Probabilistic Medical Predictions of Large Language Models

0
💬
Sign in to get full access
Overview
- Large Language Models (LLMs) have shown great potential in clinical applications through prompt engineering.
- However, they face challenges in producing reliable prediction probabilities, which are crucial for transparency and clinician decision-making.
- Explicit probabilities derived from text generation may not be reliable due to LLMs' limitations in numerical reasoning.
- The study compares explicit probabilities from text generation to implicit probabilities calculated based on the likelihood of predicting the correct label.
Plain English Explanation
Large Language Models (LLMs) are powerful AI systems that can generate human-like text. Researchers have found that by carefully crafting the instructions given to LLMs (known as "prompt engineering"), these models can be used for various clinical applications, such as making medical predictions.
One key requirement for clinical applications is the ability to provide reliable probability estimates for the predictions. This allows clinicians to apply flexible probability thresholds in their decision-making, ensuring the appropriate level of confidence. However, LLMs have limitations in their numerical reasoning capabilities, which raises concerns about the reliability of the probability values they generate as text.
To assess this reliability, the researchers in this study compared two approaches for obtaining probability estimates from LLMs:
- Explicit Probabilities: These are the probability values directly generated by the LLM as text output.
- Implicit Probabilities: These are probability values calculated based on the likelihood of the LLM predicting the correct label or outcome.
By testing six different advanced LLMs across five medical datasets, the researchers found that the explicit probabilities consistently underperformed the implicit probabilities in terms of key metrics like discrimination, precision, and recall. This issue was more pronounced when using smaller LLMs or working with imbalanced datasets (where one outcome is much more common than others).
These findings suggest that clinicians should be cautious when relying on the explicit probability values generated by LLMs, as they may not accurately reflect the models' true confidence in their predictions. The researchers recommend further research into more robust probability estimation methods for LLMs in clinical applications, to ensure that clinicians can make informed decisions based on reliable probability information.
Technical Explanation
The researchers set out to assess the reliability of probability estimates generated by Large Language Models (LLMs) in clinical applications. LLMs have shown great promise in this domain through the use of prompt engineering, which allows these models to generate flexible and diverse clinical predictions. However, the ability to produce accurate probability estimates is crucial for transparency and enabling clinicians to apply flexible probability thresholds in their decision-making.
The researchers compared two approaches for obtaining probability estimates from LLMs:
- Explicit Probabilities: These are the probability values directly generated by the LLM as text output, using explicit prompt instructions.
- Implicit Probabilities: These are probability values calculated based on the likelihood of the LLM predicting the correct label or outcome.
The researchers experimented with six advanced open-source LLMs across five medical datasets, evaluating the performance of the explicit and implicit probabilities using metrics like discrimination, precision, and recall.
The results showed that the performance of the explicit probabilities was consistently lower than the implicit probabilities. Moreover, these differences were more pronounced when using smaller LLMs or working with imbalanced datasets, where one outcome is much more common than others.
These findings suggest that the text-generated explicit probabilities from LLMs may not be reliable, likely due to the models' limitations in numerical reasoning. Clinicians should exercise caution when relying on these explicit probability values, as they may not accurately reflect the models' true confidence in their predictions.
The researchers emphasize the need for further research into more robust probability estimation methods for LLMs in clinical contexts, to ensure that clinicians can make informed decisions based on reliable probability information.
Critical Analysis
The researchers have raised an important concern about the reliability of probability estimates generated by Large Language Models (LLMs) in clinical applications. Their findings suggest that the explicit probabilities directly output by LLMs may not accurately reflect the models' true confidence in their predictions, which could lead to suboptimal decision-making by clinicians.
One key limitation of the study is that it focused on advanced open-source LLMs, and the researchers acknowledge that the performance of explicit probabilities may vary for different LLM architectures or training approaches. It would be valuable to expand the study to include a wider range of LLM models, including those used in commercial clinical applications.
Additionally, the researchers note that the differences between explicit and implicit probabilities were more pronounced on smaller LLMs and imbalanced datasets. This suggests that the reliability of probability estimates may be particularly problematic in resource-constrained settings or when dealing with rare medical conditions. Further investigation into strategies to improve probability estimation in these challenging scenarios would be beneficial.
Finally, while the researchers recommend the development of more robust probability estimation methods for LLMs in clinical contexts, they do not provide specific details on what these methods might entail. Exploring and evaluating different approaches, such as incorporating Bayesian techniques or using ensemble methods, could be a fruitful area for future research.
Overall, this study highlights an important consideration for the deployment of LLMs in high-stakes clinical applications, where reliable probability estimates are critical for informed decision-making. The findings call for a cautious approach and further research to ensure the responsible use of these powerful AI models in healthcare settings.
Conclusion
This study has uncovered a significant challenge in the use of Large Language Models (LLMs) for clinical applications: the reliability of the probability estimates they generate. The researchers found that the explicit probabilities directly output by LLMs consistently underperformed compared to implicit probabilities calculated based on the models' likelihood of predicting the correct label.
These findings raise concerns about the ability of LLMs to provide transparent and trustworthy probability information, which is essential for clinicians to make informed decisions. The study emphasizes the need for caution when relying on the explicit probability values generated by LLMs, particularly in resource-constrained settings or when dealing with imbalanced datasets.
Further research is required to develop more robust probability estimation methods for LLMs in clinical contexts. Exploring techniques that can improve the reliability and accuracy of these probability estimates will be crucial for the responsible deployment of these powerful AI models in high-stakes healthcare applications.
As the use of LLMs continues to expand in clinical settings, addressing this challenge will be paramount to ensuring that these technologies can truly benefit patients and support clinicians in making well-informed, evidence-based decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Probabilistic Medical Predictions of Large Language Models
Bowen Gu, Rishi J. Desai, Kueiyu Joshua Lin, Jie Yang
Large Language Models (LLMs) have demonstrated significant potential in clinical applications through prompt engineering, which enables the generation of flexible and diverse clinical predictions. However, they pose challenges in producing prediction probabilities, which are essential for transparency and allowing clinicians to apply flexible probability thresholds in decision-making. While explicit prompt instructions can lead LLMs to provide prediction probability numbers through text generation, LLMs' limitations in numerical reasoning raise concerns about the reliability of these text-generated probabilities. To assess this reliability, we compared explicit probabilities derived from text generation to implicit probabilities calculated based on the likelihood of predicting the correct label token. Experimenting with six advanced open-source LLMs across five medical datasets, we found that the performance of explicit probabilities was consistently lower than implicit probabilities with respect to discrimination, precision, and recall. Moreover, these differences were enlarged on small LLMs and imbalanced datasets, emphasizing the need for cautious interpretation and applications, as well as further research into robust probability estimation methods for LLMs in clinical contexts.
Read more8/22/2024

0
Beyond Probabilities: Unveiling the Misalignment in Evaluating Large Language Models
Chenyang Lyu, Minghao Wu, Alham Fikri Aji
Large Language Models (LLMs) have demonstrated remarkable capabilities across various applications, fundamentally reshaping the landscape of natural language processing (NLP) research. However, recent evaluation frameworks often rely on the output probabilities of LLMs for predictions, primarily due to computational constraints, diverging from real-world LLM usage scenarios. While widely employed, the efficacy of these probability-based evaluation strategies remains an open research question. This study aims to scrutinize the validity of such probability-based evaluation methods within the context of using LLMs for Multiple Choice Questions (MCQs), highlighting their inherent limitations. Our empirical investigation reveals that the prevalent probability-based evaluation method inadequately aligns with generation-based prediction. Furthermore, current evaluation frameworks typically assess LLMs through predictive tasks based on output probabilities rather than directly generating responses, owing to computational limitations. We illustrate that these probability-based approaches do not effectively correspond with generative predictions. The outcomes of our study can enhance the understanding of LLM evaluation methodologies and provide insights for future research in this domain.
Read more7/10/2024
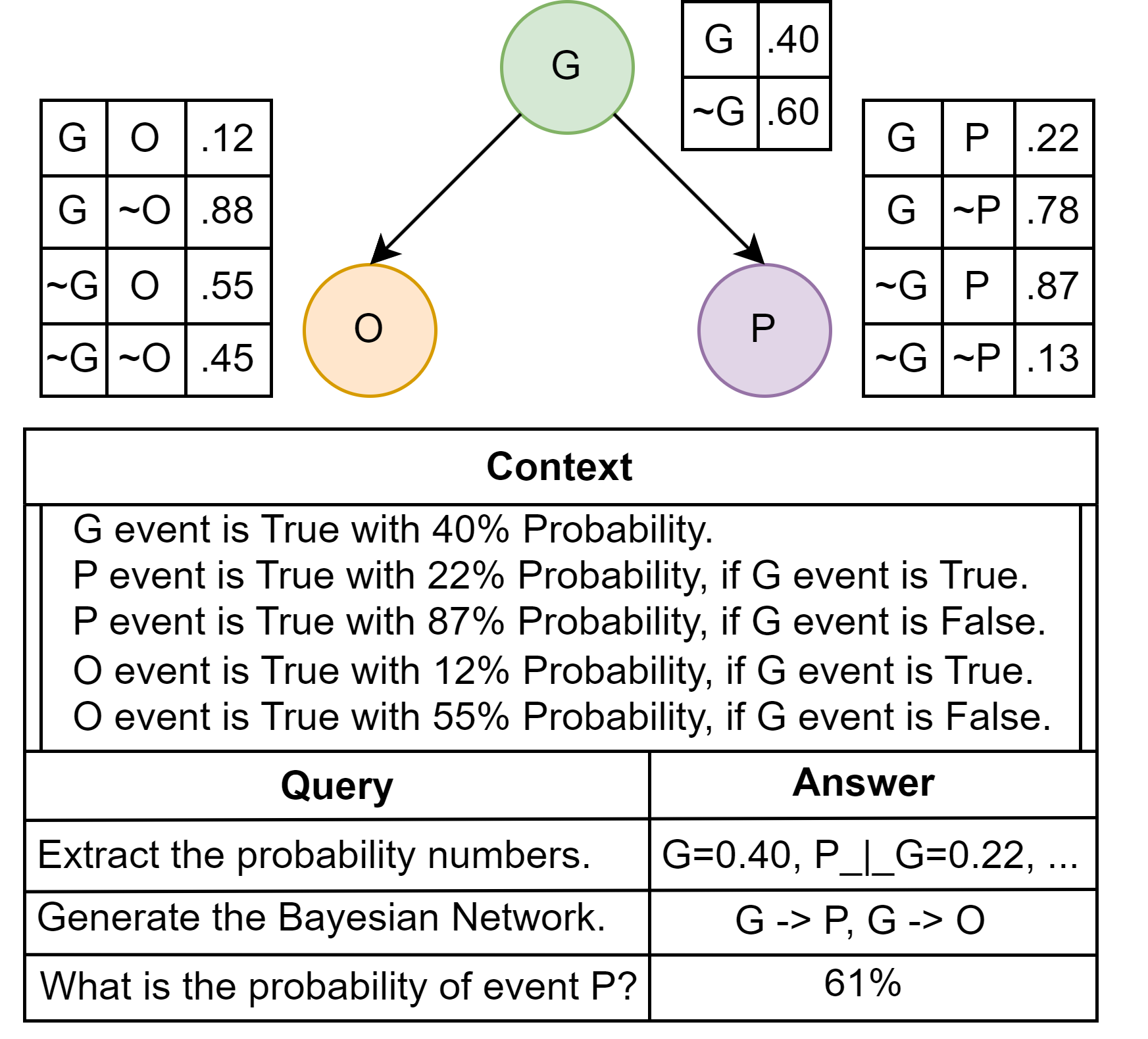
0
Probabilistic Reasoning in Generative Large Language Models
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
This paper considers the challenges Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We use BLInD to find out the limitations of LLMs for tasks involving probabilistic reasoning. In addition, we present several prompting strategies that map the problem to different formal representations, including Python code, probabilistic algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and an adaptation of a causal reasoning question-answering dataset. Our empirical results highlight the effectiveness of our proposed strategies for multiple LLMs.
Read more6/18/2024
🤿
0
Bayesian Statistical Modeling with Predictors from LLMs
Michael Franke, Polina Tsvilodub, Fausto Carcassi
State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.
Read more6/14/2024