Language Model Development
Crystal Qian, Emily Reif, Minsuk Kahng
0
0
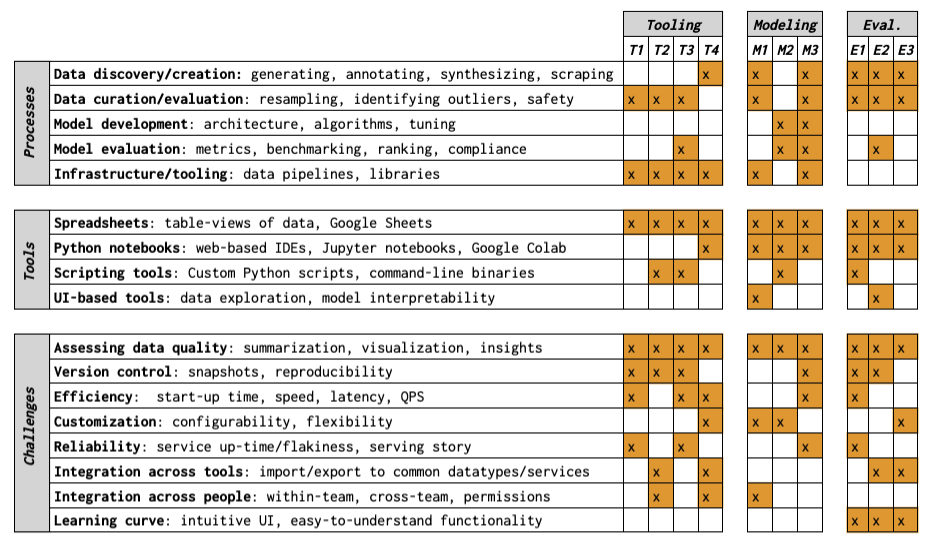
As large language models (LLMs) become more advanced and impactful, it is increasingly important to scrutinize the data that they rely upon and produce. What is it to be a dataset practitioner doing this work? We approach this in two parts: first, we define the role of dataset practitioners by performing a retrospective analysis on the responsibilities of teams contributing to LLM development at a technology company, Google. Then, we conduct semi-structured interviews with a cross-section of these practitioners (N=10). We find that although data quality is a top priority, there is little consensus around what data quality is and how to evaluate it. Consequently, practitioners either rely on their own intuition or write custom code to evaluate their data. We discuss potential reasons for this phenomenon and opportunities for alignment.
4/3/2024
📊
Data Authenticity, Consent, & Provenance for AI are all broken: what will it take to fix them?
Shayne Longpre, Robert Mahari, Naana Obeng-Marnu, William Brannon, Tobin South, Katy Gero, Sandy Pentland, Jad Kabbara
0
0
New capabilities in foundation models are owed in large part to massive, widely-sourced, and under-documented training data collections. Existing practices in data collection have led to challenges in documenting data transparency, tracing authenticity, verifying consent, privacy, representation, bias, copyright infringement, and the overall development of ethical and trustworthy foundation models. In response, regulation is emphasizing the need for training data transparency to understand foundation models' limitations. Based on a large-scale analysis of the foundation model training data landscape and existing solutions, we identify the missing infrastructure to facilitate responsible foundation model development practices. We examine the current shortcomings of common tools for tracing data authenticity, consent, and documentation, and outline how policymakers, developers, and data creators can facilitate responsible foundation model development by adopting universal data provenance standards.
4/22/2024