Probing the Safety Response Boundary of Large Language Models via Unsafe Decoding Path Generation

0

Sign in to get full access
Overview
- This paper explores the safety response boundaries of large language models (LLMs) by probing them with potentially unsafe decoding paths.
- The researchers generated unsafe text outputs to test the models' ability to detect and avoid generating harmful content.
- The findings have implications for improving the safety and robustness of LLMs, which are increasingly being used in high-stakes applications.
Plain English Explanation
The paper investigates the limits of safety features in large language models (LLMs) - powerful AI systems that can generate human-like text. The researchers wanted to see how far they could push these models before the safety systems kicked in and stopped them from producing harmful or offensive content.
To do this, they deliberately tried to get the models to generate unsafe text by feeding them certain prompts and decoding strategies. This allowed them to map out the "safety response boundary" - the point at which the models would recognize the text as unsafe and refuse to output it.
Understanding these boundaries is important because LLMs are being used in more and more critical applications, like generating product descriptions or answering sensitive questions. If the safety features aren't robust enough, the models could inadvertently produce harmful content. This research helps identify areas that need improvement to make these systems more reliable and trustworthy.
Technical Explanation
The paper presents a method for probing the safety response boundaries of large language models (LLMs). The researchers designed a suite of "unsafe decoding paths" - prompts and decoding strategies intended to push the models towards generating harmful or offensive text.
By systematically applying these unsafe decoding paths, the team was able to map out the limits of the models' safety response mechanisms. They identified the specific points at which the models would detect the potentially unsafe content and refuse to output it.
The experiments were conducted across multiple popular LLM architectures, including GPT-3, InstructGPT, and PaLM. The researchers found that the models exhibited a range of safety response behaviors, with some being more robust to the unsafe prompts than others.
The insights from this work can inform the development of more effective safety systems for LLMs. By understanding the vulnerabilities and boundaries of current approaches, researchers and practitioners can work to improve the safeguards and make these powerful language models more reliable and trustworthy for real-world applications.
Critical Analysis
The paper provides a valuable contribution to the field of AI safety by probing the limits of current safety mechanisms in large language models. By deliberately testing the models with potentially unsafe prompts, the researchers were able to uncover important insights about the robustness and limitations of these safety systems.
However, it's important to note that the safety responses observed in the experiments may not fully reflect how the models would behave in real-world scenarios. The researchers acknowledge that their approach focused on specific, contrived decoding paths, and the models' behavior could differ when faced with more nuanced or contextual safety challenges.
Additionally, the paper does not address potential biases or inconsistencies in the models' safety responses. It's possible that the models may exhibit different levels of sensitivity or reactions depending on the specific content or context, which could lead to unintended consequences or unfair outcomes.
Further research is needed to explore these issues and develop more comprehensive and robust safety frameworks for large language models. Ongoing collaboration between researchers, developers, and end-users will be crucial in ensuring these powerful AI systems are deployed responsibly and with appropriate safeguards in place.
Conclusion
This paper presents a novel approach for probing the safety response boundaries of large language models. By systematically generating potentially unsafe text, the researchers were able to map out the limits of the models' safety mechanisms and identify areas for improvement.
The insights from this work can inform the development of more effective safety systems and help ensure that large language models are deployed in a responsible and trustworthy manner. As these powerful AI systems continue to be integrated into more critical applications, understanding and strengthening their safety features will be of paramount importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Probing the Safety Response Boundary of Large Language Models via Unsafe Decoding Path Generation
Haoyu Wang, Bingzhe Wu, Yatao Bian, Yongzhe Chang, Xueqian Wang, Peilin Zhao
Large Language Models (LLMs) are implicit troublemakers. While they provide valuable insights and assist in problem-solving, they can also potentially serve as a resource for malicious activities. Implementing safety alignment could mitigate the risk of LLMs generating harmful responses. We argue that: even when an LLM appears to successfully block harmful queries, there may still be hidden vulnerabilities that could act as ticking time bombs. To identify these underlying weaknesses, we propose to use a cost value model as both a detector and an attacker. Trained on external or self-generated harmful datasets, the cost value model could successfully influence the original safe LLM to output toxic content in decoding process. For instance, LLaMA-2-chat 7B outputs 39.18% concrete toxic content, along with only 22.16% refusals without any harmful suffixes. These potential weaknesses can then be exploited via prompt optimization such as soft prompts on images. We name this decoding strategy: Jailbreak Value Decoding (JVD), emphasizing that seemingly secure LLMs may not be as safe as we initially believe. They could be used to gather harmful data or launch covert attacks.
Read more8/27/2024

0
SafeDecoding: Defending against Jailbreak Attacks via Safety-Aware Decoding
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, Radha Poovendran
As large language models (LLMs) become increasingly integrated into real-world applications such as code generation and chatbot assistance, extensive efforts have been made to align LLM behavior with human values, including safety. Jailbreak attacks, aiming to provoke unintended and unsafe behaviors from LLMs, remain a significant/leading LLM safety threat. In this paper, we aim to defend LLMs against jailbreak attacks by introducing SafeDecoding, a safety-aware decoding strategy for LLMs to generate helpful and harmless responses to user queries. Our insight in developing SafeDecoding is based on the observation that, even though probabilities of tokens representing harmful contents outweigh those representing harmless responses, safety disclaimers still appear among the top tokens after sorting tokens by probability in descending order. This allows us to mitigate jailbreak attacks by identifying safety disclaimers and amplifying their token probabilities, while simultaneously attenuating the probabilities of token sequences that are aligned with the objectives of jailbreak attacks. We perform extensive experiments on five LLMs using six state-of-the-art jailbreak attacks and four benchmark datasets. Our results show that SafeDecoding significantly reduces the attack success rate and harmfulness of jailbreak attacks without compromising the helpfulness of responses to benign user queries. SafeDecoding outperforms six defense methods.
Read more7/29/2024

0
A False Sense of Safety: Unsafe Information Leakage in 'Safe' AI Responses
David Glukhov, Ziwen Han, Ilia Shumailov, Vardan Papyan, Nicolas Papernot
Large Language Models (LLMs) are vulnerable to jailbreaks$unicode{x2013}$methods to elicit harmful or generally impermissible outputs. Safety measures are developed and assessed on their effectiveness at defending against jailbreak attacks, indicating a belief that safety is equivalent to robustness. We assert that current defense mechanisms, such as output filters and alignment fine-tuning, are, and will remain, fundamentally insufficient for ensuring model safety. These defenses fail to address risks arising from dual-intent queries and the ability to composite innocuous outputs to achieve harmful goals. To address this critical gap, we introduce an information-theoretic threat model called inferential adversaries who exploit impermissible information leakage from model outputs to achieve malicious goals. We distinguish these from commonly studied security adversaries who only seek to force victim models to generate specific impermissible outputs. We demonstrate the feasibility of automating inferential adversaries through question decomposition and response aggregation. To provide safety guarantees, we define an information censorship criterion for censorship mechanisms, bounding the leakage of impermissible information. We propose a defense mechanism which ensures this bound and reveal an intrinsic safety-utility trade-off. Our work provides the first theoretically grounded understanding of the requirements for releasing safe LLMs and the utility costs involved.
Read more7/4/2024
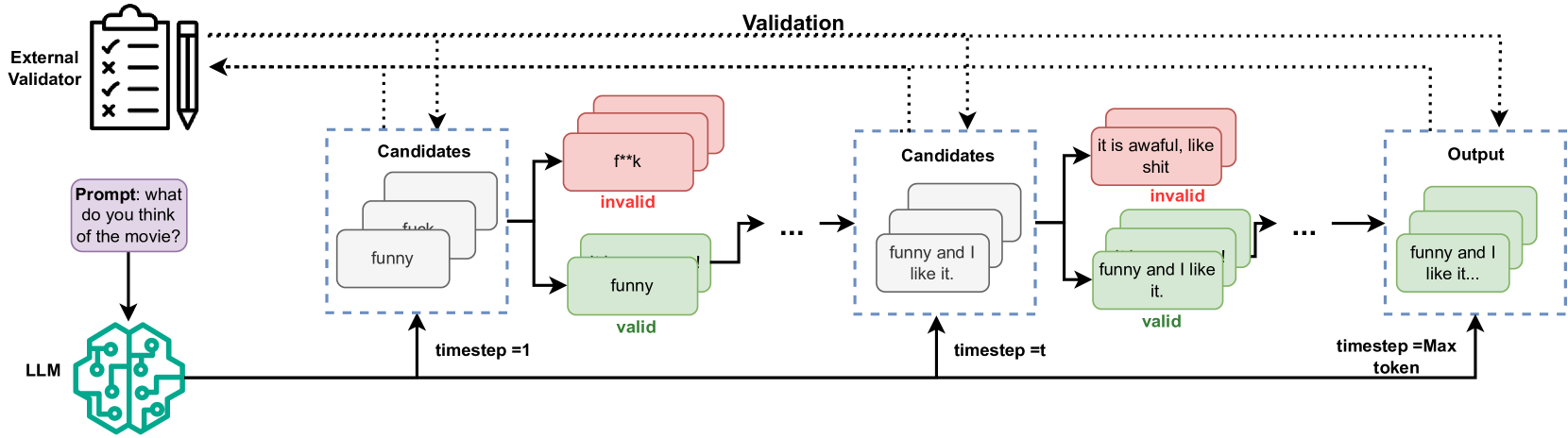
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024