DeeperImpact: Optimizing Sparse Learned Index Structures

0
🔮
Sign in to get full access
Overview
- This research paper, titled "DeeperImpact: Optimizing Sparse Learned Index Structures", explores techniques to improve the efficiency of learned index structures, which are a type of data structure used for indexing and searching large datasets.
- The authors propose several novel optimizations to make these learned index structures more compact and faster, allowing them to be used effectively in a wider range of applications.
- The paper presents a comprehensive evaluation of their proposed techniques, demonstrating significant performance improvements over existing approaches.
Plain English Explanation
Searching through large amounts of data can be a challenging task, especially as the size of datasets continues to grow. One way to make this process more efficient is to use a special type of data structure called a "learned index structure". These structures use machine learning models to predict where data is located, rather than relying on traditional index methods.
The researchers in this paper wanted to find ways to make these learned index structures even better. They developed several new techniques to optimize the size and speed of these structures, so they can be used in more real-world applications.
For example, one of their innovations was to make the index structures more "sparse" - meaning they only store the most important information, without wasting space on unnecessary details. This helps the structures take up less memory, while still maintaining their search performance.
The researchers also found ways to "deeper" optimize the internal structures of the learned indexes, further boosting their efficiency. They tested these ideas extensively and showed that their optimized approach, called "DeeperImpact", significantly outperforms existing learned index techniques.
By making learned indexes more compact and faster, this research helps open up new possibilities for using these powerful data structures in a wider range of applications, from efficient inverted indexes for approximate retrieval to entity linking and information retrieval. The authors' innovations could lead to more efficient and scalable search and retrieval systems in the future.
Technical Explanation
The core idea behind learned index structures is to use machine learning models to predict where data is located, rather than relying on traditional index methods like B-trees or hash tables. This can provide significant performance benefits, as the learned models can often make more accurate predictions than standard indexing approaches.
However, a key challenge with learned indexes is that the machine learning models themselves can be large and complex, taking up a lot of memory and computational resources. To address this, the researchers in this paper propose several novel techniques to optimize the learned index structure:
-
Sparse Learned Indexes: They develop methods to make the learned index models more "sparse", only storing the most important parameters and discarding less relevant information. This reduces the memory footprint of the indexes without significantly impacting their search performance.
-
Deeper Optimizations: The authors explore deeper architectural and training changes to the learned index models, further enhancing their efficiency. This includes techniques like sparse late interaction and efficient, interpretable retrieval.
-
Comprehensive Evaluation: The paper provides a thorough evaluation of their proposed techniques, comparing against state-of-the-art learned index approaches on a variety of real-world datasets and workloads. They demonstrate significant improvements in terms of index size, lookup time, and overall system performance.
By making learned indexes more compact and efficient, this research helps enable their use in a wider range of applications, from approximate retrieval over large datasets to product search and question answering systems. The authors' innovations represent an important step forward in the development of scalable and high-performance indexing and retrieval solutions.
Critical Analysis
The researchers in this paper have done a commendable job of identifying and addressing key challenges in making learned index structures more practical and widely applicable. Their proposed techniques, such as sparse modeling and deeper architectural optimizations, appear to be well-designed and effectively implemented based on the results presented.
One potential area for further investigation is the generalizability of their approach. While the authors demonstrate strong performance on the datasets and workloads they evaluated, it would be valuable to see how their techniques scale and perform on even larger or more diverse datasets. Additionally, exploring the tradeoffs between index size, lookup speed, and other relevant metrics in different application domains could provide further insights.
Another aspect that could be explored is the interpretability and explainability of the learned index models. As these models become more complex, understanding their inner workings and the reasons for their predictions can be important, especially in sensitive or high-stakes applications. Techniques like efficient, interpretable information retrieval may be beneficial in this regard.
Overall, the research presented in this paper represents a significant contribution to the field of indexing and retrieval, and the authors' optimizations of learned index structures are likely to have a positive impact on a wide range of real-world applications.
Conclusion
This paper on "DeeperImpact: Optimizing Sparse Learned Index Structures" introduces several novel techniques to improve the efficiency and practicality of learned index structures, a powerful data structure used for indexing and searching large datasets.
The researchers developed methods to make these learned indexes more compact and faster, including sparse modeling and deeper architectural optimizations. Their comprehensive evaluation demonstrated significant performance improvements over existing approaches, paving the way for the use of learned indexes in a wider range of applications, from approximate retrieval to entity linking and information retrieval.
By addressing key challenges in making learned indexes more practical, this research represents an important step forward in the development of scalable and high-performance indexing and search solutions. The insights and innovations presented in this paper have the potential to enable more efficient and effective data management and retrieval systems, with far-reaching implications for fields that rely on the ability to quickly and accurately access large amounts of information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
DeeperImpact: Optimizing Sparse Learned Index Structures
Soyuj Basnet, Jerry Gou, Antonio Mallia, Torsten Suel
A lot of recent work has focused on sparse learned indexes that use deep neural architectures to significantly improve retrieval quality while keeping the efficiency benefits of the inverted index. While such sparse learned structures achieve effectiveness far beyond those of traditional inverted index-based rankers, there is still a gap in effectiveness to the best dense retrievers, or even to sparse methods that leverage more expensive optimizations such as query expansion and query term weighting. We focus on narrowing this gap by revisiting and optimizing DeepImpact, a sparse retrieval approach that uses DocT5Query for document expansion followed by a BERT language model to learn impact scores for document terms. We first reinvestigate the expansion process and find that the recently proposed Doc2Query -- query filtration does not enhance retrieval quality when used with DeepImpact. Instead, substituting T5 with a fine-tuned Llama 2 model for query prediction results in a considerable improvement. Subsequently, we study training strategies that have proven effective for other models, in particular the use of hard negatives, distillation, and pre-trained CoCondenser model initialization. Our results substantially narrow the effectiveness gap with the most effective versions of SPLADE.
Read more7/9/2024
🚀
0
Efficient Inverted Indexes for Approximate Retrieval over Learned Sparse Representations
Sebastian Bruch, Franco Maria Nardini, Cosimo Rulli, Rossano Venturini
Learned sparse representations form an attractive class of contextual embeddings for text retrieval. That is so because they are effective models of relevance and are interpretable by design. Despite their apparent compatibility with inverted indexes, however, retrieval over sparse embeddings remains challenging. That is due to the distributional differences between learned embeddings and term frequency-based lexical models of relevance such as BM25. Recognizing this challenge, a great deal of research has gone into, among other things, designing retrieval algorithms tailored to the properties of learned sparse representations, including approximate retrieval systems. In fact, this task featured prominently in the latest BigANN Challenge at NeurIPS 2023, where approximate algorithms were evaluated on a large benchmark dataset by throughput and recall. In this work, we propose a novel organization of the inverted index that enables fast yet effective approximate retrieval over learned sparse embeddings. Our approach organizes inverted lists into geometrically-cohesive blocks, each equipped with a summary vector. During query processing, we quickly determine if a block must be evaluated using the summaries. As we show experimentally, single-threaded query processing using our method, Seismic, reaches sub-millisecond per-query latency on various sparse embeddings of the MS MARCO dataset while maintaining high recall. Our results indicate that Seismic is one to two orders of magnitude faster than state-of-the-art inverted index-based solutions and further outperforms the winning (graph-based) submissions to the BigANN Challenge by a significant margin.
Read more4/30/2024
📊
0
Efficient and Interpretable Information Retrieval for Product Question Answering with Heterogeneous Data
Biplob Biswas, Rajiv Ramnath
Expansion-enhanced sparse lexical representation improves information retrieval (IR) by minimizing vocabulary mismatch problems during lexical matching. In this paper, we explore the potential of jointly learning dense semantic representation and combining it with the lexical one for ranking candidate information. We present a hybrid information retrieval mechanism that maximizes lexical and semantic matching while minimizing their shortcomings. Our architecture consists of dual hybrid encoders that independently encode queries and information elements. Each encoder jointly learns a dense semantic representation and a sparse lexical representation augmented by a learnable term expansion of the corresponding text through contrastive learning. We demonstrate the efficacy of our model in single-stage ranking of a benchmark product question-answering dataset containing the typical heterogeneous information available on online product pages. Our evaluation demonstrates that our hybrid approach outperforms independently trained retrievers by 10.95% (sparse) and 2.7% (dense) in MRR@5 score. Moreover, our model offers better interpretability and performs comparably to state-of-the-art cross encoders while reducing response time by 30% (latency) and cutting computational load by approximately 38% (FLOPs).
Read more5/24/2024
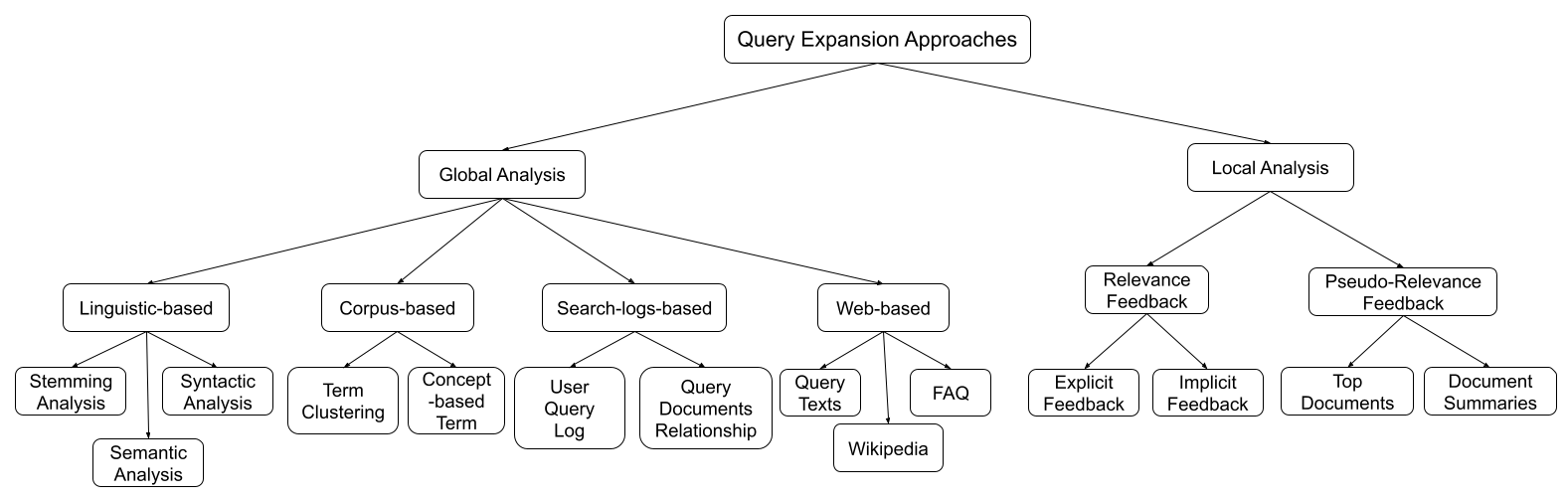
1
Information Retrieval with Entity Linking
Dahlia Shehata
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, I propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. A zero-shot end-to-end dense entity linking system is employed for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, I believe that the effectiveness gap between sparse and dense retrievers can be narrowed. Experiments are conducted on the MS MARCO passage dataset using the original qrel set, the re-ranked qrels favoured by MonoT5 and the latter set further re-ranked by DuoT5. Since I am concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, the results are evaluated using recall@1000. The suggested approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work.
Read more4/16/2024