VideoSAGE: Video Summarization with Graph Representation Learning

0
Sign in to get full access
Overview
- The paper proposes a novel video summarization method called VideoSAGE that uses graph representation learning to capture the temporal and semantic relationships in video content.
- VideoSAGE generates a compact summary by selecting the most informative and representative video frames based on their importance and relevance.
- The method leverages a graph neural network to learn video representations that encode the complex temporal and semantic dependencies between video frames.
- Experiments on benchmark video summarization datasets show that VideoSAGE outperforms state-of-the-art approaches in terms of summary quality and efficiency.
Plain English Explanation
VideoSAGE is a new method for automatically creating video summaries. It works by analyzing the content of a video and identifying the most important and relevant parts to include in a shortened version.
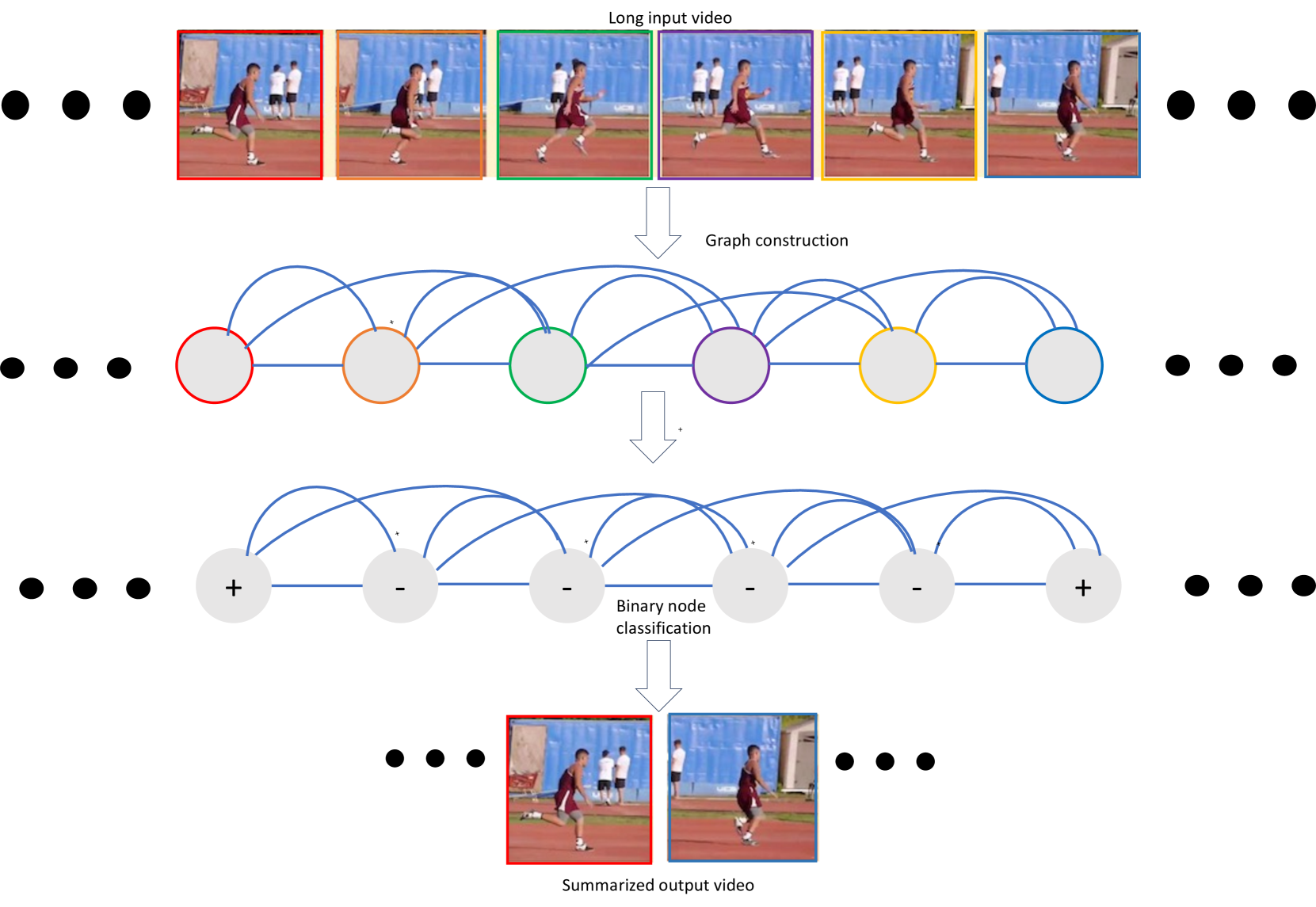
The key idea behind VideoSAGE is to represent the video as a graph, where each video frame is a node and the connections between nodes capture the temporal and semantic relationships between frames. This graph-based representation allows the method to learn a deep understanding of the video content and its structure.
Based on this graph representation, VideoSAGE can then select the most informative and representative frames to include in the summary. The selected frames are the ones that are most central and connected to the overall video, ensuring the summary captures the essential elements of the original video.
Compared to other video summarization approaches, VideoSAGE is able to produce high-quality summaries that are more concise and informative. This makes it a powerful tool for quickly browsing and understanding long, complex videos, such as news reports, tutorial videos, or documentaries.
Technical Explanation
The core of VideoSAGE is a graph neural network that learns a compact representation of the video content. The input to the model is a sequence of video frames, and the output is a graph-based encoding that captures the temporal and semantic relationships between the frames.
To construct the graph, the method first extracts visual features from each video frame using a pretrained convolutional neural network. These visual features form the nodes of the graph. The edges between nodes are then determined based on the temporal ordering of the frames and their semantic similarity, as measured by the cosine distance between their feature vectors.
The graph neural network then learns to propagate information across the graph, updating the node representations to reflect the complex dependencies in the video. This allows the model to reason about the importance and relevance of each frame in the context of the entire video.
Finally, the summarization module selects the most informative frames to include in the summary. This is done by ranking the nodes in the graph based on a combination of their individual importance and their centrality within the graph structure. The top-ranked frames are then extracted to form the final video summary.
The authors evaluate VideoSAGE on several benchmark video summarization datasets and show that it outperforms state-of-the-art methods in terms of summary quality and efficiency. The graph-based representation learning approach proves to be a powerful way to capture the nuances of video content and generate concise, informative summaries.
Critical Analysis
The VideoSAGE paper presents a compelling approach to video summarization that leverages graph representation learning to model the complex temporal and semantic relationships in video content. The authors have carefully designed the graph construction and neural network architecture to effectively capture the important elements of a video and generate high-quality summaries.
One potential limitation of the method is that it relies on pretrained visual feature extractors, which may not be optimal for all types of video content. Incorporating end-to-end trainable feature extraction could potentially improve the video understanding capabilities of the model.
Additionally, the paper does not provide a detailed analysis of the types of videos that VideoSAGE performs best on or the failure modes of the method. It would be interesting to see how the approach handles diverse video genres, such as Enhancing Video Summarization with Context Awareness, or videos with complex temporal dynamics.
Finally, the authors mention the potential for applying VideoSAGE to large-scale video datasets, but do not provide any experiments or insights on the scalability of the method. Exploring the scaling challenges and potential solutions would be a valuable direction for future research.
Overall, the VideoSAGE paper presents a compelling and innovative approach to video summarization that could have significant practical applications. Further research into the method's robustness, generalizability, and scalability would help solidify its contributions to the field.
Conclusion
The VideoSAGE paper introduces a novel video summarization method that leverages graph representation learning to capture the complex temporal and semantic relationships in video content. By representing videos as graphs and learning informative node embeddings, the approach is able to generate high-quality video summaries that concisely capture the most relevant and important elements.
The key innovation of VideoSAGE is its ability to reason about the video at a deeper, more holistic level, going beyond simple frame selection to understand the underlying structure and dependencies in the data. This graph-based understanding enables the method to produce summaries that are both informative and compact, making it a powerful tool for efficiently browsing and understanding long, complex videos.
The strong performance of VideoSAGE on benchmark datasets, coupled with its potential for scalability and generalizability, suggests that the approach could have significant real-world impact in a variety of domains, from video-based question answering to social interaction analysis. As video content continues to proliferate, tools like VideoSAGE will become increasingly valuable for making sense of the vast amounts of information at our fingertips.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VideoSAGE: Video Summarization with Graph Representation Learning
Jose M. Rojas Chaves, Subarna Tripathi
We propose a graph-based representation learning framework for video summarization. First, we convert an input video to a graph where nodes correspond to each of the video frames. Then, we impose sparsity on the graph by connecting only those pairs of nodes that are within a specified temporal distance. We then formulate the video summarization task as a binary node classification problem, precisely classifying video frames whether they should belong to the output summary video. A graph constructed this way aims to capture long-range interactions among video frames, and the sparsity ensures the model trains without hitting the memory and compute bottleneck. Experiments on two datasets(SumMe and TVSum) demonstrate the effectiveness of the proposed nimble model compared to existing state-of-the-art summarization approaches while being one order of magnitude more efficient in compute time and memory
Read more4/17/2024
🤿
0
Enhancing Video Summarization with Context Awareness
Hai-Dang Huynh-Lam, Ngoc-Phuong Ho-Thi, Minh-Triet Tran, Trung-Nghia Le
Video summarization is a crucial research area that aims to efficiently browse and retrieve relevant information from the vast amount of video content available today. With the exponential growth of multimedia data, the ability to extract meaningful representations from videos has become essential. Video summarization techniques automatically generate concise summaries by selecting keyframes, shots, or segments that capture the video's essence. This process improves the efficiency and accuracy of various applications, including video surveillance, education, entertainment, and social media. Despite the importance of video summarization, there is a lack of diverse and representative datasets, hindering comprehensive evaluation and benchmarking of algorithms. Existing evaluation metrics also fail to fully capture the complexities of video summarization, limiting accurate algorithm assessment and hindering the field's progress. To overcome data scarcity challenges and improve evaluation, we propose an unsupervised approach that leverages video data structure and information for generating informative summaries. By moving away from fixed annotations, our framework can produce representative summaries effectively. Moreover, we introduce an innovative evaluation pipeline tailored specifically for video summarization. Human participants are involved in the evaluation, comparing our generated summaries to ground truth summaries and assessing their informativeness. This human-centric approach provides valuable insights into the effectiveness of our proposed techniques. Experimental results demonstrate that our training-free framework outperforms existing unsupervised approaches and achieves competitive results compared to state-of-the-art supervised methods.
Read more4/9/2024
🌀
0
Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching Considering the Diversity of the Video
Tomoya Sugihara, Shuntaro Masuda, Ling Xiao, Toshihiko Yamasaki
Current video summarization methods rely heavily on supervised computer vision techniques, which demands time-consuming and subjective manual annotations. To overcome these limitations, we investigated self-supervised video summarization. Inspired by the success of Large Language Models (LLMs), we explored the feasibility in transforming the video summarization task into a Natural Language Processing (NLP) task. By leveraging the advantages of LLMs in context understanding, we aim to enhance the effectiveness of self-supervised video summarization. Our method begins by generating captions for individual video frames, which are then synthesized into text summaries by LLMs. Subsequently, we measure semantic distance between the captions and the text summary. Notably, we propose a novel loss function to optimize our model according to the diversity of the video. Finally, the summarized video can be generated by selecting the frames with captions similar to the text summary. Our method achieves state-of-the-art performance on the SumMe dataset in rank correlation coefficients. In addition, our method has a novel feature of being able to achieve personalized summarization.
Read more8/21/2024

0
SANGRIA: Surgical Video Scene Graph Optimization for Surgical Workflow Prediction
c{C}au{g}han Koksal, Ghazal Ghazaei, Felix Holm, Azade Farshad, Nassir Navab
Graph-based holistic scene representations facilitate surgical workflow understanding and have recently demonstrated significant success. However, this task is often hindered by the limited availability of densely annotated surgical scene data. In this work, we introduce an end-to-end framework for the generation and optimization of surgical scene graphs on a downstream task. Our approach leverages the flexibility of graph-based spectral clustering and the generalization capability of foundation models to generate unsupervised scene graphs with learnable properties. We reinforce the initial spatial graph with sparse temporal connections using local matches between consecutive frames to predict temporally consistent clusters across a temporal neighborhood. By jointly optimizing the spatiotemporal relations and node features of the dynamic scene graph with the downstream task of phase segmentation, we address the costly and annotation-burdensome task of semantic scene comprehension and scene graph generation in surgical videos using only weak surgical phase labels. Further, by incorporating effective intermediate scene representation disentanglement steps within the pipeline, our solution outperforms the SOTA on the CATARACTS dataset by 8% accuracy and 10% F1 score in surgical workflow recognition
Read more7/30/2024