Probing Causality Manipulation of Large Language Models

0

Sign in to get full access
Overview
- The paper explores how large language models (LLMs) can be probed to understand their causal reasoning capabilities.
- Researchers investigate whether LLMs can manipulate causal relationships and make counterfactual predictions.
- The findings have implications for developing more transparent and controllable AI systems with improved causal reasoning.
Plain English Explanation
The paper looks at how powerful language models can be used to understand their ability to reason about causes and effects. The researchers wanted to see if these large AI models could manipulate causal relationships and make predictions about what would happen in hypothetical, counterfactual scenarios.
By probing the language models in this way, the researchers hope to gain insights that could help create more transparent and controllable AI systems with better causal reasoning capabilities. This is an important area of research, as large language models are becoming increasingly powerful and influential, and we need to understand how they make decisions and draw conclusions.
Technical Explanation
The researchers used a combination of techniques to investigate the causal reasoning capabilities of large language models. This included:
- Prompting the models to make counterfactual predictions by altering causal statements in the input text.
- Analyzing the models' responses to see if they could recognize and manipulate causal relationships.
- Evaluating the models' ability to generate coherent and relevant counterfactual scenarios.
The findings suggest that while LLMs display some understanding of causal structures, their ability to reason about counterfactuals is limited. The models struggled to consistently recognize and modify causal relationships, and their counterfactual predictions often lacked coherence or relevance.
Critical Analysis
The paper acknowledges several limitations in the current state of causal reasoning in large language models. The experiments are constrained, and the models may perform better on more natural, open-ended tasks.
Additionally, the research does not address issues of causal graph discovery or retrieval-augmented generation, which could be important for developing more sophisticated causal reasoning capabilities.
Further research is needed to fully understand the causal reasoning abilities of large language models and how to improve them. This is a complex challenge, but one that is crucial for creating more reliable and trustworthy AI systems.
Conclusion
This paper takes an important step in probing the causal reasoning capabilities of large language models. While the findings suggest limitations in the models' ability to manipulate causal relationships and make counterfactual predictions, the research highlights the need for continued exploration in this area.
Developing AI systems with robust causal reasoning skills could have significant implications for a wide range of applications, from decision-making to scientific discovery. The insights from this paper contribute to the ongoing effort to create more transparent, controllable, and beneficial artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Probing Causality Manipulation of Large Language Models
Chenyang Zhang, Haibo Tong, Bin Zhang, Dongyu Zhang
Large language models (LLMs) have shown various ability on natural language processing, including problems about causality. It is not intuitive for LLMs to command causality, since pretrained models usually work on statistical associations, and do not focus on causes and effects in sentences. So that probing internal manipulation of causality is necessary for LLMs. This paper proposes a novel approach to probe causality manipulation hierarchically, by providing different shortcuts to models and observe behaviors. We exploit retrieval augmented generation (RAG) and in-context learning (ICL) for models on a designed causality classification task. We conduct experiments on mainstream LLMs, including GPT-4 and some smaller and domain-specific models. Our results suggest that LLMs can detect entities related to causality and recognize direct causal relationships. However, LLMs lack specialized cognition for causality, merely treating them as part of the global semantic of the sentence.
Read more8/27/2024
💬
4
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Emre K{i}c{i}man, Robert Ness, Amit Sharma, Chenhao Tan
The causal capabilities of large language models (LLMs) are a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We conduct a behavorial study of LLMs to benchmark their capability in generating causal arguments. Across a wide range of tasks, we find that LLMs can generate text corresponding to correct causal arguments with high probability, surpassing the best-performing existing methods. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain) and event causality (86% accuracy in determining necessary and sufficient causes in vignettes). We perform robustness checks across tasks and show that the capabilities cannot be explained by dataset memorization alone, especially since LLMs generalize to novel datasets that were created after the training cutoff date. That said, LLMs exhibit unpredictable failure modes, and we discuss the kinds of errors that may be improved and what are the fundamental limits of LLM-based answers. Overall, by operating on the text metadata, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. As a result, LLMs may be used by human domain experts to save effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. Given that LLMs ignore the actual data, our results also point to a fruitful research direction of developing algorithms that combine LLMs with existing causal techniques. Code and datasets are available at https://github.com/py-why/pywhy-llm.
Read more8/21/2024
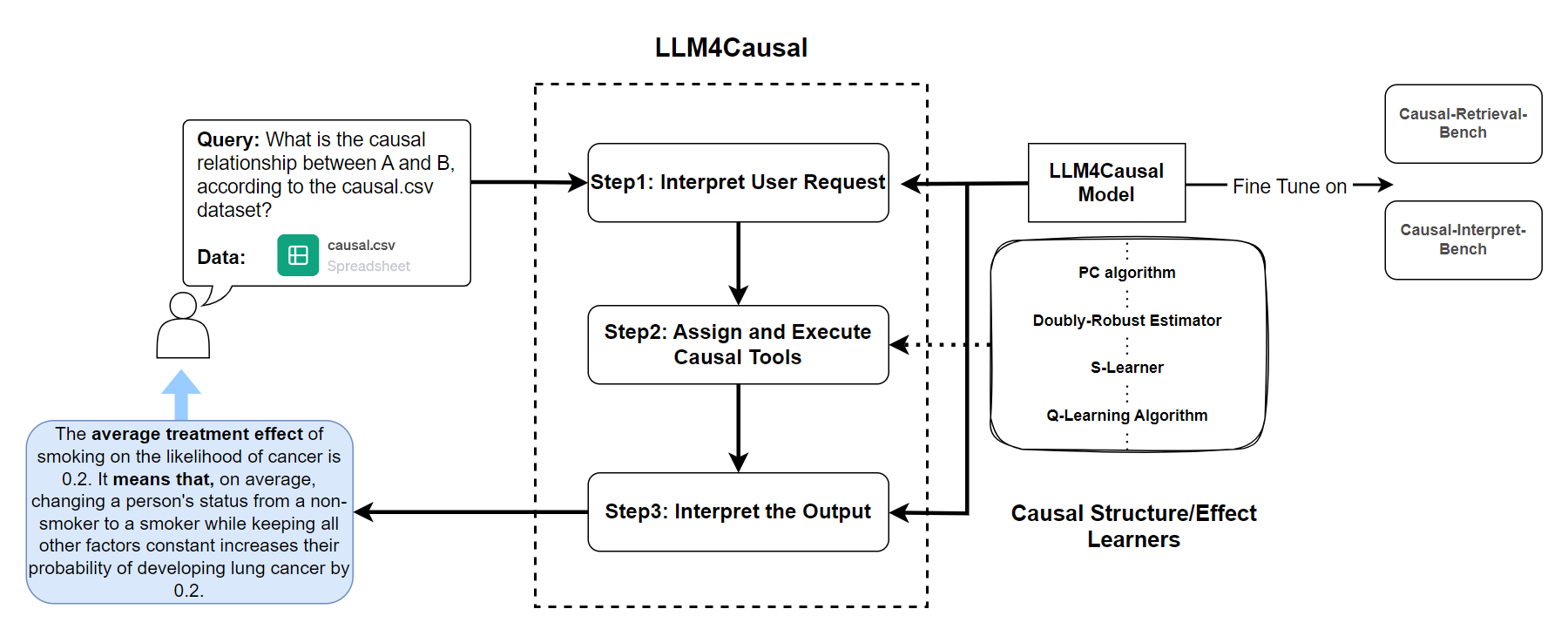
0
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
Read more4/15/2024
💬
0
Can Large Language Models Learn Independent Causal Mechanisms?
Gael Gendron, Bao Trung Nguyen, Alex Yuxuan Peng, Michael Witbrock, Gillian Dobbie
Despite impressive performance on language modelling and complex reasoning tasks, Large Language Models (LLMs) fall short on the same tasks in uncommon settings or with distribution shifts, exhibiting a lack of generalisation ability. By contrast, systems such as causal models, that learn abstract variables and causal relationships, can demonstrate increased robustness against changes in the distribution. One reason for this success is the existence and use of Independent Causal Mechanisms (ICMs) representing high-level concepts that only sparsely interact. In this work, we apply two concepts from causality to learn ICMs within LLMs. We develop a new LLM architecture composed of multiple sparsely interacting language modelling modules. We show that such causal constraints can improve out-of-distribution performance on abstract and causal reasoning tasks. We also investigate the level of independence and domain specialisation and show that LLMs rely on pre-trained partially domain-invariant mechanisms resilient to fine-tuning.
Read more9/11/2024