Efficiency-Effectiveness Tradeoff of Probabilistic Structured Queries for Cross-Language Information Retrieval

0

Sign in to get full access
Overview
- This paper investigates the efficiency-effectiveness tradeoff of using probabilistic structured queries for cross-language information retrieval.
- The authors explore the performance of probabilistic structured queries compared to traditional bag-of-words queries in terms of both retrieval effectiveness and computational efficiency.
- The paper provides insights into the practical considerations of deploying such a system in real-world settings.
Plain English Explanation
Cross-language information retrieval is the process of finding relevant information in a different language than the one used in the original query. This can be challenging, as the language barrier can make it difficult to accurately match the query to the relevant documents.
The paper looks at using a technique called "probabilistic structured queries" to address this challenge. Instead of simply translating the query words, this approach tries to capture the underlying meaning and structure of the query. By modeling the query probabilistically, the system can better match it to relevant documents, even if the exact words don't line up.
The key question the paper explores is the tradeoff between the effectiveness of this more sophisticated query approach and its computational efficiency. While probabilistic structured queries may be better at finding relevant information, they also require more computational resources to process.
The Selecting Query Bag as Pseudo-Relevance Feedback and IterCQR: Iterative Conversational Query Reformulation for Retrieval Guidance papers provide related context on using query reformulation and feedback to improve cross-language retrieval.
By understanding this efficiency-effectiveness tradeoff, the authors hope to provide practical guidance on deploying probabilistic structured queries in real-world cross-language information retrieval systems.
Technical Explanation
The paper evaluates the performance of probabilistic structured queries compared to traditional bag-of-words queries for cross-language information retrieval. Probabilistic structured queries model the query as a distribution over latent concepts, rather than just a set of keywords.
The authors implement this approach using a statistical machine translation model to translate the query into the target language, and then build a probabilistic structured query based on the translated terms and their associated probabilities. This allows the retrieval system to better capture the underlying semantics of the query, rather than just its surface-level lexical representation.
The key experiments compare the retrieval effectiveness (as measured by standard metrics like NDCG) and computational efficiency (as measured by query processing time) of the probabilistic structured queries versus the bag-of-words approach. The results show that the probabilistic structured queries can achieve significantly better retrieval effectiveness, but at the cost of increased computational complexity.
The authors discuss how these findings can inform the practical deployment of such a system, highlighting the need to balance the tradeoffs between effectiveness and efficiency based on the specific requirements and constraints of the application. The ProbGaTE @ EHRSQL 2024: Enhancing SQL Query and TrustSQL: A Reliability Benchmark for Text-to-SQL Models papers provide related context on balancing effectiveness and efficiency in language-based retrieval and query systems.
Critical Analysis
The paper provides a thorough and well-designed empirical evaluation of the efficiency-effectiveness tradeoff for probabilistic structured queries in cross-language information retrieval. The authors carefully consider the practical implications of their findings, acknowledging the need to balance the improved retrieval performance against the increased computational cost.
One potential limitation of the study is the reliance on a single statistical machine translation model for the query translation component. The performance of the probabilistic structured queries may be sensitive to the quality and accuracy of the translation, which could vary across different language pairs and translation models. Exploring the robustness of the approach to different translation systems would strengthen the generalizability of the findings.
Additionally, the paper does not delve into the specific factors that contribute to the increased computational complexity of the probabilistic structured queries. A more detailed analysis of the sources of this overhead, such as the cost of building the query distributions or the complexity of the retrieval algorithm, could provide further insights to guide practical system design decisions.
Overall, the paper presents a valuable contribution to the understanding of the tradeoffs involved in deploying advanced query formulation techniques, such as the probabilistic structured queries, in real-world cross-language information retrieval systems. The findings and discussions can inform the development of more efficient and effective language-based retrieval solutions, as exemplified by the PerkweCOQA: Enhanced Persian Conversational Question Answering system.
Conclusion
This paper investigates the efficiency-effectiveness tradeoff of using probabilistic structured queries for cross-language information retrieval. The authors found that while the probabilistic structured queries can significantly improve retrieval performance, they also incur higher computational costs compared to traditional bag-of-words queries.
These findings have important practical implications for the deployment of such systems in real-world settings, where balancing retrieval effectiveness and computational efficiency is crucial. The paper provides valuable insights to guide the design of cross-language information retrieval systems that can effectively leverage advanced query formulation techniques while maintaining acceptable levels of efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficiency-Effectiveness Tradeoff of Probabilistic Structured Queries for Cross-Language Information Retrieval
Eugene Yang, Suraj Nair, Dawn Lawrie, James Mayfield, Douglas W. Oard, Kevin Duh
Probabilistic Structured Queries (PSQ) is a cross-language information retrieval (CLIR) method that uses translation probabilities statistically derived from aligned corpora. PSQ is a strong baseline for efficient CLIR using sparse indexing. It is, therefore, useful as the first stage in a cascaded neural CLIR system whose second stage is more effective but too inefficient to be used on its own to search a large text collection. In this reproducibility study, we revisit PSQ by introducing an efficient Python implementation. Unconstrained use of all translation probabilities that can be estimated from aligned parallel text would in the limit assign a weight to every vocabulary term, precluding use of an inverted index to serve queries efficiently. Thus, PSQ's effectiveness and efficiency both depend on how translation probabilities are pruned. This paper presents experiments over a range of modern CLIR test collections to demonstrate that achieving Pareto optimal PSQ effectiveness-efficiency tradeoffs benefits from multi-criteria pruning, which has not been fully explored in prior work. Our Python PSQ implementation is available on GitHub(https://github.com/hltcoe/PSQ) and unpruned translation tables are available on Huggingface Models(https://huggingface.co/hltcoe/psq_translation_tables).
Read more4/30/2024
0
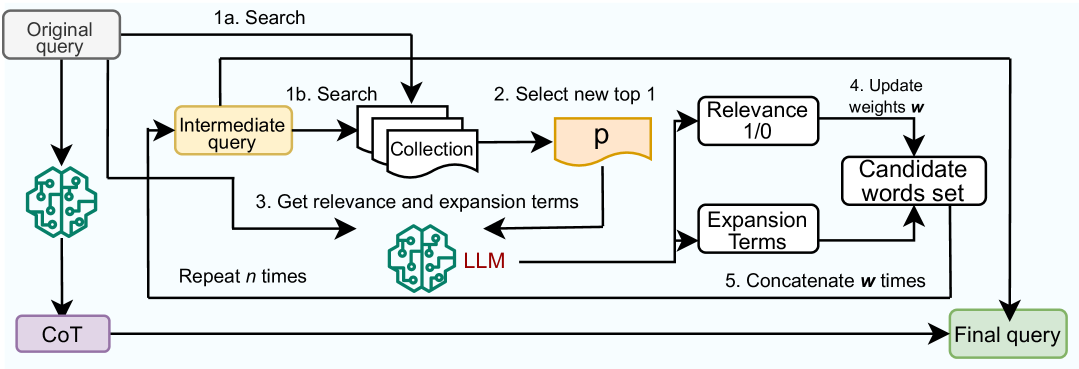
Progressive Query Expansion for Retrieval Over Cost-constrained Data Sources
Muhammad Shihab Rashid, Jannat Ara Meem, Yue Dong, Vagelis Hristidis
Query expansion has been employed for a long time to improve the accuracy of query retrievers. Earlier works relied on pseudo-relevance feedback (PRF) techniques, which augment a query with terms extracted from documents retrieved in a first stage. However, the documents may be noisy hindering the effectiveness of the ranking. To avoid this, recent studies have instead used Large Language Models (LLMs) to generate additional content to expand a query. These techniques are prone to hallucination and also focus on the LLM usage cost. However, the cost may be dominated by the retrieval in several important practical scenarios, where the corpus is only available via APIs which charge a fee per retrieved document. We propose combining classic PRF techniques with LLMs and create a progressive query expansion algorithm ProQE that iteratively expands the query as it retrieves more documents. ProQE is compatible with both sparse and dense retrieval systems. Our experimental results on four retrieval datasets show that ProQE outperforms state-of-the-art baselines by 37% and is the most cost-effective.
Read more6/12/2024

0
Synergistic Approach for Simultaneous Optimization of Monolingual, Cross-lingual, and Multilingual Information Retrieval
Adel Elmahdy, Sheng-Chieh Lin, Amin Ahmad
Information retrieval across different languages is an increasingly important challenge in natural language processing. Recent approaches based on multilingual pre-trained language models have achieved remarkable success, yet they often optimize for either monolingual, cross-lingual, or multilingual retrieval performance at the expense of others. This paper proposes a novel hybrid batch training strategy to simultaneously improve zero-shot retrieval performance across monolingual, cross-lingual, and multilingual settings while mitigating language bias. The approach fine-tunes multilingual language models using a mix of monolingual and cross-lingual question-answer pair batches sampled based on dataset size. Experiments on XQuAD-R, MLQA-R, and MIRACL benchmark datasets show that the proposed method consistently achieves comparable or superior results in zero-shot retrieval across various languages and retrieval tasks compared to monolingual-only or cross-lingual-only training. Hybrid batch training also substantially reduces language bias in multilingual retrieval compared to monolingual training. These results demonstrate the effectiveness of the proposed approach for learning language-agnostic representations that enable strong zero-shot retrieval performance across diverse languages.
Read more8/21/2024

0
Selecting Query-bag as Pseudo Relevance Feedback for Information-seeking Conversations
Xiaoqing Zhang, Xiuying Chen, Shen Gao, Shuqi Li, Xin Gao, Ji-Rong Wen, Rui Yan
Information-seeking dialogue systems are widely used in e-commerce systems, with answers that must be tailored to fit the specific settings of the online system. Given the user query, the information-seeking dialogue systems first retrieve a subset of response candidates, then further select the best response from the candidate set through re-ranking. Current methods mainly retrieve response candidates based solely on the current query, however, incorporating similar questions could introduce more diverse content, potentially refining the representation and improving the matching process. Hence, in this paper, we proposed a Query-bag based Pseudo Relevance Feedback framework (QB-PRF), which constructs a query-bag with related queries to serve as pseudo signals to guide information-seeking conversations. Concretely, we first propose a Query-bag Selection module (QBS), which utilizes contrastive learning to train the selection of synonymous queries in an unsupervised manner by leveraging the representations learned from pre-trained VAE. Secondly, we come up with a Query-bag Fusion module (QBF) that fuses synonymous queries to enhance the semantic representation of the original query through multidimensional attention computation. We verify the effectiveness of the QB-PRF framework on two competitive pretrained backbone models, including BERT and GPT-2. Experimental results on two benchmark datasets show that our framework achieves superior performance over strong baselines.
Read more4/9/2024