Primal Dual Continual Learning: Balancing Stability and Plasticity through Adaptive Memory Allocation
2310.00154
0
0

Abstract
Continual learning is inherently a constrained learning problem. The goal is to learn a predictor under a no-forgetting requirement. Although several prior studies formulate it as such, they do not solve the constrained problem explicitly. In this work, we show that it is both possible and beneficial to undertake the constrained optimization problem directly. To do this, we leverage recent results in constrained learning through Lagrangian duality. We focus on memory-based methods, where a small subset of samples from previous tasks can be stored in a replay buffer. In this setting, we analyze two versions of the continual learning problem: a coarse approach with constraints at the task level and a fine approach with constraints at the sample level. We show that dual variables indicate the sensitivity of the optimal value of the continual learning problem with respect to constraint perturbations. We then leverage this result to partition the buffer in the coarse approach, allocating more resources to harder tasks, and to populate the buffer in the fine approach, including only impactful samples. We derive a deviation bound on dual variables as sensitivity indicators, and empirically corroborate this result in diverse continual learning benchmarks. We also discuss the limitations of these methods with respect to the amount of memory available and the expressiveness of the parametrization.
Create account to get full access
Overview
- This paper proposes a new approach for continual learning called Primal-Dual Continual Learning (PDCL) that uses Lagrange multipliers to balance stability and plasticity.
- PDCL formulates continual learning as a constrained optimization problem and uses a primal-dual optimization strategy to solve it.
- The authors show that PDCL can outperform existing continual learning methods on several benchmark tasks.
Plain English Explanation
Continual learning is the ability of an AI system to learn new information over time without forgetting what it has learned previously. This is a challenging problem because neural networks tend to "catastrophically forget" old information when learning new things.
The key idea behind PDCL is to view continual learning as an optimization problem with constraints. Specifically, the system needs to minimize the loss on the current task while also maintaining performance on previous tasks. The authors use Lagrange multipliers, a mathematical technique, to balance these competing objectives.
The primal-dual optimization strategy means the system has two main components: a "primal" part that tries to minimize the current task loss, and a "dual" part that adjusts the Lagrange multipliers to enforce the constraints from previous tasks. By iterating between these two components, the system can learn new information while preserving old knowledge.
This approach allows PDCL to be more flexible and adaptable than prior continual learning methods, which often rely on fixed strategies like memory replay or parameter isolation. PDCL can dynamically adjust its priorities as it encounters new tasks, leading to better overall performance.
Technical Explanation
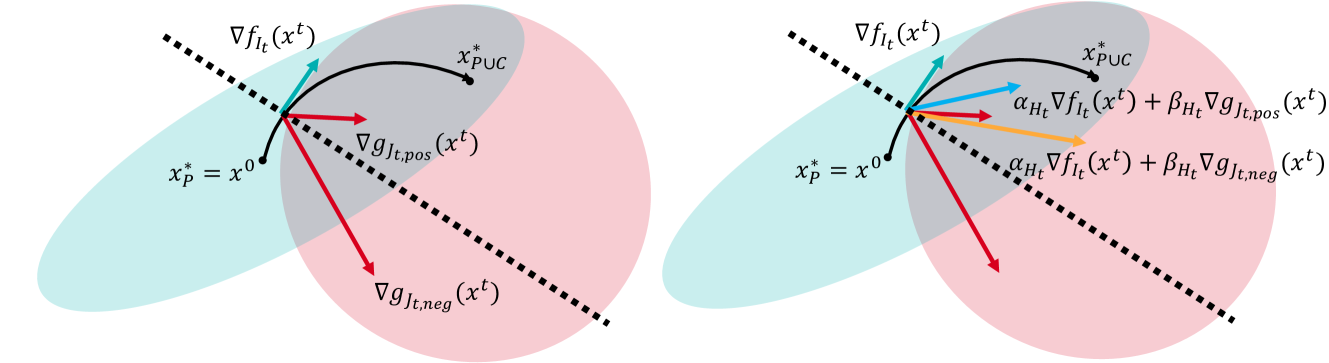
The authors frame continual learning as a constrained optimization problem, where the goal is to minimize the loss on the current task while satisfying constraints that preserve performance on previous tasks. Specifically, they define the following objective function:
min L_t(θ)
s.t. L_i(θ) ≤ L_i(θ_i^*) + ε, for i = 1, ..., t-1
Here, L_t(θ) is the loss on the current task t, θ are the model parameters, L_i(θ) is the loss on previous task i, θ_i^* are the optimal parameters for task i, and ε is a small tolerance.
To solve this constrained optimization problem, the authors use a primal-dual optimization strategy. The "primal" part updates the model parameters θ to minimize the current task loss L_t(θ), while the "dual" part updates Lagrange multipliers λ to enforce the constraints from previous tasks.
This primal-dual optimization is performed iteratively, allowing the system to continuously adapt its priorities between stability (preserving old knowledge) and plasticity (learning new information). The authors show that this approach can outperform existing continual learning methods on several benchmark tasks.
Critical Analysis
The authors provide a thorough theoretical analysis of their PDCL approach, including proofs of convergence and stability guarantees. However, the practical implementation and hyperparameter tuning required for PDCL may be more complex than some simpler continual learning methods.
Additionally, the authors only evaluate PDCL on supervised learning tasks, and it's unclear how well the approach would generalize to other continual learning settings, such as reinforcement learning or multi-modal dynamics with external memory.
Further research is needed to explore the limitations of PDCL, such as its scalability to larger models and datasets, as well as its robustness to distribution shifts and data-aware parameter-aware perturbations. Techniques like adaptive memory replay could potentially be integrated with PDCL to enhance its performance and flexibility.
Conclusion
Overall, this paper presents a novel and theoretically grounded approach to continual learning called Primal-Dual Continual Learning (PDCL). By formulating continual learning as a constrained optimization problem and using a primal-dual strategy to solve it, PDCL can effectively balance the stability and plasticity required for successful lifelong learning.
The results demonstrate that PDCL can outperform existing continual learning methods, suggesting that this approach could be a valuable tool for developing more robust and adaptable AI systems. Further research is needed to fully understand the strengths, weaknesses, and broader applicability of PDCL, but this work represents an important step forward in the field of continual learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On the Convergence of Continual Learning with Adaptive Methods
Seungyub Han, Yeongmo Kim, Taehyun Cho, Jungwoo Lee
0
0
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
4/16/2024

Maintaining Plasticity in Deep Continual Learning
Shibhansh Dohare, J. Fernando Hernandez-Garcia, Parash Rahman, A. Rupam Mahmood, Richard S. Sutton
0
0
Modern deep-learning systems are specialized to problem settings in which training occurs once and then never again, as opposed to continual-learning settings in which training occurs continually. If deep-learning systems are applied in a continual learning setting, then it is well known that they may fail to remember earlier examples. More fundamental, but less well known, is that they may also lose their ability to learn on new examples, a phenomenon called loss of plasticity. We provide direct demonstrations of loss of plasticity using the MNIST and ImageNet datasets repurposed for continual learning as sequences of tasks. In ImageNet, binary classification performance dropped from 89% accuracy on an early task down to 77%, about the level of a linear network, on the 2000th task. Loss of plasticity occurred with a wide range of deep network architectures, optimizers, activation functions, batch normalization, dropout, but was substantially eased by L2-regularization, particularly when combined with weight perturbation. Further, we introduce a new algorithm -- continual backpropagation -- which slightly modifies conventional backpropagation to reinitialize a small fraction of less-used units after each example and appears to maintain plasticity indefinitely.
4/11/2024
➖
Continual Learning of Multi-modal Dynamics with External Memory
Abdullah Akgul, Gozde Unal, Melih Kandemir
0
0
We study the problem of fitting a model to a dynamical environment when new modes of behavior emerge sequentially. The learning model is aware when a new mode appears, but it cannot access the true modes of individual training sequences. The state-of-the-art continual learning approaches cannot handle this setup, because parameter transfer suffers from catastrophic interference and episodic memory design requires the knowledge of the ground-truth modes of sequences. We devise a novel continual learning method that overcomes both limitations by maintaining a textit{descriptor} of the mode of an encountered sequence in a neural episodic memory. We employ a Dirichlet Process prior on the attention weights of the memory to foster efficient storage of the mode descriptors. Our method performs continual learning by transferring knowledge across tasks by retrieving the descriptors of similar modes of past tasks to the mode of a current sequence and feeding this descriptor into its transition kernel as control input. We observe the continual learning performance of our method to compare favorably to the mainstream parameter transfer approach.
5/10/2024
🧠
Two Complementary Perspectives to Continual Learning: Ask Not Only What to Optimize, But Also How
Timm Hess, Tinne Tuytelaars, Gido M. van de Ven
0
0
Recent years have seen considerable progress in the continual training of deep neural networks, predominantly thanks to approaches that add replay or regularization terms to the loss function to approximate the joint loss over all tasks so far. However, we show that even with a perfect approximation to the joint loss, these approaches still suffer from temporary but substantial forgetting when starting to train on a new task. Motivated by this 'stability gap', we propose that continual learning strategies should focus not only on the optimization objective, but also on the way this objective is optimized. While there is some continual learning work that alters the optimization trajectory (e.g., using gradient projection techniques), this line of research is positioned as alternative to improving the optimization objective, while we argue it should be complementary. In search of empirical support for our proposition, we perform a series of pre-registered experiments combining replay-approximated joint objectives with gradient projection-based optimization routines. However, this first experimental attempt fails to show clear and consistent benefits. Nevertheless, our conceptual arguments, as well as some of our empirical results, demonstrate the distinctive importance of the optimization trajectory in continual learning, thereby opening up a new direction for continual learning research.
6/24/2024