Pre-trained Language Models Improve the Few-shot Prompt Ability of Decision Transformer

0

Sign in to get full access
Overview
- The paper investigates how pre-trained language models can improve the few-shot prompt ability of the Decision Transformer, a policy learning model.
- The researchers explore how language model prompts can enhance the performance of Decision Transformer on downstream tasks with limited training data.
- Key findings include that pre-trained language model prompts significantly boost the few-shot performance of Decision Transformer across a range of environments.
Plain English Explanation
The paper examines how using pre-trained language models, such as GPT-3, can help improve the performance of the Decision Transformer model when it is only trained on a small amount of data. The Decision Transformer is a type of machine learning model that learns to make decisions by modeling decision-making as a language modeling task.
The researchers found that by providing the Decision Transformer with prompts generated by pre-trained language models, they could significantly boost the model's performance on new tasks, even when it had only been trained on a limited amount of data. This is an important finding because it shows how powerful language models can be at helping other AI systems learn new skills more efficiently.
The key insight is that the language model prompts are able to provide the Decision Transformer with valuable background knowledge and context that helps it make better decisions, even in unfamiliar environments. This demonstrates the potential for combining different AI techniques, like language modeling and reinforcement learning, to create more capable and versatile systems.
Technical Explanation
The paper investigates how pre-trained language models can be used to improve the few-shot prompt ability of the Decision Transformer model. The Decision Transformer is a reinforcement learning (RL) model that frames decision-making as a language modeling task, where the goal is to predict the sequence of actions that lead to the desired outcome.
The researchers hypothesized that providing the Decision Transformer with prompts generated by pre-trained language models could significantly improve its few-shot performance on downstream tasks. To test this, they conducted experiments across a range of environments, including MuJoCo control tasks and the Atari game suite.
The results showed that the Decision Transformer model with pre-trained language model prompts outperformed the standard Decision Transformer model, as well as other few-shot RL baselines, by a significant margin. The researchers attribute this performance boost to the language model's ability to provide the Decision Transformer with valuable contextual information and background knowledge that helps it make better decisions in the few-shot setting.
Critical Analysis
The paper presents a compelling approach to improving the few-shot performance of the Decision Transformer model through the use of pre-trained language model prompts. The researchers' findings suggest that this technique could be a valuable tool for building more sample-efficient RL systems, which is an important problem in the field.
However, the paper does not address potential limitations or drawbacks of this approach. For instance, it would be useful to understand the computational overhead and training time required to incorporate the language model prompts, as well as any potential negative interactions between the language model and the Decision Transformer architecture.
Additionally, the paper focuses on a limited set of environments and tasks. Further research would be needed to evaluate the generalizability of this approach across a wider range of domains and problem settings.
Finally, the paper does not explore the interpretability or transparency of the language model prompts and their influence on the Decision Transformer's decision-making process. This could be an important consideration, especially for applications where the model's reasoning needs to be understood and explained.
Conclusion
This paper demonstrates the potential for using pre-trained language models to significantly improve the few-shot prompt ability of the Decision Transformer model. The findings suggest that leveraging language model prompts can be a powerful technique for enhancing the sample efficiency and performance of RL systems, which could have important implications for a wide range of real-world applications.
While the paper provides a solid technical foundation, further research is needed to fully understand the limitations and broader implications of this approach. Nonetheless, this work represents an exciting step forward in the ongoing effort to develop more capable and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pre-trained Language Models Improve the Few-shot Prompt Ability of Decision Transformer
Yu Yang, Pan Xu
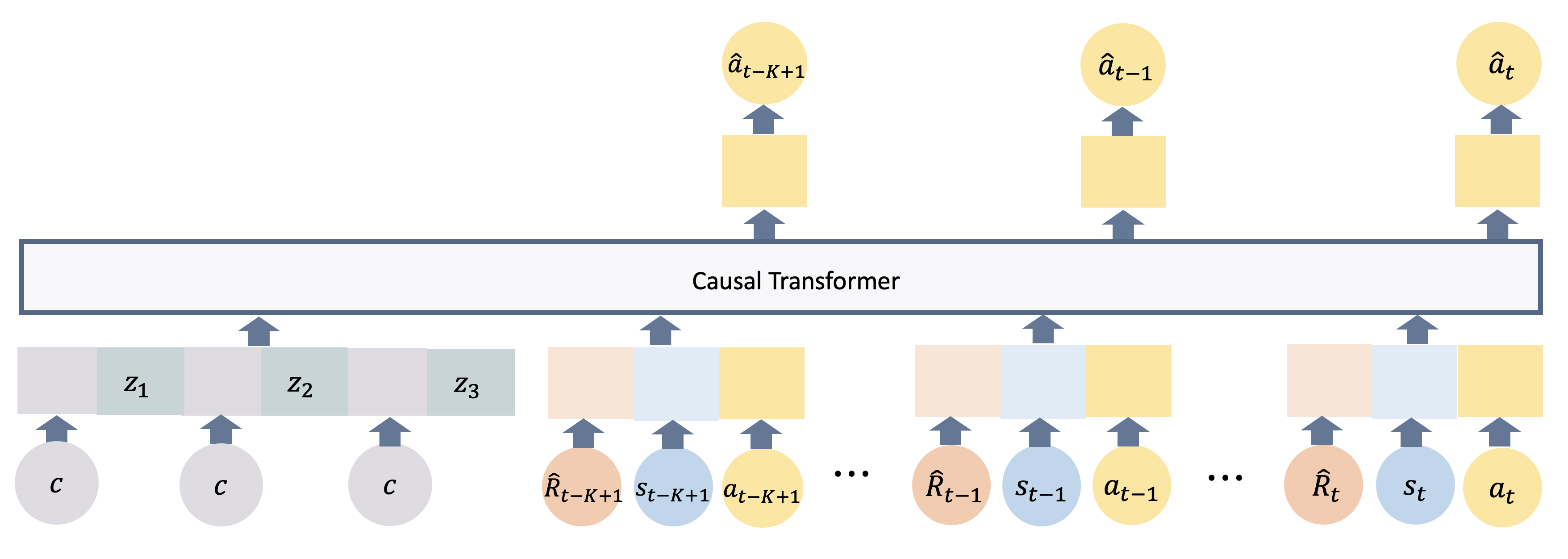
Decision Transformer (DT) has emerged as a promising class of algorithms in offline reinforcement learning (RL) tasks, leveraging pre-collected datasets and Transformer's capability to model long sequences. Recent works have demonstrated that using parts of trajectories from training tasks as prompts in DT enhances its performance on unseen tasks, giving rise to Prompt-DT methods. However, collecting data from specific environments can be both costly and unsafe in many scenarios, leading to suboptimal performance and limited few-shot prompt abilities due to the data-hungry nature of Transformer-based models. Additionally, the limited datasets used in pre-training make it challenging for Prompt-DT type of methods to distinguish between various RL tasks through prompts alone. To address these challenges, we introduce the Language model-initialized Prompt Decision Transformer (LPDT), which leverages pre-trained language models for meta-RL tasks and fine-tunes the model using Low-rank Adaptation (LoRA). We further incorporate prompt regularization to effectively differentiate between tasks based on prompt feature representations. Our approach integrates pre-trained language model and RL tasks seamlessly. Extensive empirical studies demonstrate that initializing with a pre-trained language model significantly enhances the performance of Prompt-DT on unseen tasks compared to baseline methods.
Read more8/6/2024
0
A Minimalist Prompt for Zero-Shot Policy Learning
Meng Song, Xuezhi Wang, Tanay Biradar, Yao Qin, Manmohan Chandraker
Transformer-based methods have exhibited significant generalization ability when prompted with target-domain demonstrations or example solutions during inference. Although demonstrations, as a way of task specification, can capture rich information that may be hard to specify by language, it remains unclear what information is extracted from the demonstrations to help generalization. Moreover, assuming access to demonstrations of an unseen task is impractical or unreasonable in many real-world scenarios, especially in robotics applications. These questions motivate us to explore what the minimally sufficient prompt could be to elicit the same level of generalization ability as the demonstrations. We study this problem in the contextural RL setting which allows for quantitative measurement of generalization and is commonly adopted by meta-RL and multi-task RL benchmarks. In this setting, the training and test Markov Decision Processes (MDPs) only differ in certain properties, which we refer to as task parameters. We show that conditioning a decision transformer on these task parameters alone can enable zero-shot generalization on par with or better than its demonstration-conditioned counterpart. This suggests that task parameters are essential for the generalization and DT models are trying to recover it from the demonstration prompt. To extract the remaining generalizable information from the supervision, we introduce an additional learnable prompt which is demonstrated to further boost zero-shot generalization across a range of robotic control, manipulation, and navigation benchmark tasks.
Read more5/13/2024
🗣️
0
New!PRE: Vision-Language Prompt Learning with Reparameterization Encoder
Thi Minh Anh Pham, An Duc Nguyen, Cephas Svosve, Vasileios Argyriou, Georgios Tzimiropoulos
Large pre-trained vision-language models such as CLIP have demonstrated great potential in zero-shot transferability to downstream tasks. However, to attain optimal performance, the manual selection of prompts is necessary to improve alignment between the downstream image distribution and the textual class descriptions. This manual prompt engineering is the major challenge for deploying such models in practice since it requires domain expertise and is extremely time-consuming. To avoid non-trivial prompt engineering, recent work Context Optimization (CoOp) introduced the concept of prompt learning to the vision domain using learnable textual tokens. While CoOp can achieve substantial improvements over manual prompts, its learned context is worse generalizable to wider unseen classes within the same dataset. In this work, we present Prompt Learning with Reparameterization Encoder (PRE) - a simple and efficient method that enhances the generalization ability of the learnable prompt to unseen classes while maintaining the capacity to learn Base classes. Instead of directly optimizing the prompts, PRE employs a prompt encoder to reparameterize the input prompt embeddings, enhancing the exploration of task-specific knowledge from few-shot samples. Experiments and extensive ablation studies on 8 benchmarks demonstrate that our approach is an efficient method for prompt learning. Specifically, PRE achieves a notable enhancement of 5.60% in average accuracy on New classes and 3% in Harmonic mean compared to CoOp in the 16-shot setting, all achieved within a good training time.
Read more9/17/2024

0
SpeechPrompt: Prompting Speech Language Models for Speech Processing Tasks
Kai-Wei Chang, Haibin Wu, Yu-Kai Wang, Yuan-Kuei Wu, Hua Shen, Wei-Cheng Tseng, Iu-thing Kang, Shang-Wen Li, Hung-yi Lee
Prompting has become a practical method for utilizing pre-trained language models (LMs). This approach offers several advantages. It allows an LM to adapt to new tasks with minimal training and parameter updates, thus achieving efficiency in both storage and computation. Additionally, prompting modifies only the LM's inputs and harnesses the generative capabilities of language models to address various downstream tasks in a unified manner. This significantly reduces the need for human labor in designing task-specific models. These advantages become even more evident as the number of tasks served by the LM scales up. Motivated by the strengths of prompting, we are the first to explore the potential of prompting speech LMs in the domain of speech processing. Recently, there has been a growing interest in converting speech into discrete units for language modeling. Our pioneer research demonstrates that these quantized speech units are highly versatile within our unified prompting framework. Not only can they serve as class labels, but they also contain rich phonetic information that can be re-synthesized back into speech signals for speech generation tasks. Specifically, we reformulate speech processing tasks into speech-to-unit generation tasks. As a result, we can seamlessly integrate tasks such as speech classification, sequence generation, and speech generation within a single, unified prompting framework. The experiment results show that the prompting method can achieve competitive performance compared to the strong fine-tuning method based on self-supervised learning models with a similar number of trainable parameters. The prompting method also shows promising results in the few-shot setting. Moreover, with the advanced speech LMs coming into the stage, the proposed prompting framework attains great potential.
Read more8/26/2024