A Practice of Post-Training on Llama-3 70B with Optimal Selection of Additional Language Mixture Ratio

0

Sign in to get full access
Overview
- The paper explores post-training techniques to improve the performance of the large language model Llama-3 70B.
- The researchers examine the optimal selection of additional language mixture ratios during post-training.
- The goal is to enhance the model's capabilities while maintaining efficiency and effectiveness.
Plain English Explanation
The researchers in this paper looked at ways to further improve the performance of a large language model called Llama-3 70B. Llama-3 70B is a very powerful AI that can understand and generate human-like text. The researchers wanted to see if they could make Llama-3 70B even better by giving it additional training on a mix of different types of text data.
The key idea is that by carefully selecting the right balance or "mixture ratio" of different languages and text styles during this additional training, the researchers could optimize Llama-3 70B's capabilities. This post-training process aims to enhance the model's understanding and generation, while still keeping it efficient and effective to use.
The researchers explored various techniques and approaches to find the optimal additional language mixture ratio for post-training Llama-3 70B. Their goal was to unlock the model's full potential without introducing unnecessary complexity or inefficiencies.
Technical Explanation
The paper focuses on post-training techniques to enhance the performance of the large language model Llama-3 70B. The researchers investigate the optimal selection of additional language mixture ratios during the post-training process.
The experimental setup involves fine-tuning the pre-trained Llama-3 70B model on a mix of different language datasets. The researchers systematically vary the ratios of these additional languages to determine the configuration that yields the best overall performance.
Key insights from the technical evaluation include:
- Specific mixture ratios of additional languages can lead to significant improvements in the model's performance on a range of benchmark tasks.
- The optimal mixture ratio is dependent on the target applications and desired capabilities of the language model.
- The post-training approach allows for efficient fine-tuning without dramatically increasing the model's size or complexity.
Critical Analysis
The paper provides a thorough exploration of post-training techniques for optimizing the Llama-3 70B language model. The researchers acknowledge that the optimal mixture ratio of additional languages is context-dependent and may require further exploration for different use cases.
One potential limitation is that the paper does not delve into the underlying reasons why certain mixture ratios lead to better performance. A deeper analysis of the learned representations and their relationship to the language composition could provide additional insights.
Additionally, the researchers do not extensively discuss potential negative societal impacts or biases that may arise from the post-training process. As large language models become more advanced, it is important to carefully consider their ethical implications.
Overall, the paper presents a valuable contribution to the field of language model optimization, but further research is needed to fully understand the nuances and tradeoffs involved in this approach.
Conclusion
This paper investigates a practice of post-training on the Llama-3 70B language model, with a focus on the optimal selection of additional language mixture ratios. The researchers demonstrate that carefully tailoring the post-training data composition can lead to significant performance improvements without drastically increasing the model's complexity.
The findings have important implications for the efficient development and deployment of large language models, as they offer a pathway to enhance capabilities while maintaining cost-effectiveness and scalability. As the field of AI continues to advance, this type of research will be crucial in ensuring that powerful language models are leveraged in responsible and beneficial ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Practice of Post-Training on Llama-3 70B with Optimal Selection of Additional Language Mixture Ratio
Ningyuan Xi, Yetao Wu, Kun Fan, Teng Chen, Qingqing Gu, Peng Yu, Jinxian Qu, Chenxi Liu, Zhonglin Jiang, Yong Chen, Luo Ji
Large Language Models (LLM) often needs to be Continual Pre-Trained (CPT) to obtain the unfamiliar language skill or adapt into new domains. The huge training cost of CPT often asks for cautious choice of key hyper-parameters such as the mixture ratio of extra language or domain corpus. However, there is no systematic study which bridge the gap between the optimal mixture ratio and the actual model performance, and the gap between experimental scaling law and the actual deployment in the full model size. In this paper, we perform CPT on Llama-3 8B and 70B to enhance its Chinese ability. We study the optimal correlation between the Additional Language Mixture Ratio (ALMR) and the Learning Rate (LR) on the 8B size which directly indicate the optimal experimental set up. By thorough choice of hyper-parameter, and subsequent fine-tuning, the model capability is improved not only on the Chinese-related benchmark, but also some specific domains including math, coding and emotional intelligence. We deploy the final 70B version of LLM on an real-life chat system which obtain satisfying performance.
Read more9/11/2024

0
Towards Effective and Efficient Continual Pre-training of Large Language Models
Jie Chen, Zhipeng Chen, Jiapeng Wang, Kun Zhou, Yutao Zhu, Jinhao Jiang, Yingqian Min, Wayne Xin Zhao, Zhicheng Dou, Jiaxin Mao, Yankai Lin, Ruihua Song, Jun Xu, Xu Chen, Rui Yan, Zhewei Wei, Di Hu, Wenbing Huang, Ji-Rong Wen
Continual pre-training (CPT) has been an important approach for adapting language models to specific domains or tasks. To make the CPT approach more traceable, this paper presents a technical report for continually pre-training Llama-3 (8B), which significantly enhances the Chinese language ability and scientific reasoning ability of the backbone model. To enhance the new abilities while retaining the original abilities, we design specific data mixture and curriculum strategies by utilizing existing datasets and synthesizing high-quality datasets. Specifically, we synthesize multidisciplinary scientific question and answer (QA) pairs based on related web pages, and subsequently incorporate these synthetic data to improve the scientific reasoning ability of Llama-3. We refer to the model after CPT as Llama-3-SynE (Synthetic data Enhanced Llama-3). We also present the tuning experiments with a relatively small model -- TinyLlama, and employ the derived findings to train the backbone model. Extensive experiments on a number of evaluation benchmarks show that our approach can largely improve the performance of the backbone models, including both the general abilities (+8.81 on C-Eval and +6.31 on CMMLU) and the scientific reasoning abilities (+12.00 on MATH and +4.13 on SciEval), without hurting the original capacities. Our model, data, and codes are available at https://github.com/RUC-GSAI/Llama-3-SynE.
Read more7/29/2024

0
CMR Scaling Law: Predicting Critical Mixture Ratios for Continual Pre-training of Language Models
Jiawei Gu, Zacc Yang, Chuanghao Ding, Rui Zhao, Fei Tan
Large Language Models (LLMs) excel in diverse tasks but often underperform in specialized fields due to limited domain-specific or proprietary corpus. Continual pre-training (CPT) enhances LLM capabilities by imbuing new domain-specific or proprietary knowledge while replaying general corpus to prevent catastrophic forgetting. The data mixture ratio of general corpus and domain-specific corpus, however, has been chosen heuristically, leading to sub-optimal training efficiency in practice. In this context, we attempt to re-visit the scaling behavior of LLMs under the hood of CPT, and discover a power-law relationship between loss, mixture ratio, and training tokens scale. We formalize the trade-off between general and domain-specific capabilities, leading to a well-defined Critical Mixture Ratio (CMR) of general and domain data. By striking the balance, CMR maintains the model's general ability and achieves the desired domain transfer, ensuring the highest utilization of available resources. Therefore, if we value the balance between efficiency and effectiveness, CMR can be consider as the optimal mixture ratio.Through extensive experiments, we ascertain the predictability of CMR, and propose CMR scaling law and have substantiated its generalization. These findings offer practical guidelines for optimizing LLM training in specialized domains, ensuring both general and domain-specific performance while efficiently managing training resources.
Read more7/25/2024
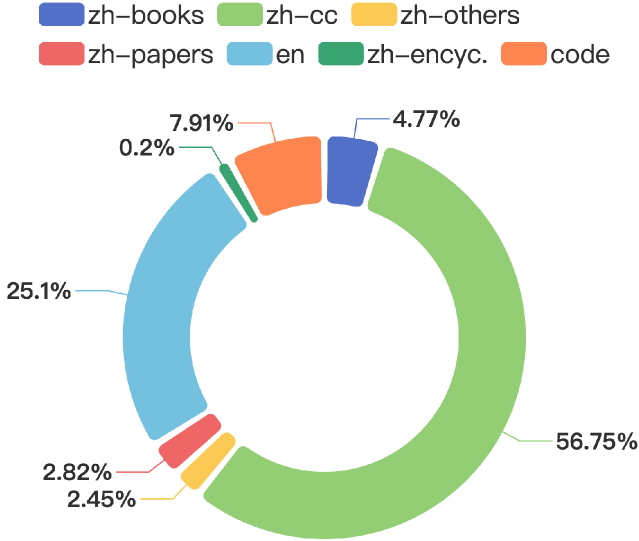
0
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Wenhu Chen, Ge Zhang
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
Read more9/16/2024