Progressive Query Expansion for Retrieval Over Cost-constrained Data Sources

0
Sign in to get full access
Overview
- The paper proposes a progressive query expansion (ProQE) method for retrieval over cost-constrained data sources.
- ProQE aims to improve the effectiveness of retrieval while considering the cost constraints of accessing data sources.
- The approach uses large language models and pseudo-relevance feedback to gradually refine the query and optimize the trade-off between effectiveness and cost.
Plain English Explanation
In many real-world scenarios, such as medical question answering or search over web content, the data sources we want to retrieve information from can be costly to access. This could be due to factors like data storage, compute power, or licensing fees. The Progressive Query Expansion (ProQE) method proposed in this paper tries to address this challenge.
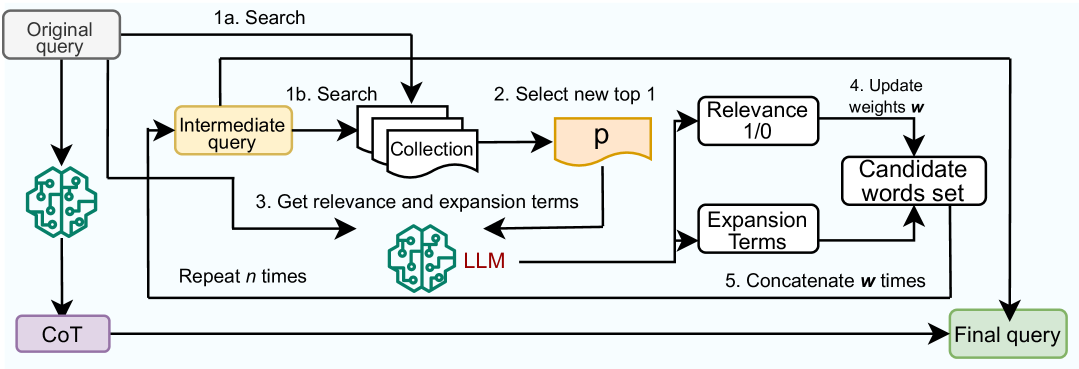
The core idea behind ProQE is to gradually refine the user's original query in a series of steps, using large language models and feedback from the retrieval results. At each step, ProQE evaluates the trade-off between the effectiveness of the retrieval (how well it answers the query) and the cost of accessing the data sources. This allows the system to progressively improve the query while staying within the given cost constraints.
For example, imagine you're searching for information on a rare medical condition. The most relevant data may be stored in specialized, expensive medical databases. ProQE would start with a broad query, then use natural language processing techniques to gradually refine the query, selecting the most relevant and cost-effective data sources at each step. This helps balance the need for high-quality information with the practical constraints of data access.
Technical Explanation
The ProQE method consists of several key components:
-
Initial Query Formulation: The user provides an initial query, which the system then processes using a large language model to extract relevant keywords and concepts.
-
Progressive Query Expansion: ProQE then iteratively refines the query by adding new terms based on pseudo-relevance feedback from the retrieval results. At each step, the system evaluates the trade-off between the effectiveness of the expanded query and the cost of accessing the data sources.
-
Cost-aware Retrieval: ProQE uses a cost model to estimate the access cost for each data source, and it selects the optimal set of sources to query based on the current query and the cost constraints.
-
Result Aggregation: The retrieval results from the selected data sources are then combined and presented to the user, with the most relevant and cost-effective information prioritized.
The authors evaluate ProQE on several benchmark datasets and compare it to a variety of baseline approaches. The results demonstrate that ProQE can effectively improve retrieval performance while staying within the specified cost constraints, outperforming other cost-aware retrieval methods.
Critical Analysis
The paper provides a thoughtful approach to the challenge of cost-constrained data retrieval, but there are a few potential areas for consideration:
- The cost model used in the experiments may not capture all the complexities of real-world data access scenarios, such as variable pricing or dynamic availability of sources.
- The evaluation focuses on standard retrieval metrics, but the user experience and perceived value of the results could be an important factor to consider in a practical deployment.
- The reliance on large language models raises questions about the interpretability and explainability of the query expansion process, which may be important in sensitive domains like medical question answering.
Further research could explore ways to make the cost modeling more flexible, incorporate user feedback into the query refinement process, and investigate the transparency of the ProQE method.
Conclusion
The Progressive Query Expansion (ProQE) approach presented in this paper offers a promising solution for retrieving high-quality information while considering the practical constraints of data access costs. By leveraging large language models and cost-aware optimization, ProQE can gradually refine queries to find the most relevant and cost-effective information sources.
This work has important implications for a wide range of applications, from medical question answering to search over web content, where the ability to balance effectiveness and cost is crucial. As research in generative query reformulation and cost-aware retrieval continues to evolve, approaches like ProQE will play an important role in enabling efficient and accessible information access.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Progressive Query Expansion for Retrieval Over Cost-constrained Data Sources
Muhammad Shihab Rashid, Jannat Ara Meem, Yue Dong, Vagelis Hristidis
Query expansion has been employed for a long time to improve the accuracy of query retrievers. Earlier works relied on pseudo-relevance feedback (PRF) techniques, which augment a query with terms extracted from documents retrieved in a first stage. However, the documents may be noisy hindering the effectiveness of the ranking. To avoid this, recent studies have instead used Large Language Models (LLMs) to generate additional content to expand a query. These techniques are prone to hallucination and also focus on the LLM usage cost. However, the cost may be dominated by the retrieval in several important practical scenarios, where the corpus is only available via APIs which charge a fee per retrieved document. We propose combining classic PRF techniques with LLMs and create a progressive query expansion algorithm ProQE that iteratively expands the query as it retrieves more documents. ProQE is compatible with both sparse and dense retrieval systems. Our experimental results on four retrieval datasets show that ProQE outperforms state-of-the-art baselines by 37% and is the most cost-effective.
Read more6/12/2024

0
Exploring the Best Practices of Query Expansion with Large Language Models
Le Zhang, Yihong Wu, Qian Yang, Jian-Yun Nie
Large Language Models (LLMs) are foundational in language technologies, particularly in information retrieval (IR). Previous studies have utilized LLMs for query expansion, achieving notable improvements in IR. In this paper, we thoroughly explore the best practice of leveraging LLMs for query expansion. To this end, we introduce a training-free, straightforward yet effective framework called Multi-Text Generation Integration (textsc{MuGI}). It leverages LLMs to generate multiple pseudo-references, integrating them with queries to enhance both sparse and dense retrievers. Our empirical findings reveal that: (1) Increasing the number of samples from LLMs benefits IR systems; (2) A balance between the query and pseudo-documents, and an effective integration strategy, is critical for high performance; (3) Contextual information from LLMs is essential, even boost a 23M model to outperform a 7B baseline model; (4) Pseudo relevance feedback can further calibrate queries for improved performance; and (5) Query expansion is widely applicable and versatile, consistently enhancing models ranging from 23M to 7B parameters. Our code and all generated references are made available at url{https://github.com/lezhang7/Retrieval_MuGI}
Read more7/2/2024

0
LLM-PQA: LLM-enhanced Prediction Query Answering
Ziyu Li, Wenjie Zhao, Asterios Katsifodimos, Rihan Hai
The advent of Large Language Models (LLMs) provides an opportunity to change the way queries are processed, moving beyond the constraints of conventional SQL-based database systems. However, using an LLM to answer a prediction query is still challenging, since an external ML model has to be employed and inference has to be performed in order to provide an answer. This paper introduces LLM-PQA, a novel tool that addresses prediction queries formulated in natural language. LLM-PQA is the first to combine the capabilities of LLMs and retrieval-augmented mechanism for the needs of prediction queries by integrating data lakes and model zoos. This integration provides users with access to a vast spectrum of heterogeneous data and diverse ML models, facilitating dynamic prediction query answering. In addition, LLM-PQA can dynamically train models on demand, based on specific query requirements, ensuring reliable and relevant results even when no pre-trained model in a model zoo, available for the task.
Read more9/4/2024
🔮
0
DeeperImpact: Optimizing Sparse Learned Index Structures
Soyuj Basnet, Jerry Gou, Antonio Mallia, Torsten Suel
A lot of recent work has focused on sparse learned indexes that use deep neural architectures to significantly improve retrieval quality while keeping the efficiency benefits of the inverted index. While such sparse learned structures achieve effectiveness far beyond those of traditional inverted index-based rankers, there is still a gap in effectiveness to the best dense retrievers, or even to sparse methods that leverage more expensive optimizations such as query expansion and query term weighting. We focus on narrowing this gap by revisiting and optimizing DeepImpact, a sparse retrieval approach that uses DocT5Query for document expansion followed by a BERT language model to learn impact scores for document terms. We first reinvestigate the expansion process and find that the recently proposed Doc2Query -- query filtration does not enhance retrieval quality when used with DeepImpact. Instead, substituting T5 with a fine-tuned Llama 2 model for query prediction results in a considerable improvement. Subsequently, we study training strategies that have proven effective for other models, in particular the use of hard negatives, distillation, and pre-trained CoCondenser model initialization. Our results substantially narrow the effectiveness gap with the most effective versions of SPLADE.
Read more7/9/2024