A Modular Approach for Multimodal Summarization of TV Shows
2403.03823
0
0
Abstract
In this paper we address the task of summarizing television shows, which touches key areas in AI research: complex reasoning, multiple modalities, and long narratives. We present a modular approach where separate components perform specialized sub-tasks which we argue affords greater flexibility compared to end-to-end methods. Our modules involve detecting scene boundaries, reordering scenes so as to minimize the number of cuts between different events, converting visual information to text, summarizing the dialogue in each scene, and fusing the scene summaries into a final summary for the entire episode. We also present a new metric, PREFS (Precision and Recall Evaluation of Summary FactS), to measure both precision and recall of generated summaries, which we decompose into atomic facts. Tested on the recently released SummScreen3D dataset Papalampidi and Lapata (2023), our method produces higher quality summaries than comparison models, as measured with ROUGE and our new fact-based metric.
Create account to get full access
Overview
- This paper presents a modular approach for multimodal summarization of TV shows, which aims to generate summaries that combine textual and visual information.
- The proposed method decomposes the multimodal summarization task into several interconnected modules, including video scene segmentation, key frame extraction, visual-textual feature extraction, and summary generation.
- The authors evaluate their approach on a dataset of TV shows and demonstrate its effectiveness compared to existing text-only and multimodal summarization methods.
Plain English Explanation
The paper discusses a new way to automatically generate summaries of TV shows that combine both text and visuals. Traditional text-only summarization methods often miss important visual information, while existing multimodal approaches can be complex and difficult to apply.
The researchers developed a modular system that breaks down the summarization task into several smaller, interconnected components. First, the system analyzes the video to identify key scenes and frames. It then extracts relevant features from both the text and visual content. Finally, it uses these features to generate a concise summary that captures the most important information from the show.
By separating the task into these modular components, the researchers were able to create a more flexible and effective summarization system. They tested their approach on a dataset of TV shows and found that it outperformed existing text-only and multimodal summarization methods.
This work could be useful for [link to "https://aimodels.fyi/papers/arxiv/characterizing-multimodal-long-form-summarization-case-study"](characterizing multimodal long-form summarization) or [link to "https://aimodels.fyi/papers/arxiv/videoxum-cross-modal-visual-textural-summarization-videos"](cross-modal video summarization), as it demonstrates a novel way to combine textual and visual information to generate high-quality summaries. It could also inform the development of [link to "https://aimodels.fyi/papers/arxiv/qfmts-generating-query-focused-summaries-over-multi"](query-focused multi-modal summarization) or [link to "https://aimodels.fyi/papers/arxiv/language-guided-self-supervised-video-summarization-using"](self-supervised video summarization) systems.
Technical Explanation
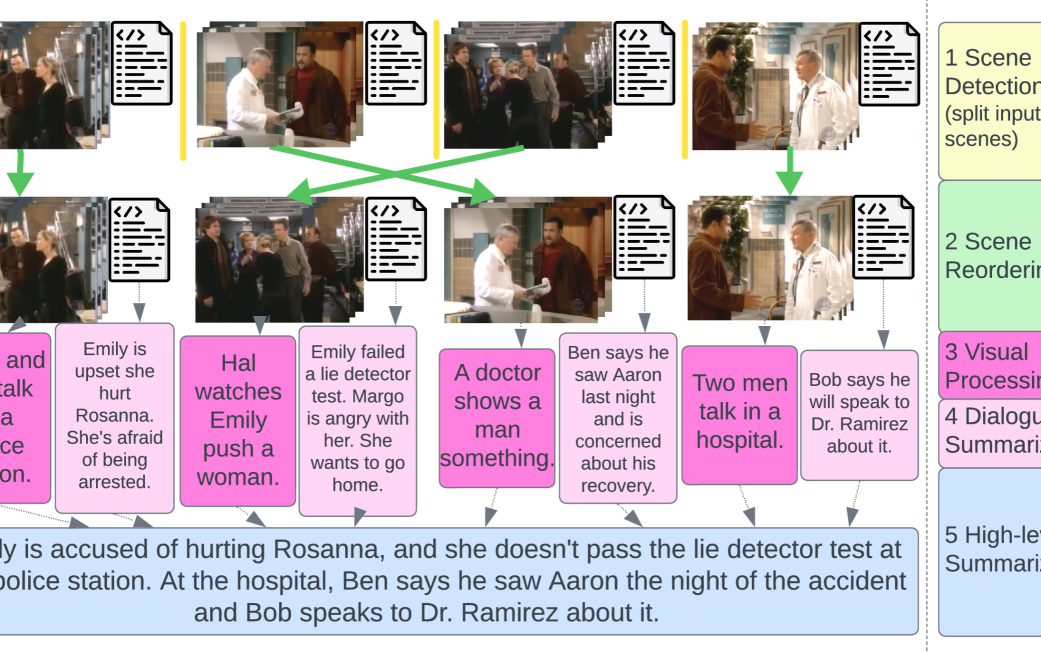
The paper proposes a modular approach for multimodal summarization of TV shows, which decomposes the task into several interconnected components:
-
Video Scene Segmentation: The system first segments the video into individual scenes using a neural network-based scene detection model.
-
Key Frame Extraction: It then selects a set of key frames from each scene that best represent the visual content.
-
Visual-Textual Feature Extraction: The system extracts relevant features from both the textual dialogue and the visual frames using pre-trained neural networks.
-
Summary Generation: Finally, the system combines the extracted features to generate a concise textual summary of the TV show using an abstractive summarization model.
The authors evaluate their approach on a dataset of TV shows and compare it to both text-only and multimodal summarization baselines. They find that their modular approach outperforms the other methods in terms of both textual and visual coverage of the summaries.
Critical Analysis
The paper presents a novel and promising approach to multimodal summarization of TV shows. By decomposing the task into modular components, the researchers are able to leverage existing techniques for video processing, feature extraction, and text summarization, while also introducing novel ways to combine these elements.
However, the authors do acknowledge several limitations of their work. For example, the performance of the system is still not at human level, and the summarization quality may be affected by errors in the individual modules (e.g., scene detection, key frame selection). Additionally, the approach is evaluated on a single dataset of TV shows, so its generalizability to other types of multimodal content (e.g., link to "https://aimodels.fyi/papers/arxiv/videoxum-cross-modal-visual-textural-summarization-videos", link to "https://aimodels.fyi/papers/arxiv/language-guided-self-supervised-video-summarization-using") is not fully established.
Further research could explore ways to improve the robustness and accuracy of the individual modules, as well as investigate techniques for better integrating the textual and visual information during the summary generation process. Exploring the application of this modular approach to [link to "https://aimodels.fyi/papers/arxiv/qfmts-generating-query-focused-summaries-over-multi"](query-focused multimodal summarization) could also be a fruitful area of study.
Conclusion
This paper presents a modular approach for multimodal summarization of TV shows that combines textual and visual information to generate comprehensive summaries. By breaking down the task into interconnected components, the researchers were able to leverage existing techniques and introduce novel methods for integrating the textual and visual modalities.
The authors' evaluation demonstrates the effectiveness of their approach compared to text-only and multimodal baselines, suggesting that this modular framework could be a valuable contribution to the field of [link to "https://aimodels.fyi/papers/arxiv/characterizing-multimodal-long-form-summarization-case-study"](multimodal long-form summarization). Further research is needed to improve the robustness and generalizability of the system, but this work represents an important step towards more comprehensive and effective summarization of complex, multimodal media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Previously on ... From Recaps to Story Summarization
Aditya Kumar Singh, Dhruv Srivastava, Makarand Tapaswi
0
0
We introduce multimodal story summarization by leveraging TV episode recaps - short video sequences interweaving key story moments from previous episodes to bring viewers up to speed. We propose PlotSnap, a dataset featuring two crime thriller TV shows with rich recaps and long episodes of 40 minutes. Story summarization labels are unlocked by matching recap shots to corresponding sub-stories in the episode. We propose a hierarchical model TaleSumm that processes entire episodes by creating compact shot and dialog representations, and predicts importance scores for each video shot and dialog utterance by enabling interactions between local story groups. Unlike traditional summarization, our method extracts multiple plot points from long videos. We present a thorough evaluation on story summarization, including promising cross-series generalization. TaleSumm also shows good results on classic video summarization benchmarks.
5/21/2024
Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
Pranav Janjani, Mayank Palan, Sarvesh Shirude, Ninad Shegokar, Sunny Kumar, Faruk Kazi
0
0
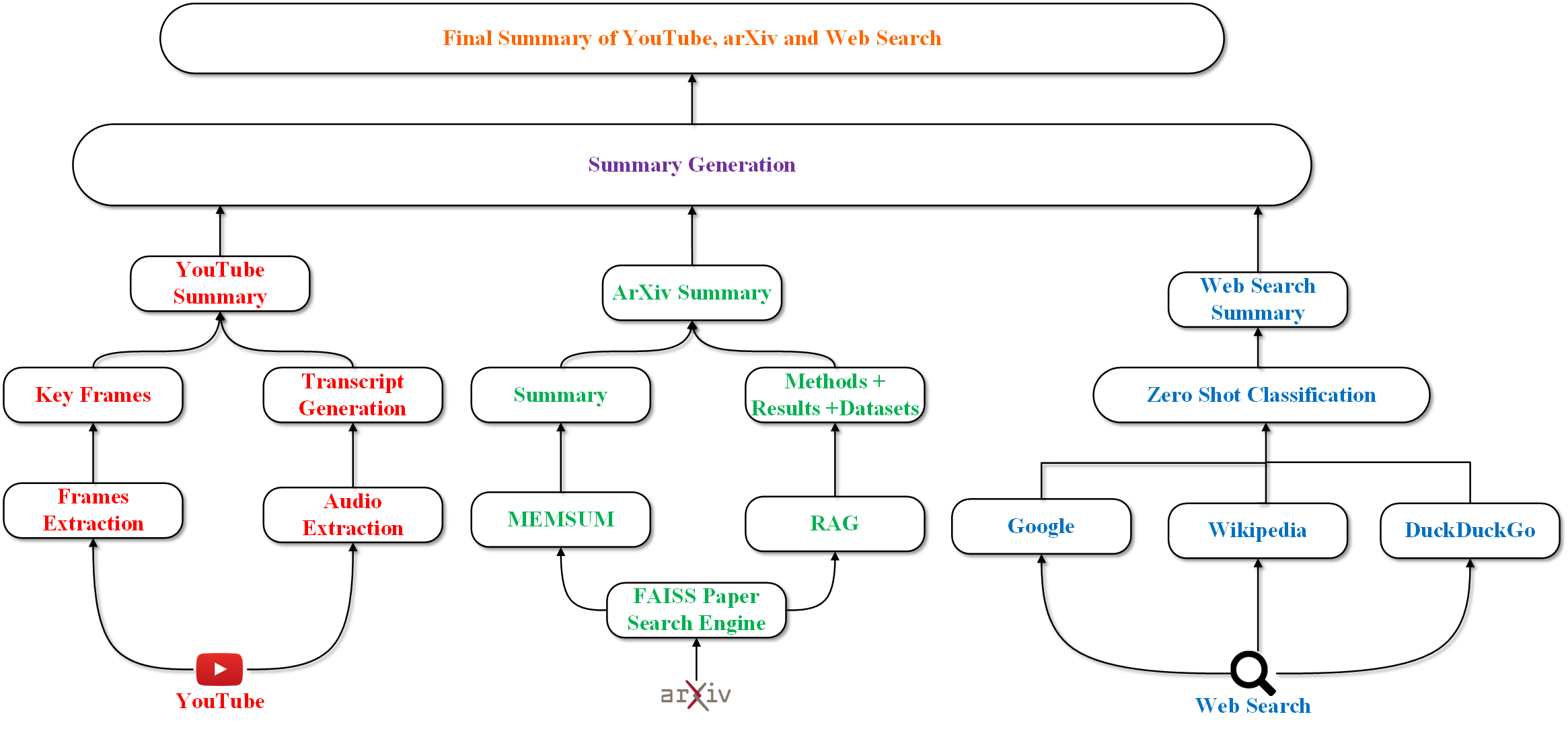
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.
6/21/2024
Characterizing Multimodal Long-form Summarization: A Case Study on Financial Reports
Tianyu Cao, Natraj Raman, Danial Dervovic, Chenhao Tan
0
0
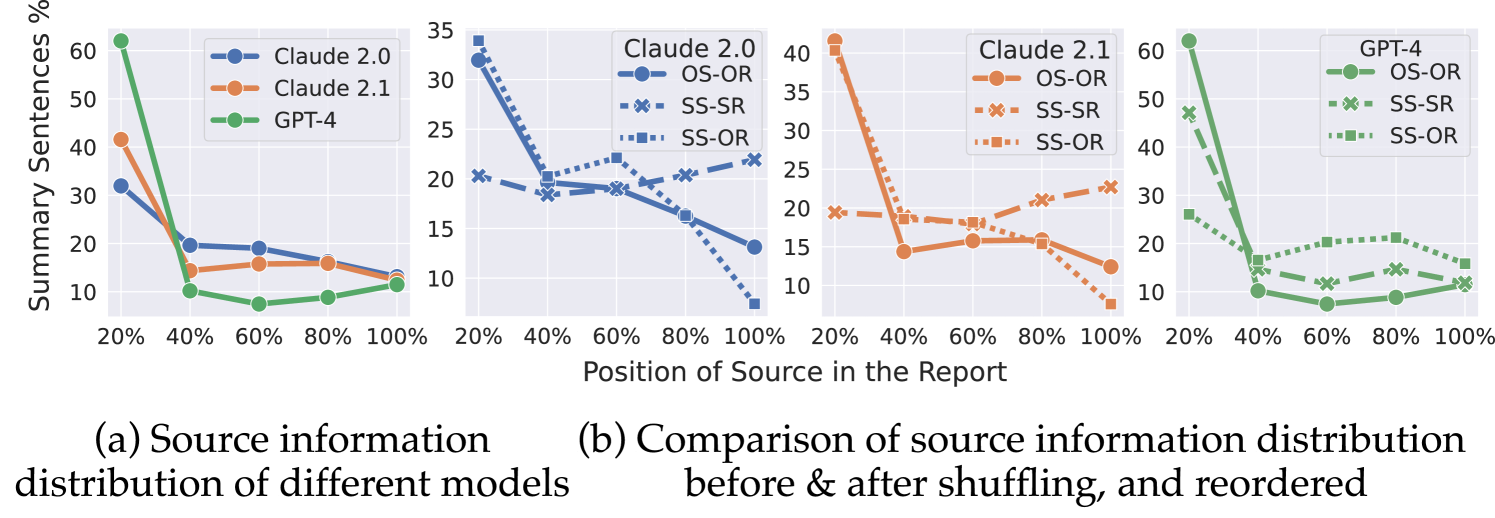
As large language models (LLMs) expand the power of natural language processing to handle long inputs, rigorous and systematic analyses are necessary to understand their abilities and behavior. A salient application is summarization, due to its ubiquity and controversy (e.g., researchers have declared the death of summarization). In this paper, we use financial report summarization as a case study because financial reports not only are long but also use numbers and tables extensively. We propose a computational framework for characterizing multimodal long-form summarization and investigate the behavior of Claude 2.0/2.1, GPT-4/3.5, and Command. We find that GPT-3.5 and Command fail to perform this summarization task meaningfully. For Claude 2 and GPT-4, we analyze the extractiveness of the summary and identify a position bias in LLMs. This position bias disappears after shuffling the input for Claude, which suggests that Claude has the ability to recognize important information. We also conduct a comprehensive investigation on the use of numeric data in LLM-generated summaries and offer a taxonomy of numeric hallucination. We employ prompt engineering to improve GPT-4's use of numbers with limited success. Overall, our analyses highlight the strong capability of Claude 2 in handling long multimodal inputs compared to GPT-4.
5/9/2024
❗
VideoXum: Cross-modal Visual and Textural Summarization of Videos
Jingyang Lin, Hang Hua, Ming Chen, Yikang Li, Jenhao Hsiao, Chiuman Ho, Jiebo Luo
0
0
Video summarization aims to distill the most important information from a source video to produce either an abridged clip or a textual narrative. Traditionally, different methods have been proposed depending on whether the output is a video or text, thus ignoring the correlation between the two semantically related tasks of visual summarization and textual summarization. We propose a new joint video and text summarization task. The goal is to generate both a shortened video clip along with the corresponding textual summary from a long video, collectively referred to as a cross-modal summary. The generated shortened video clip and text narratives should be semantically well aligned. To this end, we first build a large-scale human-annotated dataset -- VideoXum (X refers to different modalities). The dataset is reannotated based on ActivityNet. After we filter out the videos that do not meet the length requirements, 14,001 long videos remain in our new dataset. Each video in our reannotated dataset has human-annotated video summaries and the corresponding narrative summaries. We then design a novel end-to-end model -- VTSUM-BILP to address the challenges of our proposed task. Moreover, we propose a new metric called VT-CLIPScore to help evaluate the semantic consistency of cross-modality summary. The proposed model achieves promising performance on this new task and establishes a benchmark for future research.
4/24/2024