Previously on ... From Recaps to Story Summarization
2405.11487
0
0

Abstract
We introduce multimodal story summarization by leveraging TV episode recaps - short video sequences interweaving key story moments from previous episodes to bring viewers up to speed. We propose PlotSnap, a dataset featuring two crime thriller TV shows with rich recaps and long episodes of 40 minutes. Story summarization labels are unlocked by matching recap shots to corresponding sub-stories in the episode. We propose a hierarchical model TaleSumm that processes entire episodes by creating compact shot and dialog representations, and predicts importance scores for each video shot and dialog utterance by enabling interactions between local story groups. Unlike traditional summarization, our method extracts multiple plot points from long videos. We present a thorough evaluation on story summarization, including promising cross-series generalization. TaleSumm also shows good results on classic video summarization benchmarks.
Create account to get full access
Overview
• This paper explores the task of story summarization, which involves generating concise and informative summaries of narrative content like TV shows and movies.
• The authors draw insights from the practice of "previously on" recaps, which provide viewers with a quick refresher on past events before the start of a new episode.
• The paper proposes techniques for automatically generating these types of summaries, which could have applications in areas like video streaming, entertainment, and education.
Plain English Explanation
The paper looks at how we can create short, helpful summaries of stories, like the plot of a TV show or movie. The authors are inspired by the "previously on" recaps that often play at the start of a new episode, which remind viewers of what happened before.
By studying these recaps, the researchers develop new methods to automatically generate similar summaries. This could be useful for things like video streaming services, where viewers might want a quick refresher on a show's plot. It could also have applications in education, where summarizing complex narratives could help students better understand the material.
The key idea is to capture the important events and details that move the story forward, and present them in a concise, easy-to-digest format. This could make it easier for people to follow along with stories, especially if they've missed previous episodes or haven't watched in a while.
Technical Explanation
The paper proposes techniques for automated story summarization, drawing insights from the practice of "previously on" recaps in TV shows. The authors frame this as a challenging multimodal task, requiring the integration of textual and visual information to identify the key narrative elements.
The paper presents a modular approach to multimodal summarization that first extracts relevant textual and visual features, then fuses them to generate the final summary. They also explore cross-modal summarization models that can directly map from video to text.
Additionally, the paper investigates techniques for scaling up video summarization through pretraining on large language models, as well as graph-based methods that leverage the temporal structure of videos.
Critical Analysis
The paper makes a compelling case for the importance of story summarization, and the proposed techniques represent a promising step forward. However, the authors acknowledge several limitations and areas for future work.
One key challenge is the subjective nature of summarization – different viewers may have different preferences for what information should be included. The authors suggest exploring personalized summarization models to address this.
Additionally, while the cross-modal techniques are effective, they rely on having access to both video and text data, which may not always be available. Further research is needed to explore summarization from a single modality.
Finally, the authors note that the current models are focused on summarizing individual episodes or stories, but extending these methods to handle longer-form narratives spanning multiple episodes or movies could be a valuable direction for future work.
Conclusion
This paper presents novel techniques for automatically generating story summaries, inspired by the "previously on" recaps commonly used in television. The proposed methods leverage multimodal data and advanced language models to capture the key narrative elements in a concise, informative format.
While the research has promising applications in areas like video streaming and education, it also highlights the inherent challenges of summarization, such as subjectivity and the need to handle longer-form narratives. Addressing these limitations could unlock new possibilities for intelligent story summarization systems that enhance our understanding and enjoyment of complex narratives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
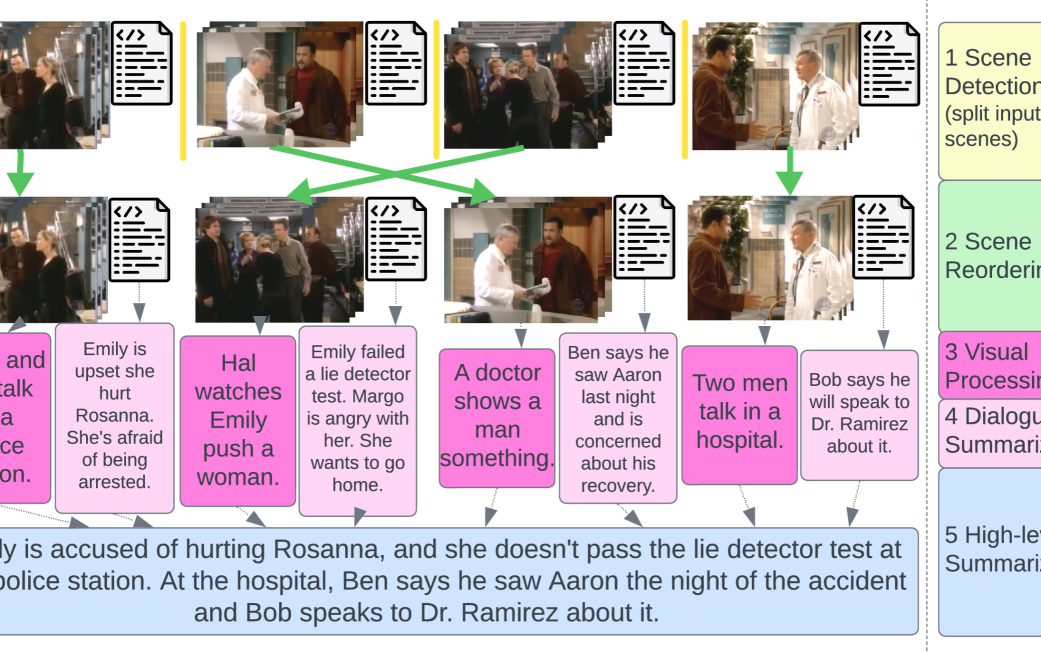
A Modular Approach for Multimodal Summarization of TV Shows
Louis Mahon, Mirella Lapata
0
0
In this paper we address the task of summarizing television shows, which touches key areas in AI research: complex reasoning, multiple modalities, and long narratives. We present a modular approach where separate components perform specialized sub-tasks which we argue affords greater flexibility compared to end-to-end methods. Our modules involve detecting scene boundaries, reordering scenes so as to minimize the number of cuts between different events, converting visual information to text, summarizing the dialogue in each scene, and fusing the scene summaries into a final summary for the entire episode. We also present a new metric, PREFS (Precision and Recall Evaluation of Summary FactS), to measure both precision and recall of generated summaries, which we decompose into atomic facts. Tested on the recently released SummScreen3D dataset Papalampidi and Lapata (2023), our method produces higher quality summaries than comparison models, as measured with ROUGE and our new fact-based metric.
6/17/2024
❗
VideoXum: Cross-modal Visual and Textural Summarization of Videos
Jingyang Lin, Hang Hua, Ming Chen, Yikang Li, Jenhao Hsiao, Chiuman Ho, Jiebo Luo
0
0
Video summarization aims to distill the most important information from a source video to produce either an abridged clip or a textual narrative. Traditionally, different methods have been proposed depending on whether the output is a video or text, thus ignoring the correlation between the two semantically related tasks of visual summarization and textual summarization. We propose a new joint video and text summarization task. The goal is to generate both a shortened video clip along with the corresponding textual summary from a long video, collectively referred to as a cross-modal summary. The generated shortened video clip and text narratives should be semantically well aligned. To this end, we first build a large-scale human-annotated dataset -- VideoXum (X refers to different modalities). The dataset is reannotated based on ActivityNet. After we filter out the videos that do not meet the length requirements, 14,001 long videos remain in our new dataset. Each video in our reannotated dataset has human-annotated video summaries and the corresponding narrative summaries. We then design a novel end-to-end model -- VTSUM-BILP to address the challenges of our proposed task. Moreover, we propose a new metric called VT-CLIPScore to help evaluate the semantic consistency of cross-modality summary. The proposed model achieves promising performance on this new task and establishes a benchmark for future research.
4/24/2024
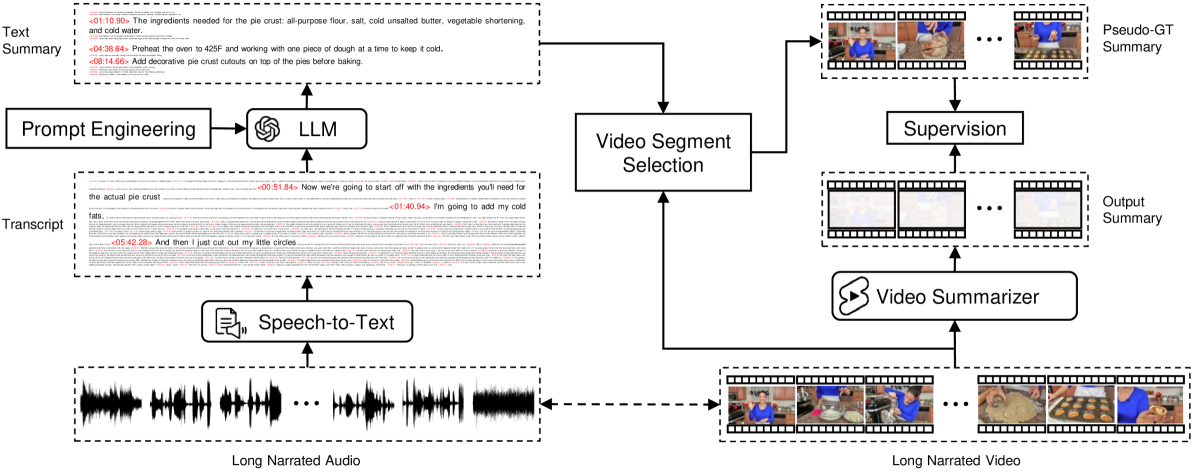
Scaling Up Video Summarization Pretraining with Large Language Models
Dawit Mureja Argaw, Seunghyun Yoon, Fabian Caba Heilbron, Hanieh Deilamsalehy, Trung Bui, Zhaowen Wang, Franck Dernoncourt, Joon Son Chung
0
0
Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
4/5/2024
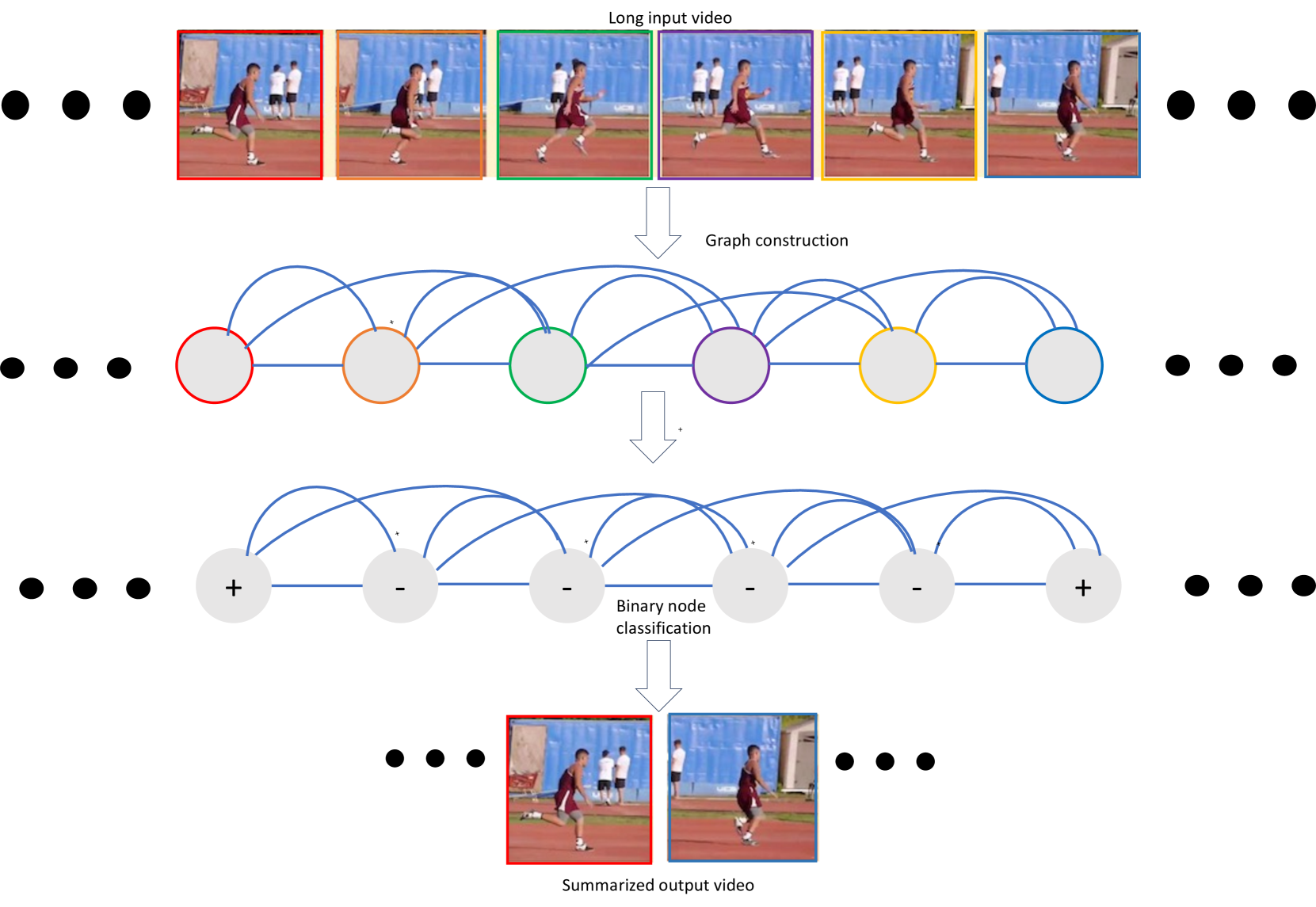
VideoSAGE: Video Summarization with Graph Representation Learning
Jose M. Rojas Chaves, Subarna Tripathi
0
0
We propose a graph-based representation learning framework for video summarization. First, we convert an input video to a graph where nodes correspond to each of the video frames. Then, we impose sparsity on the graph by connecting only those pairs of nodes that are within a specified temporal distance. We then formulate the video summarization task as a binary node classification problem, precisely classifying video frames whether they should belong to the output summary video. A graph constructed this way aims to capture long-range interactions among video frames, and the sparsity ensures the model trains without hitting the memory and compute bottleneck. Experiments on two datasets(SumMe and TVSum) demonstrate the effectiveness of the proposed nimble model compared to existing state-of-the-art summarization approaches while being one order of magnitude more efficient in compute time and memory
4/17/2024