Unifying Foundation Models with Quadrotor Control for Visual Tracking Beyond Object Categories
2310.04781
0
0

Abstract
Visual control enables quadrotors to adaptively navigate using real-time sensory data, bridging perception with action. Yet, challenges persist, including generalization across scenarios, maintaining reliability, and ensuring real-time responsiveness. This paper introduces a perception framework grounded in foundation models for universal object detection and tracking, moving beyond specific training categories. Integral to our approach is a multi-layered tracker integrated with the foundation detector, ensuring continuous target visibility, even when faced with motion blur, abrupt light shifts, and occlusions. Complementing this, we introduce a model-free controller tailored for resilient quadrotor visual tracking. Our system operates efficiently on limited hardware, relying solely on an onboard camera and an inertial measurement unit. Through extensive validation in diverse challenging indoor and outdoor environments, we demonstrate our system's effectiveness and adaptability. In conclusion, our research represents a step forward in quadrotor visual tracking, moving from task-specific methods to more versatile and adaptable operations.
Create account to get full access
Overview
- This paper proposes a unified approach for visual tracking that goes beyond traditional object categories.
- It combines foundation models, which are large pre-trained neural networks, with quadrotor control to enable continuous visual tracking of dynamic objects.
- The method aims to achieve robust and adaptive tracking performance that can handle a wide range of visual targets, including both rigid and deformable objects.
Plain English Explanation
The researchers have developed a new system for visually tracking objects as they move around. Traditional object tracking systems are usually limited to a specific set of object categories, like cars or people. In contrast, this new approach uses a powerful "foundation model" - a large neural network that has been pre-trained on a huge amount of data - to enable tracking of a much wider range of objects, including things that can change shape or move in complex ways.
The key innovation is combining this flexible foundation model with a specialized control system for a quadrotor drone. The drone uses the foundation model to continuously identify and track the target object, even as it moves and changes. This allows the drone to keep the object centered in its view and follow it closely, something that would be very difficult to do with a traditional object tracker.
By unifying these two technologies - powerful vision models and agile drone control - the researchers have created a system that can visually track objects in a robust and adaptable way, going far beyond the limitations of previous approaches. This could have important applications in areas like surveillance, search and rescue, and interactive robotics.
Technical Explanation
The paper presents a novel framework called "Unifying Foundation Models with Quadrotor Control for Visual Tracking Beyond Object Categories" (UFQC). At the core of this approach is the use of a foundation model - a large, pre-trained neural network capable of adaptively representing a wide variety of visual concepts.
This foundation model is integrated with a quadrotor control system to enable continuous, real-time tracking of dynamic visual targets. The quadrotor is equipped with a camera and uses the foundation model to continuously perceive and localize the target, even as it moves and changes shape. The control system then generates appropriate navigation commands to keep the target centered in the camera's view.
Key aspects of the UFQC framework include:
- Foundation Model Integration: The paper explores different ways of incorporating the foundation model into the tracking pipeline, including feature extraction, query-based localization, and end-to-end training.
- Quadrotor Control Formulation: The researchers develop a unified control framework that allows the quadrotor to smoothly track the target while avoiding obstacles and maintaining stability.
- Experimental Evaluation: The authors conduct extensive experiments to assess the tracking performance of UFQC across a diverse set of visual targets, including rigid and deformable objects, as well as comparing it to state-of-the-art tracking methods.
The key insights from this work are that the combination of a powerful foundation model and an agile quadrotor control system can enable robust and adaptive visual tracking that goes beyond traditional object categories. This lays the groundwork for more flexible and interpretable motion planning in complex, dynamic environments.
Critical Analysis
The UFQC framework represents an interesting and promising approach to visual tracking, but there are a few important considerations to keep in mind:
- Computational Complexity: Integrating a large foundation model with real-time quadrotor control is computationally demanding, which may limit the practicality of this approach, especially for resource-constrained platforms.
- Robustness to Occlusion: While the paper demonstrates strong tracking performance in various scenarios, the resilience of the system to prolonged occlusions or challenging environmental conditions is not thoroughly explored.
- Ethical Considerations: The capabilities demonstrated in this work could raise concerns about surveillance and privacy, underscoring the need for responsible development and deployment of such technologies.
Overall, the UFQC framework is an important step towards more flexible and adaptive visual tracking systems. However, further research is needed to address the computational and robustness challenges, as well as to carefully consider the ethical implications of this technology.
Conclusion
This paper presents a novel approach called "Unifying Foundation Models with Quadrotor Control for Visual Tracking Beyond Object Categories" (UFQC) that combines powerful foundation models with agile quadrotor control to enable robust and adaptable visual tracking. By integrating these two key technologies, the researchers have developed a system that can continuously track a wide range of visual targets, including both rigid and deformable objects.
The UFQC framework represents an important advancement in the field of visual tracking, paving the way for more flexible and interpretable motion planning in complex, dynamic environments. While there are some technical and ethical considerations to address, this work demonstrates the potential of unifying foundation models and robotic control systems to push the boundaries of what is possible in visual perception and autonomous navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Empowering Embodied Visual Tracking with Visual Foundation Models and Offline RL
Fangwei Zhong, Kui Wu, Hai Ci, Churan Wang, Hao Chen
0
0
Embodied visual tracking is to follow a target object in dynamic 3D environments using an agent's egocentric vision. This is a vital and challenging skill for embodied agents. However, existing methods suffer from inefficient training and poor generalization. In this paper, we propose a novel framework that combines visual foundation models (VFM) and offline reinforcement learning (offline RL) to empower embodied visual tracking. We use a pre-trained VFM, such as ``Tracking Anything, to extract semantic segmentation masks with text prompts. We then train a recurrent policy network with offline RL, e.g., Conservative Q-Learning, to learn from the collected demonstrations without online agent-environment interactions. To further improve the robustness and generalization of the policy network, we also introduce a mask re-targeting mechanism and a multi-level data collection strategy. In this way, we can train a robust tracker within an hour on a consumer-level GPU, e.g., Nvidia RTX 3090. Such efficiency is unprecedented for RL-based visual tracking methods. We evaluate our tracker on several high-fidelity environments with challenging situations, such as distraction and occlusion. The results show that our agent outperforms state-of-the-art methods in terms of sample efficiency, robustness to distractors, and generalization to unseen scenarios and targets. We also demonstrate the transferability of the learned tracker from the virtual world to real-world scenarios.
4/16/2024
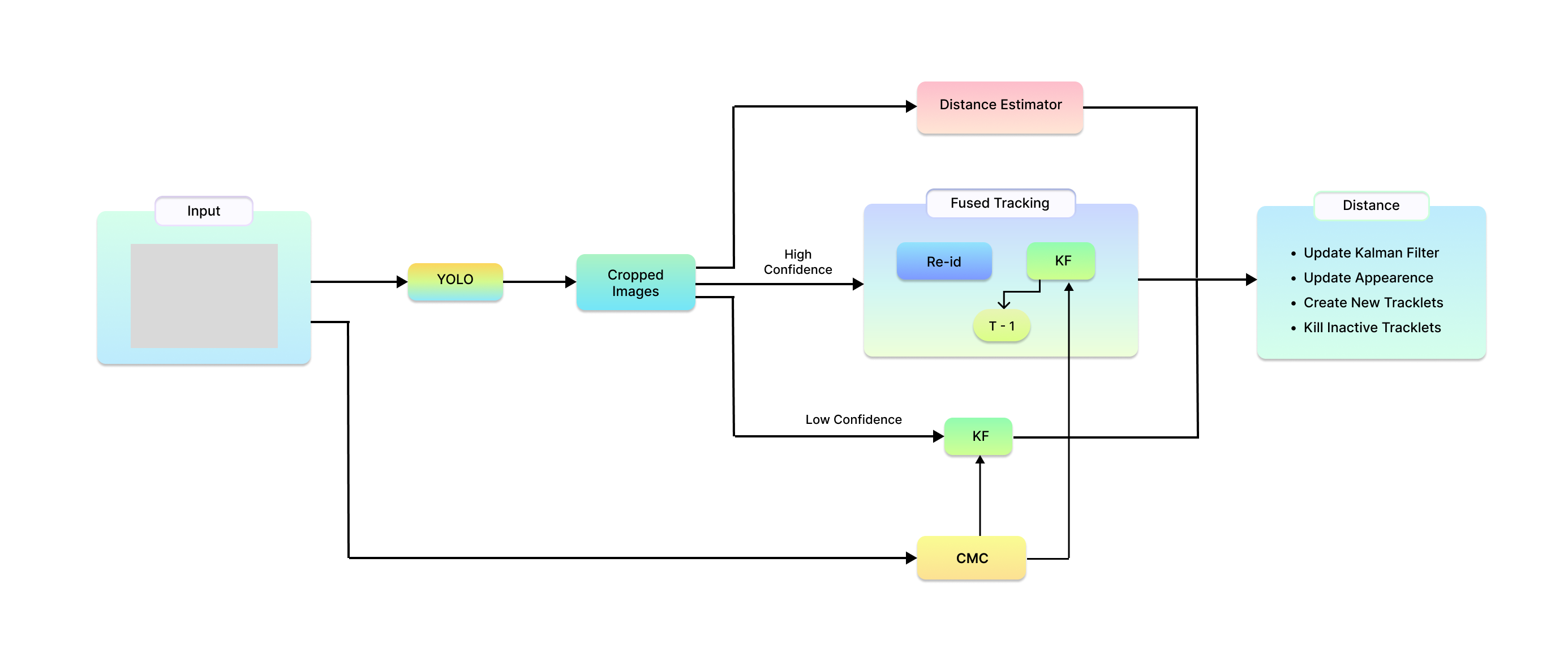
Ensuring UAV Safety: A Vision-only and Real-time Framework for Collision Avoidance Through Object Detection, Tracking, and Distance Estimation
Vasileios Karampinis, Anastasios Arsenos, Orfeas Filippopoulos, Evangelos Petrongonas, Christos Skliros, Dimitrios Kollias, Stefanos Kollias, Athanasios Voulodimos
0
0
In the last twenty years, unmanned aerial vehicles (UAVs) have garnered growing interest due to their expanding applications in both military and civilian domains. Detecting non-cooperative aerial vehicles with efficiency and estimating collisions accurately are pivotal for achieving fully autonomous aircraft and facilitating Advanced Air Mobility (AAM). This paper presents a deep-learning framework that utilizes optical sensors for the detection, tracking, and distance estimation of non-cooperative aerial vehicles. In implementing this comprehensive sensing framework, the availability of depth information is essential for enabling autonomous aerial vehicles to perceive and navigate around obstacles. In this work, we propose a method for estimating the distance information of a detected aerial object in real time using only the input of a monocular camera. In order to train our deep learning components for the object detection, tracking and depth estimation tasks we utilize the Amazon Airborne Object Tracking (AOT) Dataset. In contrast to previous approaches that integrate the depth estimation module into the object detector, our method formulates the problem as image-to-image translation. We employ a separate lightweight encoder-decoder network for efficient and robust depth estimation. In a nutshell, the object detection module identifies and localizes obstacles, conveying this information to both the tracking module for monitoring obstacle movement and the depth estimation module for calculating distances. Our approach is evaluated on the Airborne Object Tracking (AOT) dataset which is the largest (to the best of our knowledge) air-to-air airborne object dataset.
5/17/2024

Vision Transformers for End-to-End Vision-Based Quadrotor Obstacle Avoidance
Anish Bhattacharya, Nishanth Rao, Dhruv Parikh, Pratik Kunapuli, Nikolai Matni, Vijay Kumar
0
0
We demonstrate the capabilities of an attention-based end-to-end approach for high-speed quadrotor obstacle avoidance in dense, cluttered environments, with comparison to various state-of-the-art architectures. Quadrotor unmanned aerial vehicles (UAVs) have tremendous maneuverability when flown fast; however, as flight speed increases, traditional vision-based navigation via independent mapping, planning, and control modules breaks down due to increased sensor noise, compounding errors, and increased processing latency. Thus, learning-based, end-to-end planning and control networks have shown to be effective for online control of these fast robots through cluttered environments. We train and compare convolutional, U-Net, and recurrent architectures against vision transformer models for depth-based end-to-end control, in a photorealistic, high-physics-fidelity simulator as well as in hardware, and observe that the attention-based models are more effective as quadrotor speeds increase, while recurrent models with many layers provide smoother commands at lower speeds. To the best of our knowledge, this is the first work to utilize vision transformers for end-to-end vision-based quadrotor control.
5/20/2024

Innovative Integration of Visual Foundation Model with a Robotic Arm on a Mobile Platform
Shimian Zhang, Qiuhong Lu
0
0
In the rapidly advancing field of robotics, the fusion of state-of-the-art visual technologies with mobile robotic arms has emerged as a critical integration. This paper introduces a novel system that combines the Segment Anything model (SAM) -- a transformer-based visual foundation model -- with a robotic arm on a mobile platform. The design of integrating a depth camera on the robotic arm's end-effector ensures continuous object tracking, significantly mitigating environmental uncertainties. By deploying on a mobile platform, our grasping system has an enhanced mobility, playing a key role in dynamic environments where adaptability are critical. This synthesis enables dynamic object segmentation, tracking, and grasping. It also elevates user interaction, allowing the robot to intuitively respond to various modalities such as clicks, drawings, or voice commands, beyond traditional robotic systems. Empirical assessments in both simulated and real-world demonstrate the system's capabilities. This configuration opens avenues for wide-ranging applications, from industrial settings, agriculture, and household tasks, to specialized assignments and beyond.
4/30/2024