Towards Effective and Efficient Continual Pre-training of Large Language Models

0

Sign in to get full access
Overview
- The paper proposes an effective and efficient approach for continually pre-training large language models.
- It addresses the stability issue in continual pre-training and demonstrates improved performance on downstream tasks.
- The approach uses a combination of techniques to maintain model performance while efficiently updating the model.
Plain English Explanation
The paper focuses on the task of continually pre-training large language models, which means updating or fine-tuning these models on new data over time. This is an important task because as the world changes, the language models need to be updated to stay current and relevant.
However, continually pre-training large models can be challenging, as it can lead to a problem called "catastrophic forgetting." This means that as the model learns new information, it can start to forget or lose its ability to perform well on the original tasks it was trained on.
To address this issue, the researchers propose a new approach that combines several techniques:
- Selective Pre-training: The model is only updated on a subset of the data, which helps it retain knowledge from the original pre-training.
- Adaptive Regularization: The model is regularized in a way that adapts to the specific task and data, helping to prevent catastrophic forgetting.
- Efficient Compute Allocation: The model updates are designed to be computationally efficient, allowing for more frequent updates without excessive resource usage.
By using this combination of techniques, the researchers were able to demonstrate that their approach leads to improved performance on downstream tasks, while also being more efficient and effective than traditional continual pre-training methods.
Technical Explanation
The paper introduces a novel approach for continual pre-training of large language models, which aims to address the stability issue and improve the efficiency of the process.
The key components of the proposed approach are:
-
Selective Pre-training: Instead of updating the entire model on all the new data, the model is selectively updated on a subset of the data. This helps the model retain knowledge from the original pre-training, mitigating the risk of catastrophic forgetting.
-
Adaptive Regularization: The researchers use a form of regularization that adapts to the specific task and data, helping to prevent the model from forgetting the original pre-training. This is achieved through a combination of L2 regularization and a novel "online distillation" technique.
-
Efficient Compute Allocation: The updates to the model are designed to be computationally efficient, allowing for more frequent updates without excessive resource usage. This is accomplished by using a warm-start initialization and a targeted update strategy.
The researchers evaluate their approach on a range of downstream tasks, including language understanding, generation, and reasoning. They demonstrate that their method outperforms traditional continual pre-training approaches in terms of both effectiveness and efficiency.
Critical Analysis
The paper presents a well-designed and thorough approach to the challenge of continual pre-training of large language models. The researchers have identified a key issue in this area – the stability problem of catastrophic forgetting – and have developed a comprehensive solution that addresses multiple aspects of the problem.
One potential limitation of the research is that it focuses primarily on standard language understanding and generation tasks, and it would be interesting to see how the approach performs on more specialized or domain-specific applications. Additionally, the paper does not provide a detailed analysis of the computational costs and resource requirements of the proposed method, which could be an important consideration for real-world deployment.
Furthermore, the researchers acknowledge that their approach is still limited by the inherent trade-off between plasticity (the ability to learn new information) and stability (the ability to retain previously learned knowledge). They suggest that further research is needed to find a more complete solution to this fundamental challenge in continual learning.
Overall, the paper presents a significant contribution to the field of large language model pre-training and offers a promising direction for future research in this area.
Conclusion
The paper introduces an effective and efficient approach for continual pre-training of large language models, which addresses the stability issue and demonstrates improved performance on downstream tasks.
The key innovations of the proposed method include selective pre-training, adaptive regularization, and efficient compute allocation. These techniques work together to enable the model to learn new information while preserving its original capabilities, leading to more stable and effective continual pre-training.
The findings of this research have important implications for the development of large language models that can continually evolve and adapt to changing data and requirements, without sacrificing their core functionality. As language models become more integral to a wide range of applications, the ability to efficiently and effectively update these models over time will be crucial for maintaining their relevance and utility.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Effective and Efficient Continual Pre-training of Large Language Models
Jie Chen, Zhipeng Chen, Jiapeng Wang, Kun Zhou, Yutao Zhu, Jinhao Jiang, Yingqian Min, Wayne Xin Zhao, Zhicheng Dou, Jiaxin Mao, Yankai Lin, Ruihua Song, Jun Xu, Xu Chen, Rui Yan, Zhewei Wei, Di Hu, Wenbing Huang, Ji-Rong Wen
Continual pre-training (CPT) has been an important approach for adapting language models to specific domains or tasks. To make the CPT approach more traceable, this paper presents a technical report for continually pre-training Llama-3 (8B), which significantly enhances the Chinese language ability and scientific reasoning ability of the backbone model. To enhance the new abilities while retaining the original abilities, we design specific data mixture and curriculum strategies by utilizing existing datasets and synthesizing high-quality datasets. Specifically, we synthesize multidisciplinary scientific question and answer (QA) pairs based on related web pages, and subsequently incorporate these synthetic data to improve the scientific reasoning ability of Llama-3. We refer to the model after CPT as Llama-3-SynE (Synthetic data Enhanced Llama-3). We also present the tuning experiments with a relatively small model -- TinyLlama, and employ the derived findings to train the backbone model. Extensive experiments on a number of evaluation benchmarks show that our approach can largely improve the performance of the backbone models, including both the general abilities (+8.81 on C-Eval and +6.31 on CMMLU) and the scientific reasoning abilities (+12.00 on MATH and +4.13 on SciEval), without hurting the original capacities. Our model, data, and codes are available at https://github.com/RUC-GSAI/Llama-3-SynE.
Read more7/29/2024

0
A Practice of Post-Training on Llama-3 70B with Optimal Selection of Additional Language Mixture Ratio
Ningyuan Xi, Yetao Wu, Kun Fan, Teng Chen, Qingqing Gu, Peng Yu, Jinxian Qu, Chenxi Liu, Zhonglin Jiang, Yong Chen, Luo Ji
Large Language Models (LLM) often needs to be Continual Pre-Trained (CPT) to obtain the unfamiliar language skill or adapt into new domains. The huge training cost of CPT often asks for cautious choice of key hyper-parameters such as the mixture ratio of extra language or domain corpus. However, there is no systematic study which bridge the gap between the optimal mixture ratio and the actual model performance, and the gap between experimental scaling law and the actual deployment in the full model size. In this paper, we perform CPT on Llama-3 8B and 70B to enhance its Chinese ability. We study the optimal correlation between the Additional Language Mixture Ratio (ALMR) and the Learning Rate (LR) on the 8B size which directly indicate the optimal experimental set up. By thorough choice of hyper-parameter, and subsequent fine-tuning, the model capability is improved not only on the Chinese-related benchmark, but also some specific domains including math, coding and emotional intelligence. We deploy the final 70B version of LLM on an real-life chat system which obtain satisfying performance.
Read more9/11/2024
0
Efficient Continual Pre-training by Mitigating the Stability Gap
Yiduo Guo, Jie Fu, Huishuai Zhang, Dongyan Zhao, Yikang Shen
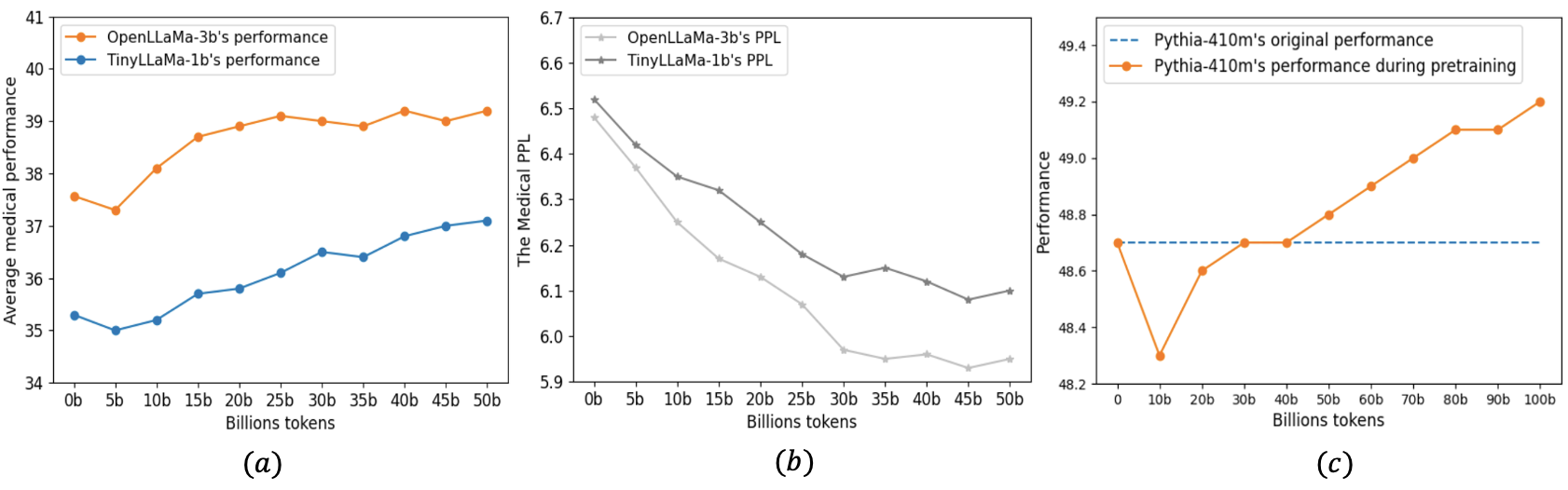
Continual pre-training has increasingly become the predominant approach for adapting Large Language Models (LLMs) to new domains. This process involves updating the pre-trained LLM with a corpus from a new domain, resulting in a shift in the training distribution. To study the behavior of LLMs during this shift, we measured the model's performance throughout the continual pre-training process. we observed a temporary performance drop at the beginning, followed by a recovery phase, a phenomenon known as the stability gap, previously noted in vision models classifying new classes. To address this issue and enhance LLM performance within a fixed compute budget, we propose three effective strategies: (1) Continually pre-training the LLM on a subset with a proper size for multiple epochs, resulting in faster performance recovery than pre-training the LLM on a large corpus in a single epoch; (2) Pre-training the LLM only on high-quality sub-corpus, which rapidly boosts domain performance; and (3) Using a data mixture similar to the pre-training data to reduce distribution gap. We conduct various experiments on Llama-family models to validate the effectiveness of our strategies in both medical continual pre-training and instruction tuning. For example, our strategies improve the average medical task performance of the OpenLlama-3B model from 36.2% to 40.7% with only 40% of the original training budget and enhance the average general task performance without causing forgetting. Furthermore, we apply our strategies to the Llama-3-8B model. The resulting model, Llama-3-Physician, achieves the best medical performance among current open-source models, and performs comparably to or even better than GPT-4 on several medical benchmarks. We release our models at url{https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct}.
Read more6/28/2024

0
A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
Read more4/16/2024