Probing Language Models for Pre-training Data Detection
2406.01333
0
0

Abstract
Large Language Models (LLMs) have shown their impressive capabilities, while also raising concerns about the data contamination problems due to privacy issues and leakage of benchmark datasets in the pre-training phase. Therefore, it is vital to detect the contamination by checking whether an LLM has been pre-trained on the target texts. Recent studies focus on the generated texts and compute perplexities, which are superficial features and not reliable. In this study, we propose to utilize the probing technique for pre-training data detection by examining the model's internal activations. Our method is simple and effective and leads to more trustworthy pre-training data detection. Additionally, we propose ArxivMIA, a new challenging benchmark comprising arxiv abstracts from Computer Science and Mathematics categories. Our experiments demonstrate that our method outperforms all baselines, and achieves state-of-the-art performance on both WikiMIA and ArxivMIA, with additional experiments confirming its efficacy (Our code and dataset are available at https://github.com/zhliu0106/probing-lm-data).
Create account to get full access
Overview
- This paper explores techniques for detecting whether the training data used to fine-tune a language model contains information from the model's original pre-training dataset.
- The authors develop a method called PROBE that can identify specific passages in the fine-tuning data that are derived from the pre-training corpus.
- They demonstrate PROBE's effectiveness on several language models and datasets, showing it can reliably detect data contamination.
- This work has implications for ensuring the integrity of machine learning benchmarks and preventing unintended knowledge leaks in deployed language models.
Plain English Explanation
The paper looks at a problem called "data contamination" in language models. When you train a language model on a large amount of text data, it can pick up patterns and information from that data. Later, if you fine-tune the model on a new dataset for a specific task, that original training data can sometimes "leak" into the fine-tuned model.
This is a problem because it can skew the results of benchmarks and tests used to evaluate the model. The model might perform better on the benchmark not because it genuinely learned the task, but because it's drawing on information it already had from the original training data.
The authors developed a technique called PROBE that can detect when this data contamination is happening. PROBE analyzes the fine-tuned model and identifies specific passages or sections of text that seem to have come from the original pre-training dataset, rather than the intended fine-tuning data.
By using PROBE, researchers and companies can check their language models for data leaks and ensure the integrity of their benchmark evaluations. This helps make the development of these powerful AI systems more transparent and reliable.
Technical Explanation
The key technical contribution of this paper is the PROBE methodology for detecting pre-training data contamination in fine-tuned language models. PROBE works by probing the fine-tuned model's internal representations to identify passages from the original pre-training corpus that have been retained.
Specifically, the PROBE approach involves:
- Collecting a set of candidate passages from the pre-training corpus.
- Encoding these passages using the fine-tuned model and measuring their similarity to the model's internal representations.
- Applying a statistical test to determine which candidate passages are significantly more similar to the model than expected by chance, indicating potential data contamination.
The authors evaluate PROBE on several popular language models, including GPT-2, BERT, and GPT-3, and across different fine-tuning tasks and datasets. They show that PROBE can reliably detect data contamination, even when the fine-tuning task and dataset are quite different from the original pre-training distribution.
Additionally, the paper explores the connections between data contamination and model performance on benchmarks. The authors find evidence that models exhibiting data contamination can achieve inflated performance on certain tasks, highlighting the need for careful evaluation and monitoring of language models.
Critical Analysis
The PROBE methodology presented in this paper is a valuable contribution to the field of language model evaluation and transparency. By providing a principled way to detect data contamination, it helps address an important challenge in the development and deployment of large language models.
That said, the paper does note some limitations of PROBE. For example, the technique may struggle to identify contamination from very large or broad pre-training corpora, where the signal is more diffuse. Additionally, PROBE relies on having access to the pre-training corpus, which may not always be feasible in practice.
Another potential issue is the scope of the analysis. While the paper demonstrates PROBE's effectiveness on several popular language models, there may be other types of data contamination or model biases that the technique does not capture. Further research is needed to fully understand the various ways in which pre-training data can influence fine-tuned models.
Overall, this paper represents an important step forward in understanding and mitigating the risks of data contamination in language models. By shedding light on this issue and providing a practical tool for detecting it, the authors have made a valuable contribution to the ongoing efforts to develop more transparent and trustworthy AI systems.
Conclusion
This paper introduces a novel technique called PROBE that can detect when the training data used to fine-tune a language model contains information from the model's original pre-training dataset. By identifying specific passages of contaminated data, PROBE helps ensure the integrity of machine learning benchmarks and prevents unintended knowledge leaks in deployed language models.
The authors demonstrate PROBE's effectiveness across multiple language models and fine-tuning tasks, highlighting the widespread nature of data contamination and its potential impact on model performance. This work has important implications for the responsible development and deployment of large language models, which are becoming increasingly prevalent in a wide range of applications.
Overall, this paper represents a significant step forward in understanding and addressing the challenges of data contamination in modern AI systems. By shedding light on this issue and providing a practical tool for detection, the authors have made a valuable contribution to the ongoing efforts to build more transparent, reliable, and trustworthy language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Pandora's White-Box: Precise Training Data Detection and Extraction in Large Language Models
Jeffrey G. Wang, Jason Wang, Marvin Li, Seth Neel
0
0
In this paper we develop state-of-the-art privacy attacks against Large Language Models (LLMs), where an adversary with some access to the model tries to learn something about the underlying training data. Our headline results are new membership inference attacks (MIAs) against pretrained LLMs that perform hundreds of times better than baseline attacks, and a pipeline showing that over 50% (!) of the fine-tuning dataset can be extracted from a fine-tuned LLM in natural settings. We consider varying degrees of access to the underlying model, pretraining and fine-tuning data, and both MIAs and training data extraction. For pretraining data, we propose two new MIAs: a supervised neural network classifier that predicts training data membership on the basis of (dimensionality-reduced) model gradients, as well as a variant of this attack that only requires logit access to the model by leveraging recent model-stealing work on LLMs. To our knowledge this is the first MIA that explicitly incorporates model-stealing information. Both attacks outperform existing black-box baselines, and our supervised attack closes the gap between MIA attack success against LLMs and the strongest known attacks for other machine learning models. In fine-tuning, we find that a simple attack based on the ratio of the loss between the base and fine-tuned models is able to achieve near-perfect MIA performance; we then leverage our MIA to extract a large fraction of the fine-tuning dataset from fine-tuned Pythia and Llama models. Our code is available at github.com/safr-ai-lab/pandora-llm.
6/26/2024
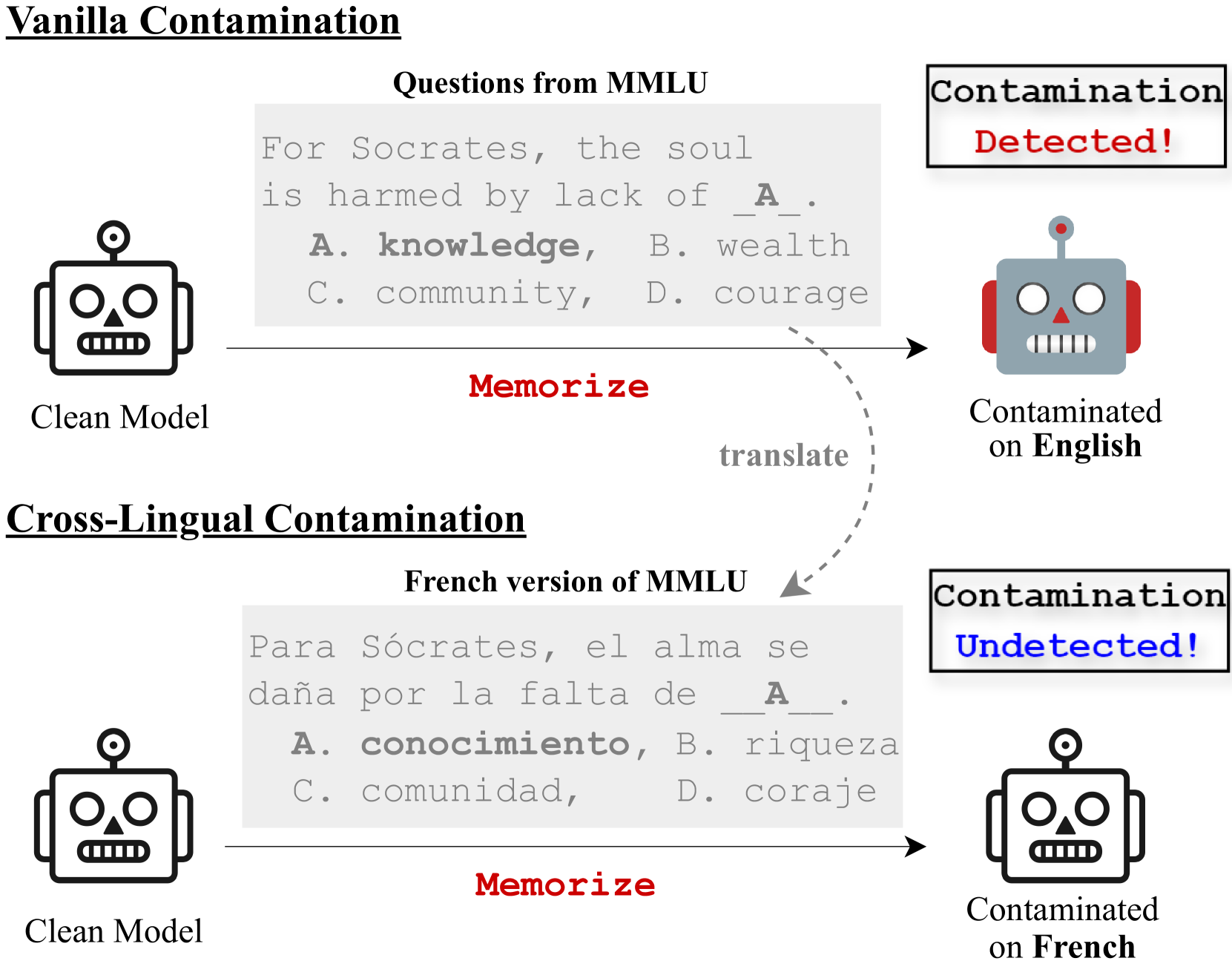
Data Contamination Can Cross Language Barriers
Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, Jingbo Shang
0
0
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from url{https://github.com/ShangDataLab/Deep-Contam}.
6/21/2024
💬
Benchmarking Benchmark Leakage in Large Language Models
Ruijie Xu, Zengzhi Wang, Run-Ze Fan, Pengfei Liu
0
0
Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion of supervised data in contemporary Large Language Models (LLMs). This issue skews benchmark effectiveness and fosters potentially unfair comparisons, impeding the field's healthy development. To address this, we introduce a detection pipeline utilizing Perplexity and N-gram accuracy, two simple and scalable metrics that gauge a model's prediction precision on benchmark, to identify potential data leakages. By analyzing 31 LLMs under the context of mathematical reasoning, we reveal substantial instances of training even test set misuse, resulting in potentially unfair comparisons. These findings prompt us to offer several recommendations regarding model documentation, benchmark setup, and future evaluations. Notably, we propose the Benchmark Transparency Card to encourage clear documentation of benchmark utilization, promoting transparency and healthy developments of LLMs. we have made our leaderboard, pipeline implementation, and model predictions publicly available, fostering future research.
4/30/2024
📊
Investigating Data Contamination in Modern Benchmarks for Large Language Models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, Arman Cohan
0
0
Recent observations have underscored a disparity between the inflated benchmark scores and the actual performance of LLMs, raising concerns about potential contamination of evaluation benchmarks. This issue is especially critical for closed-source models and certain open-source models where training data transparency is lacking. In this paper we study data contamination by proposing two methods tailored for both open-source and proprietary LLMs. We first introduce a retrieval-based system to explore potential overlaps between evaluation benchmarks and pretraining corpora. We further present a novel investigation protocol named textbf{T}estset textbf{S}lot Guessing (textit{TS-Guessing}), applicable to both open and proprietary models. This approach entails masking a wrong answer in a multiple-choice question and prompting the model to fill in the gap. Additionally, it involves obscuring an unlikely word in an evaluation example and asking the model to produce it. We find that certain commercial LLMs could surprisingly guess the missing option in various test sets. Specifically, in the TruthfulQA benchmark, we find that LLMs exhibit notable performance improvement when provided with additional metadata in the benchmark. Further, in the MMLU benchmark, ChatGPT and GPT-4 demonstrated an exact match rate of 52% and 57%, respectively, in guessing the missing options in benchmark test data. We hope these results underscore the need for more robust evaluation methodologies and benchmarks in the field.
4/5/2024