PrivSGP-VR: Differentially Private Variance-Reduced Stochastic Gradient Push with Tight Utility Bounds
2405.02638
0
0
Abstract
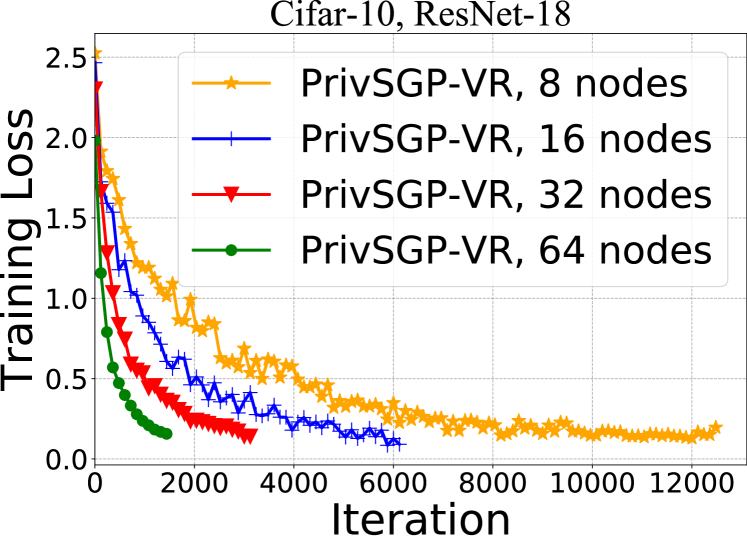
In this paper, we propose a differentially private decentralized learning method (termed PrivSGP-VR) which employs stochastic gradient push with variance reduction and guarantees $(epsilon, delta)$-differential privacy (DP) for each node. Our theoretical analysis shows that, under DP Gaussian noise with constant variance, PrivSGP-VR achieves a sub-linear convergence rate of $mathcal{O}(1/sqrt{nK})$, where $n$ and $K$ are the number of nodes and iterations, respectively, which is independent of stochastic gradient variance, and achieves a linear speedup with respect to $n$. Leveraging the moments accountant method, we further derive an optimal $K$ to maximize the model utility under certain privacy budget in decentralized settings. With this optimized $K$, PrivSGP-VR achieves a tight utility bound of $mathcal{O}left( sqrt{dlog left( frac{1}{delta} right)}/(sqrt{n}Jepsilon) right)$, where $J$ and $d$ are the number of local samples and the dimension of decision variable, respectively, which matches that of the server-client distributed counterparts, and exhibits an extra factor of $1/sqrt{n}$ improvement compared to that of the existing decentralized counterparts, such as A(DP)$^2$SGD. Extensive experiments corroborate our theoretical findings, especially in terms of the maximized utility with optimized $K$, in fully decentralized settings.
Create account to get full access
Overview
- This paper proposes a new algorithm called PrivSGP-VR, which is a differentially private and variance-reduced stochastic gradient push method for decentralized optimization.
- The algorithm aims to improve the performance and privacy guarantees of existing stochastic gradient push methods used in decentralized machine learning.
- The authors provide tight utility bounds for PrivSGP-VR and demonstrate its effectiveness through theoretical analysis and empirical evaluation.
Plain English Explanation
In the world of decentralized machine learning, devices or agents work together to train a shared model without a central coordinator. This is useful for preserving privacy and reducing communication costs. However, existing algorithms for this can be inefficient and leak sensitive information.
The researchers developed a new algorithm called PrivSGP-VR that aims to address these issues. PrivSGP-VR is a differentially private and variance-reduced version of the stochastic gradient push (SGP) method, which is a common approach for decentralized optimization.
Differential privacy means the algorithm adds carefully calibrated noise to the updates sent between devices, making it difficult to infer sensitive information about the individual data points. Variance reduction helps the algorithm converge faster by reducing the noise in the gradient updates.
The key innovation is that PrivSGP-VR provides strong theoretical guarantees on its performance and privacy, as quantified by tight utility bounds. This means the algorithm can achieve good optimization results while preserving privacy to a provable degree.
Technical Explanation
The paper presents the PrivSGP-VR algorithm, which builds on the stochastic gradient push (SGP) method for decentralized optimization. SGP allows devices to collaboratively train a shared model by sending gradient updates to their neighbors in a network.
PrivSGP-VR adds two key components to SGP:
- Differential privacy: The gradient updates are perturbed with carefully calibrated noise to ensure differential privacy, protecting the privacy of individual data points.
- Variance reduction: PrivSGP-VR employs a variance reduction technique to reduce the noise in the gradient updates, improving the algorithm's convergence speed.
The authors provide a detailed theoretical analysis, deriving tight bounds on the utility (optimization performance) and privacy guarantees of PrivSGP-VR. They show that the algorithm achieves a near-optimal trade-off between utility and privacy.
Critical Analysis
The paper provides a solid theoretical foundation for PrivSGP-VR and demonstrates its empirical effectiveness through experiments on several datasets. The authors carefully address potential limitations, such as the assumption of smooth and strongly convex objectives, and discuss future research directions.
One area for further investigation could be the extension of PrivSGP-VR to handle non-convex objectives, which are more common in real-world machine learning applications. The authors mention this as a potential future direction, but more research would be needed to understand the challenges and develop suitable techniques.
Additionally, the paper focuses on the optimization performance and privacy guarantees of PrivSGP-VR, but does not discuss the communication or computational overhead introduced by the differential privacy and variance reduction mechanisms. Evaluating these practical aspects could provide a more holistic understanding of the algorithm's performance in real-world deployments.
Conclusion
The PrivSGP-VR algorithm presented in this paper is a significant advancement in the field of decentralized machine learning. By combining differential privacy and variance reduction techniques, the authors have developed an algorithm that can efficiently solve decentralized optimization problems while providing strong guarantees on privacy preservation.
The tight utility bounds and empirical results demonstrate the effectiveness of PrivSGP-VR, making it a promising approach for real-world applications that require both optimization performance and data privacy. As the field of decentralized machine learning continues to evolve, research like this will be crucial in enabling the widespread adoption of these techniques while addressing the critical challenge of preserving individual privacy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Sign-Based Optimization: Accelerating Convergence via Variance Reduction
Wei Jiang, Sifan Yang, Wenhao Yang, Lijun Zhang
0
0
Sign stochastic gradient descent (signSGD) is a communication-efficient method that transmits only the sign of stochastic gradients for parameter updating. Existing literature has demonstrated that signSGD can achieve a convergence rate of $mathcal{O}(d^{1/2}T^{-1/4})$, where $d$ represents the dimension and $T$ is the iteration number. In this paper, we improve this convergence rate to $mathcal{O}(d^{1/2}T^{-1/3})$ by introducing the Sign-based Stochastic Variance Reduction (SSVR) method, which employs variance reduction estimators to track gradients and leverages their signs to update. For finite-sum problems, our method can be further enhanced to achieve a convergence rate of $mathcal{O}(m^{1/4}d^{1/2}T^{-1/2})$, where $m$ denotes the number of component functions. Furthermore, we investigate the heterogeneous majority vote in distributed settings and introduce two novel algorithms that attain improved convergence rates of $mathcal{O}(d^{1/2}T^{-1/2} + dn^{-1/2})$ and $mathcal{O}(d^{1/4}T^{-1/4})$ respectively, outperforming the previous results of $mathcal{O}(dT^{-1/4} + dn^{-1/2})$ and $mathcal{O}(d^{3/8}T^{-1/8})$, where $n$ represents the number of nodes. Numerical experiments across different tasks validate the effectiveness of our proposed methods.
6/4/2024
👀
Nearly Tight Black-Box Auditing of Differentially Private Machine Learning
Meenatchi Sundaram Muthu Selva Annamalai, Emiliano De Cristofaro
0
0
This paper presents a nearly tight audit of the Differentially Private Stochastic Gradient Descent (DP-SGD) algorithm in the black-box model. Our auditing procedure empirically estimates the privacy leakage from DP-SGD using membership inference attacks; unlike prior work, the estimates are appreciably close to the theoretical DP bounds. The main intuition is to craft worst-case initial model parameters, as DP-SGD's privacy analysis is agnostic to the choice of the initial model parameters. For models trained with theoretical $varepsilon=10.0$ on MNIST and CIFAR-10, our auditing procedure yields empirical estimates of $7.21$ and $6.95$, respectively, on 1,000-record samples and $6.48$ and $4.96$ on the full datasets. By contrast, previous work achieved tight audits only in stronger (i.e., less realistic) white-box models that allow the adversary to access the model's inner parameters and insert arbitrary gradients. Our auditing procedure can be used to detect bugs and DP violations more easily and offers valuable insight into how the privacy analysis of DP-SGD can be further improved.
5/24/2024

Stochastic Constrained Decentralized Optimization for Machine Learning with Fewer Data Oracles: a Gradient Sliding Approach
Hoang Huy Nguyen, Yan Li, Tuo Zhao
0
0
In modern decentralized applications, ensuring communication efficiency and privacy for the users are the key challenges. In order to train machine-learning models, the algorithm has to communicate to the data center and sample data for its gradient computation, thus exposing the data and increasing the communication cost. This gives rise to the need for a decentralized optimization algorithm that is communication-efficient and minimizes the number of gradient computations. To this end, we propose the primal-dual sliding with conditional gradient sliding framework, which is communication-efficient and achieves an $varepsilon$-approximate solution with the optimal gradient complexity of $O(1/sqrt{varepsilon}+sigma^2/{varepsilon^2})$ and $O(log(1/varepsilon)+sigma^2/varepsilon)$ for the convex and strongly convex setting respectively and an LO (Linear Optimization) complexity of $O(1/varepsilon^2)$ for both settings given a stochastic gradient oracle with variance $sigma^2$. Compared with the prior work cite{wai-fw-2017}, our framework relaxes the assumption of the optimal solution being a strict interior point of the feasible set and enjoys wider applicability for large-scale training using a stochastic gradient oracle. We also demonstrate the efficiency of our algorithms with various numerical experiments.
4/4/2024
🔄
Beyond the Mean: Differentially Private Prototypes for Private Transfer Learning
Dariush Wahdany, Matthew Jagielski, Adam Dziedzic, Franziska Boenisch
0
0
Machine learning (ML) models have been shown to leak private information from their training datasets. Differential Privacy (DP), typically implemented through the differential private stochastic gradient descent algorithm (DP-SGD), has become the standard solution to bound leakage from the models. Despite recent improvements, DP-SGD-based approaches for private learning still usually struggle in the high privacy ($varepsilonle1)$ and low data regimes, and when the private training datasets are imbalanced. To overcome these limitations, we propose Differentially Private Prototype Learning (DPPL) as a new paradigm for private transfer learning. DPPL leverages publicly pre-trained encoders to extract features from private data and generates DP prototypes that represent each private class in the embedding space and can be publicly released for inference. Since our DP prototypes can be obtained from only a few private training data points and without iterative noise addition, they offer high-utility predictions and strong privacy guarantees even under the notion of pure DP. We additionally show that privacy-utility trade-offs can be further improved when leveraging the public data beyond pre-training of the encoder: in particular, we can privately sample our DP prototypes from the publicly available data points used to train the encoder. Our experimental evaluation with four state-of-the-art encoders, four vision datasets, and under different data and imbalancedness regimes demonstrate DPPL's high performance under strong privacy guarantees in challenging private learning setups.
6/13/2024