Knowledge Fusion By Evolving Weights of Language Models

0
Sign in to get full access
Overview
- This paper presents a novel approach to knowledge fusion by evolving the weights of language models.
- The proposed method aims to combine the knowledge from multiple pre-trained language models to improve the performance on downstream tasks.
- The authors introduce an evolutionary algorithm that learns the optimal weight combinations for ensemble language models, leveraging the complementary strengths of different models.
Plain English Explanation
The paper discusses a way to combine the knowledge from multiple pre-trained language models, which are AI systems trained on vast amounts of text data to understand and generate human language. The key idea is to use an evolutionary algorithm, a type of optimization technique inspired by biological evolution, to find the best way to blend or "fuse" the knowledge from these different language models.
The researchers hypothesize that each pre-trained language model has its own unique strengths and weaknesses, and by intelligently combining them, the resulting "ensemble" model can perform better on various language-related tasks than any individual model. The evolutionary algorithm tries out different weight combinations for blending the models, and over many iterations, it learns the optimal way to fuse the knowledge from the underlying language models.
This approach allows the researchers to harness the collective intelligence of multiple language models, rather than relying on a single one. The plain English gist is that they're using an AI-powered optimization technique to get the best of multiple AI language models, with the goal of improving the system's overall performance and capabilities.
Technical Explanation
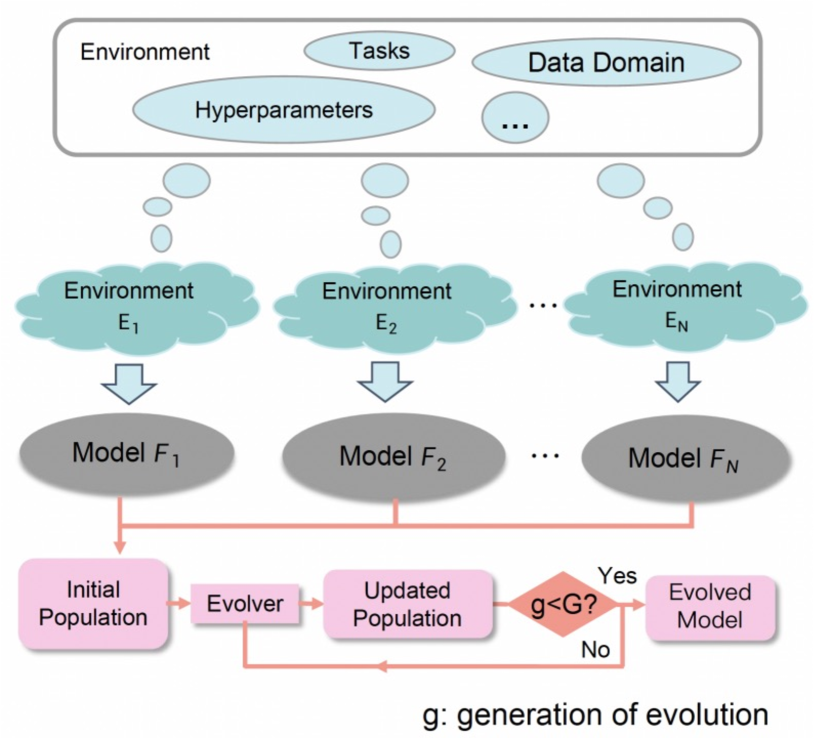
The paper introduces a novel approach to knowledge fusion that involves evolving the weights of language models. The authors propose an evolutionary algorithm that learns the optimal weight combinations for ensembling pre-trained language models, aiming to leverage the complementary strengths of different models.
The key technical elements include:
- Ensemble of Language Models: The researchers combine multiple pre-trained language models, such as BERT, GPT-2, and RoBERTa, to create an ensemble model.
- Evolutionary Algorithm: An evolutionary algorithm is used to optimize the weight combinations for the ensemble. This algorithm iteratively evaluates different weight configurations and selects the best-performing ones to evolve over generations.
- Weight Optimization: The evolutionary algorithm learns the optimal weight distribution for blending the outputs of the individual language models, allowing the ensemble to capitalize on the unique strengths of each model.
- Downstream Task Evaluation: The performance of the evolved ensemble model is evaluated on various downstream tasks, such as question answering, sentiment analysis, and natural language inference.
The results demonstrate that the proposed knowledge fusion approach, termed "Knowledge Fusion By Evolving Weights of Language Models", can outperform individual language models and other ensemble methods on multiple benchmarks. This highlights the potential of using evolutionary techniques to bridge the gap between different vocabularies and language models and automatically transform features for improved performance.
Critical Analysis
The proposed knowledge fusion approach offers a promising direction for leveraging the complementary strengths of multiple language models. However, the paper also acknowledges several caveats and limitations:
-
Computational Complexity: The evolutionary algorithm used for weight optimization can be computationally expensive, especially as the number of language models in the ensemble grows. The authors mention the need for further research into more efficient optimization techniques.
-
Domain-Specific Applicability: The performance gains may be more pronounced on certain types of downstream tasks or domains. The researchers suggest exploring ways to adapt the approach for cost-aware acquisition functions or apply it to agents in simulated environments to better understand its broader applicability.
-
Interpretability: The evolved weight combinations may not be easily interpretable, making it challenging to understand the underlying reasons for the performance improvements. Further research could investigate ways to improve the transparency of the knowledge fusion process.
Despite these limitations, the core idea of leveraging evolutionary techniques to optimize the blending of multiple language models represents a promising direction for advancing the state of the art in natural language processing and knowledge representation.
Conclusion
This paper introduces a novel approach to knowledge fusion that uses an evolutionary algorithm to learn the optimal weight combinations for ensembling pre-trained language models. The key insight is that by intelligently combining the unique strengths of different language models, the resulting ensemble can outperform individual models on a variety of downstream tasks.
The proposed method demonstrates the potential of using evolutionary techniques to bridge the gap between different vocabularies and language models and automatically transform features for improved performance. As the field of natural language processing continues to evolve, this research opens up new avenues for leveraging the collective intelligence of multiple language models to tackle increasingly complex language-related challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Knowledge Fusion By Evolving Weights of Language Models
Guodong Du, Jing Li, Hanting Liu, Runhua Jiang, Shuyang Yu, Yifei Guo, Sim Kuan Goh, Ho-Kin Tang
Fine-tuning pre-trained language models, particularly large language models, demands extensive computing resources and can result in varying performance outcomes across different domains and datasets. This paper examines the approach of integrating multiple models from diverse training scenarios into a unified model. This unified model excels across various data domains and exhibits the ability to generalize well on out-of-domain data. We propose a knowledge fusion method named Evolver, inspired by evolutionary algorithms, which does not need further training or additional training data. Specifically, our method involves aggregating the weights of different language models into a population and subsequently generating offspring models through mutation and crossover operations. These offspring models are then evaluated against their parents, allowing for the preservation of those models that show enhanced performance on development datasets. Importantly, our model evolving strategy can be seamlessly integrated with existing model merging frameworks, offering a versatile tool for model enhancement. Experimental results on mainstream language models (i.e., encoder-only, decoder-only, encoder-decoder) reveal that Evolver outperforms previous state-of-the-art models by large margins. The code is publicly available at {https://github.com/duguodong7/model-evolution}.
Read more6/19/2024
0
ProFuser: Progressive Fusion of Large Language Models
Tianyuan Shi, Fanqi Wan, Canbin Huang, Xiaojun Quan, Chenliang Li, Ming Yan, Ji Zhang
While fusing the capacities and advantages of various large language models (LLMs) offers a pathway to construct more powerful and versatile models, a fundamental challenge is to properly select advantageous model during the training. Existing fusion methods primarily focus on the training mode that uses cross entropy on ground truth in a teacher-forcing setup to measure a model's advantage, which may provide limited insight towards model advantage. In this paper, we introduce a novel approach that enhances the fusion process by incorporating both the training and inference modes. Our method evaluates model advantage not only through cross entropy during training but also by considering inference outputs, providing a more comprehensive assessment. To combine the two modes effectively, we introduce ProFuser to progressively transition from inference mode to training mode. To validate ProFuser's effectiveness, we fused three models, including vicuna-7b-v1.5, Llama-2-7b-chat, and mpt-7b-8k-chat, and demonstrated the improved performance in knowledge, reasoning, and safety compared to baseline methods.
Read more8/12/2024

0
Cool-Fusion: Fuse Large Language Models without Training
Cong Liu, Xiaojun Quan, Yan Pan, Liang Lin, Weigang Wu, Xu Chen
We focus on the problem of fusing two or more heterogeneous large language models (LLMs) to facilitate their complementary strengths. One of the challenges on model fusion is high computational load, i.e. to fine-tune or to align vocabularies via combinatorial optimization. To this end, we propose emph{Cool-Fusion}, a simple yet effective approach that fuses the knowledge of heterogeneous source LLMs to leverage their complementary strengths. emph{Cool-Fusion} is the first method that does not require any type of training like the ensemble approaches. But unlike ensemble methods, it is applicable to any set of source LLMs that have different vocabularies. The basic idea is to have each source LLM individually generate tokens until the tokens can be decoded into a text segment that ends at word boundaries common to all source LLMs. Then, the source LLMs jointly rerank the generated text segment and select the best one, which is the fused text generation in one step. Extensive experiments are conducted across a variety of benchmark datasets. On emph{GSM8K}, emph{Cool-Fusion} increases accuracy from three strong source LLMs by a significant 8%-17.8%.
Read more7/30/2024
💬
0
Carpe Diem: On the Evaluation of World Knowledge in Lifelong Language Models
Yujin Kim, Jaehong Yoon, Seonghyeon Ye, Sangmin Bae, Namgyu Ho, Sung Ju Hwang, Se-young Yun
The dynamic nature of knowledge in an ever-changing world presents challenges for language models trained on static data; the model in the real world often requires not only acquiring new knowledge but also overwriting outdated information into updated ones. To study the ability of language models for these time-dependent dynamics in human language, we introduce a novel task, EvolvingQA, a temporally evolving question-answering benchmark designed for training and evaluating LMs on an evolving Wikipedia database. The construction of EvolvingQA is automated with our pipeline using large language models. We uncover that existing continual learning baselines suffer from updating and removing outdated knowledge. Our analysis suggests that models fail to rectify knowledge due to small weight gradients. In addition, we elucidate that language models particularly struggle to reflect the change of numerical or temporal information. Our work aims to model the dynamic nature of real-world information, suggesting faithful evaluations of the evolution-adaptability of language models.
Read more4/23/2024