Does Pre-trained Language Model Actually Infer Unseen Links in Knowledge Graph Completion?
2311.09109
0
0
💬
Abstract
Knowledge graphs (KGs) consist of links that describe relationships between entities. Due to the difficulty of manually enumerating all relationships between entities, automatically completing them is essential for KGs. Knowledge Graph Completion (KGC) is a task that infers unseen relationships between entities in a KG. Traditional embedding-based KGC methods, such as RESCAL, TransE, DistMult, ComplEx, RotatE, HAKE, HousE, etc., infer missing links using only the knowledge from training data. In contrast, the recent Pre-trained Language Model (PLM)-based KGC utilizes knowledge obtained during pre-training. Therefore, PLM-based KGC can estimate missing links between entities by reusing memorized knowledge from pre-training without inference. This approach is problematic because building KGC models aims to infer unseen links between entities. However, conventional evaluations in KGC do not consider inference and memorization abilities separately. Thus, a PLM-based KGC method, which achieves high performance in current KGC evaluations, may be ineffective in practical applications. To address this issue, we analyze whether PLM-based KGC methods make inferences or merely access memorized knowledge. For this purpose, we propose a method for constructing synthetic datasets specified in this analysis and conclude that PLMs acquire the inference abilities required for KGC through pre-training, even though the performance improvements mostly come from textual information of entities and relations.
Create account to get full access
Overview
- Knowledge Graphs (KGs) are collections of linked entities and relationships between them.
- Automatically completing missing relationships in KGs, known as Knowledge Graph Completion (KGC), is an important task.
- Traditional KGC methods use only the information from training data, while recent Pre-trained Language Model (PLM)-based approaches leverage additional knowledge acquired during pre-training.
- However, the performance improvements of PLM-based KGC methods may come from memorizing textual information rather than true inference abilities.
Plain English Explanation
Knowledge Graphs are like digital maps that show how different things are connected. For example, a Knowledge Graph might show that the movie "The Matrix" was directed by the Wachowskis and starred Keanu Reeves.
Filling in the missing connections in these Knowledge Graphs automatically, called Knowledge Graph Completion, is really important. Traditional methods for this task only use the information in the training data. But newer approaches that use Pre-trained Language Models (PLMs) can also draw on the general knowledge the models learned during pre-training.
The problem is that these PLM-based methods might just be recalling memorized facts, rather than actually understanding the connections between entities and being able to infer new relationships. Current evaluations don't really distinguish between memorization and true inference. So a PLM-based method that does well on standard tests might not actually be very good at the real-world task of Knowledge Graph Completion.
Technical Explanation
The researchers propose a method to analyze whether PLM-based KGC models are making inferences or simply recalling memorized knowledge. They do this by creating synthetic datasets designed to test these capabilities separately.
The key insight is that if a model is truly making inferences, it should be able to generalize to new scenarios not seen during training. But if it's just memorizing facts, it will struggle with these novel situations.
By constructing datasets that isolate these two abilities, the researchers are able to assess how much of a PLM-based KGC model's performance comes from inference versus memorization. They find that while the performance gains mostly stem from the models' ability to leverage textual information about entities and relations, the PLMs do in fact acquire genuine inference capabilities through pre-training.
Critical Analysis
The researchers acknowledge that their synthetic datasets, while designed to isolate specific capabilities, may not fully reflect the complexity of real-world KGs. There could be additional factors at play that their analysis doesn't capture.
Additionally, the paper focuses on standard KGC evaluation metrics, which may not be the best way to assess a model's practical usefulness. Alternative retrieval-augmented approaches could provide a more holistic view of a model's suitability for Knowledge Graph Completion tasks.
Further research is needed to fully understand the extent and limitations of PLM-based KGC methods, as well as how to best evaluate their performance in realistic settings.
Conclusion
This paper provides a nuanced analysis of the capabilities of PLM-based Knowledge Graph Completion models. While these approaches can leverage a wealth of pre-trained knowledge, the researchers show that their performance gains come not just from inference abilities, but also from memorization of textual information.
This insight is important for understanding the true strengths and weaknesses of these models, and for developing more effective ways to leverage large language models for Knowledge Graph Completion and other knowledge-intensive tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multilingual Knowledge Graph Completion from Pretrained Language Models with Knowledge Constraints
Ran Song, Shizhu He, Shengxiang Gao, Li Cai, Kang Liu, Zhengtao Yu, Jun Zhao
0
0
Multilingual Knowledge Graph Completion (mKGC) aim at solving queries like (h, r, ?) in different languages by reasoning a tail entity t thus improving multilingual knowledge graphs. Previous studies leverage multilingual pretrained language models (PLMs) and the generative paradigm to achieve mKGC. Although multilingual pretrained language models contain extensive knowledge of different languages, its pretraining tasks cannot be directly aligned with the mKGC tasks. Moreover, the majority of KGs and PLMs currently available exhibit a pronounced English-centric bias. This makes it difficult for mKGC to achieve good results, particularly in the context of low-resource languages. To overcome previous problems, this paper introduces global and local knowledge constraints for mKGC. The former is used to constrain the reasoning of answer entities, while the latter is used to enhance the representation of query contexts. The proposed method makes the pretrained model better adapt to the mKGC task. Experimental results on public datasets demonstrate that our method outperforms the previous SOTA on Hits@1 and Hits@10 by an average of 12.32% and 16.03%, which indicates that our proposed method has significant enhancement on mKGC.
6/27/2024
💬
Making Large Language Models Perform Better in Knowledge Graph Completion
Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Wen Zhang, Huajun Chen
0
0
Large language model (LLM) based knowledge graph completion (KGC) aims to predict the missing triples in the KGs with LLMs. However, research about LLM-based KGC fails to sufficiently harness LLMs' inference proficiencies, overlooking critical structural information integral to KGs. In this paper, we explore methods to incorporate structural information into the LLMs, with the overarching goal of facilitating structure-aware reasoning. We first discuss on the existing LLM paradigms like in-context learning and instruction tuning, proposing basic structural information injection approaches. Then we propose a Knowledge Prefix Adapter (KoPA) to fulfill this stated goal. The KoPA uses a structural pre-training phase to comprehend the intricate entities and relations within KGs, representing them as structural embeddings. Then KoPA communicates such cross-modal structural information understanding to the LLMs through a knowledge prefix adapter which projects the structural embeddings into the textual space and obtains virtual knowledge tokens positioned as a prefix of the input prompt. We conduct comprehensive experiments and provide incisive analysis concerning how the introduction of cross-modal structural information would be better for LLM's factual knowledge reasoning ability. Our code and data are available at https://github.com/zjukg/KoPA .
4/16/2024
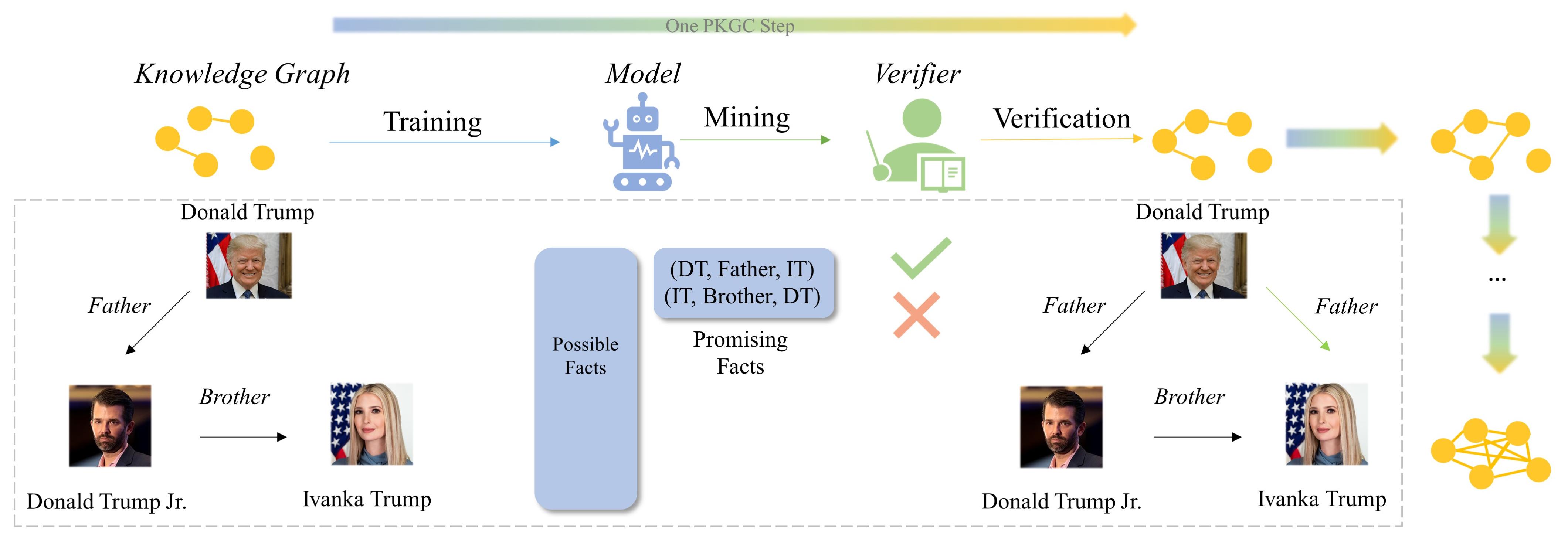
Progressive Knowledge Graph Completion
Jiayi Li, Ruilin Luo, Jiaqi Sun, Jing Xiao, Yujiu Yang
0
0
Knowledge Graph Completion (KGC) has emerged as a promising solution to address the issue of incompleteness within Knowledge Graphs (KGs). Traditional KGC research primarily centers on triple classification and link prediction. Nevertheless, we contend that these tasks do not align well with real-world scenarios and merely serve as surrogate benchmarks. In this paper, we investigate three crucial processes relevant to real-world construction scenarios: (a) the verification process, which arises from the necessity and limitations of human verifiers; (b) the mining process, which identifies the most promising candidates for verification; and (c) the training process, which harnesses verified data for subsequent utilization; in order to achieve a transition toward more realistic challenges. By integrating these three processes, we introduce the Progressive Knowledge Graph Completion (PKGC) task, which simulates the gradual completion of KGs in real-world scenarios. Furthermore, to expedite PKGC processing, we propose two acceleration modules: Optimized Top-$k$ algorithm and Semantic Validity Filter. These modules significantly enhance the efficiency of the mining procedure. Our experiments demonstrate that performance in link prediction does not accurately reflect performance in PKGC. A more in-depth analysis reveals the key factors influencing the results and provides potential directions for future research.
4/16/2024
💬
Enhancing Text-based Knowledge Graph Completion with Zero-Shot Large Language Models: A Focus on Semantic Enhancement
Rui Yang, Jiahao Zhu, Jianping Man, Li Fang, Yi Zhou
0
0
The design and development of text-based knowledge graph completion (KGC) methods leveraging textual entity descriptions are at the forefront of research. These methods involve advanced optimization techniques such as soft prompts and contrastive learning to enhance KGC models. The effectiveness of text-based methods largely hinges on the quality and richness of the training data. Large language models (LLMs) can utilize straightforward prompts to alter text data, thereby enabling data augmentation for KGC. Nevertheless, LLMs typically demand substantial computational resources. To address these issues, we introduce a framework termed constrained prompts for KGC (CP-KGC). This CP-KGC framework designs prompts that adapt to different datasets to enhance semantic richness. Additionally, CP-KGC employs a context constraint strategy to effectively identify polysemous entities within KGC datasets. Through extensive experimentation, we have verified the effectiveness of this framework. Even after quantization, the LLM (Qwen-7B-Chat-int4) still enhances the performance of text-based KGC methods footnote{Code and datasets are available at href{https://github.com/sjlmg/CP-KGC}{https://github.com/sjlmg/CP-KGC}}. This study extends the performance limits of existing models and promotes further integration of KGC with LLMs.
6/28/2024