Prompt Cache: Modular Attention Reuse for Low-Latency Inference
2311.04934
0
0
🤯
Abstract
We present Prompt Cache, an approach for accelerating inference for large language models (LLM) by reusing attention states across different LLM prompts. Many input prompts have overlapping text segments, such as system messages, prompt templates, and documents provided for context. Our key insight is that by precomputing and storing the attention states of these frequently occurring text segments on the inference server, we can efficiently reuse them when these segments appear in user prompts. Prompt Cache employs a schema to explicitly define such reusable text segments, called prompt modules. The schema ensures positional accuracy during attention state reuse and provides users with an interface to access cached states in their prompt. Using a prototype implementation, we evaluate Prompt Cache across several LLMs. We show that Prompt Cache significantly reduce latency in time-to-first-token, especially for longer prompts such as document-based question answering and recommendations. The improvements range from 8x for GPU-based inference to 60x for CPU-based inference, all while maintaining output accuracy and without the need for model parameter modifications.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Prompt Cache is an approach to accelerate inference for large language models (LLMs) by reusing attention states across different prompts.
- Many input prompts have overlapping text segments, such as system messages, prompt templates, and context documents.
- Prompt Cache precomputes and stores the attention states of these frequently occurring text segments, allowing them to be efficiently reused when these segments appear in user prompts.
- Prompt Cache employs a schema to define reusable text segments, called prompt modules, ensuring positional accuracy during attention state reuse.
- The authors evaluate Prompt Cache across several LLMs, showing significant reductions in latency, especially for longer prompts, without compromising output accuracy or requiring model parameter modifications.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, running these models to generate responses can be computationally intensive and slow, especially for longer input prompts.
The key insight behind Prompt Cache is that many input prompts actually have overlapping text segments, such as common system messages, template structures, or context documents. By precomputing and storing the attention states (a crucial part of the model's internal processing) for these frequently occurring text segments, Prompt Cache can efficiently reuse these states when the same segments appear in new user prompts.
This allows Prompt Cache to significantly reduce the time it takes to generate the first token of a response, especially for longer prompts like those used in document-based question answering or recommendation systems. The authors demonstrate improvements ranging from 8 times faster on GPUs to 60 times faster on CPUs, all while maintaining the accuracy of the model's outputs and without requiring any changes to the model parameters themselves.
The key innovation in Prompt Cache is the use of a schema to define these reusable text segments, called "prompt modules." This schema ensures that the attention states can be properly aligned and reused, even when the prompt modules appear in different positions within the overall prompt. This allows Prompt Cache to be a general-purpose approach that can work across a wide range of LLM applications.
Technical Explanation
The core insight behind Prompt Cache is that many input prompts to large language models (LLMs) have overlapping text segments, such as system messages, prompt templates, and context documents. By precomputing and storing the attention states for these frequently occurring text segments, the authors show that Prompt Cache can significantly accelerate inference, especially for longer prompts.
Prompt Cache employs a schema to explicitly define these reusable text segments, called "prompt modules." The schema ensures positional accuracy during attention state reuse, allowing the cached states to be properly aligned and applied when the prompt modules appear in new user prompts.
The authors evaluate Prompt Cache across several LLMs, including GPT-3, InstructGPT, and PaLM. They find that Prompt Cache can reduce the time-to-first-token latency by up to 8 times on GPU-based inference and up to 60 times on CPU-based inference, without compromising output accuracy. These improvements are particularly pronounced for longer prompts, such as those used in document-based question answering and recommendation systems.
Prompt Cache achieves these performance gains by avoiding the need to recompute attention states for the repeated text segments, which can be a significant portion of the overall inference time, especially for larger models and longer inputs. The authors also show that Prompt Cache can be used in conjunction with other acceleration techniques, such as SuperPosition Prompting and Convolutional Prompting, to further improve inference performance.
Critical Analysis
The Prompt Cache paper presents a promising approach for accelerating inference in large language models, but it also raises some potential concerns and areas for further research.
One key limitation is the reliance on the explicit definition of reusable "prompt modules" through the Prompt Cache schema. While this approach ensures positional accuracy during attention state reuse, it may not be feasible to define such modules for all possible input prompts, especially in more open-ended or dynamic scenarios. The authors acknowledge this and suggest exploring more automated methods for identifying reusable text segments, such as through Adapting LLMs or Deconstructing Context techniques.
Additionally, the paper does not explore the potential impact of Prompt Cache on the model's overall generalization capabilities or robustness. While the authors demonstrate maintained output accuracy, it's possible that the reuse of attention states could introduce biases or other unintended consequences that may need to be carefully studied.
Finally, the paper focuses primarily on the performance gains achieved through Prompt Cache, but does not delve into the potential trade-offs, such as the additional memory requirements for storing the precomputed attention states or the potential overhead of managing the cache. Further research could investigate these aspects and explore ways to optimize the system for different deployment scenarios.
Conclusion
Prompt Cache presents a novel approach for accelerating inference in large language models by reusing attention states across different prompts. The key insight is that many input prompts have overlapping text segments, which can be precomputed and stored to avoid recomputation during inference.
The authors demonstrate significant performance improvements, ranging from 8 times faster on GPUs to 60 times faster on CPUs, without compromising output accuracy or requiring model parameter modifications. This could have important implications for real-world applications of LLMs, particularly in scenarios where low-latency responses are critical, such as in interactive chatbots or recommendation systems.
While the Prompt Cache approach shows promise, there are still some areas that merit further exploration, such as more automated methods for identifying reusable text segments and the potential impact on model generalization and robustness. As the field of large language models continues to evolve, techniques like Prompt Cache will likely play an increasingly important role in making these powerful AI systems more efficient and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
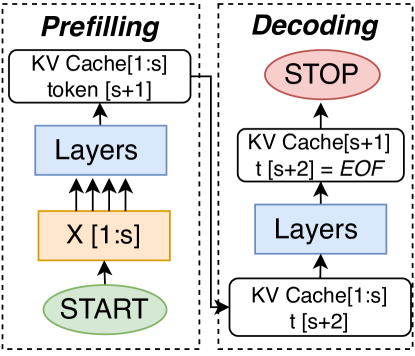
AttentionStore: Cost-effective Attention Reuse across Multi-turn Conversations in Large Language Model Serving
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, Pengfei Zuo
0
0
Interacting with humans through multi-turn conversations is a fundamental feature of large language models (LLMs). However, existing LLM serving engines for executing multi-turn conversations are inefficient due to the need to repeatedly compute the key-value (KV) caches of historical tokens, incurring high serving costs. To address the problem, this paper proposes AttentionStore, a new attention mechanism that enables the reuse of KV caches (i.e., attention reuse) across multi-turn conversations, significantly reducing the repetitive computation overheads. AttentionStore maintains a hierarchical KV caching system that leverages cost-effective memory/storage mediums to save KV caches for all requests. To reduce KV cache access overheads from slow mediums, AttentionStore employs layer-wise pre-loading and asynchronous saving schemes to overlap the KV cache access with the GPU computation. To ensure that the KV caches to be accessed are placed in the fastest hierarchy, AttentionStore employs scheduler-aware fetching and eviction schemes to consciously place the KV caches in different layers based on the hints from the inference job scheduler. To avoid the invalidation of the saved KV caches incurred by context window overflow, AttentionStore enables the saved KV caches to remain valid via decoupling the positional encoding and effectively truncating the KV caches. Extensive experimental results demonstrate that AttentionStore significantly decreases the time to the first token (TTFT) by up to 88%, improves the prompt prefilling throughput by 8.2$times$ for multi-turn conversations, and reduces the end-to-end inference cost by up to 56%. For long sequence inference, AttentionStore reduces the TTFT by up to 95% and improves the prompt prefilling throughput by 22$times$.
4/1/2024
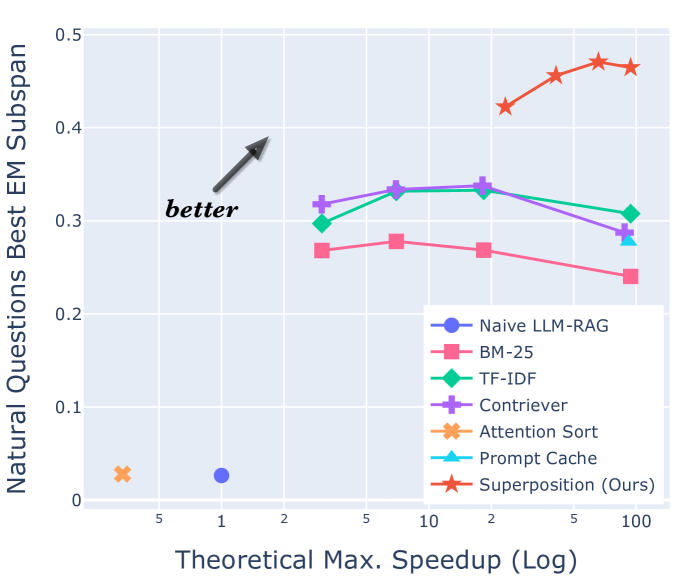
Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation
Thomas Merth, Qichen Fu, Mohammad Rastegari, Mahyar Najibi
0
0
Despite the successes of large language models (LLMs), they exhibit significant drawbacks, particularly when processing long contexts. Their inference cost scales quadratically with respect to sequence length, making it expensive for deployment in some real-world text processing applications, such as retrieval-augmented generation (RAG). Additionally, LLMs also exhibit the distraction phenomenon, where irrelevant context in the prompt degrades output quality. To address these drawbacks, we propose a novel RAG prompting methodology, superposition prompting, which can be directly applied to pre-trained transformer-based LLMs without the need for fine-tuning. At a high level, superposition prompting allows the LLM to process input documents in parallel prompt paths, discarding paths once they are deemed irrelevant. We demonstrate the capability of our method to simultaneously enhance time efficiency across a variety of question-answering benchmarks using multiple pre-trained LLMs. Furthermore, our technique significantly improves accuracy when the retrieved context is large relative the context the model was trained on. For example, our approach facilitates an 93x reduction in compute time while improving accuracy by 43% on the NaturalQuestions-Open dataset with the MPT-7B instruction-tuned model over naive RAG.
4/11/2024
🛠️
APrompt4EM: Augmented Prompt Tuning for Generalized Entity Matching
Yikuan Xia, Jiazun Chen, Xinchi Li, Jun Gao
0
0
Generalized Entity Matching (GEM), which aims at judging whether two records represented in different formats refer to the same real-world entity, is an essential task in data management. The prompt tuning paradigm for pre-trained language models (PLMs), including the recent PromptEM model, effectively addresses the challenges of low-resource GEM in practical applications, offering a robust solution when labeled data is scarce. However, existing prompt tuning models for GEM face the challenges of prompt design and information gap. This paper introduces an augmented prompt tuning framework for the challenges, which consists of two main improvements. The first is an augmented contextualized soft token-based prompt tuning method that extracts a guiding soft token benefit for the PLMs' prompt tuning, and the second is a cost-effective information augmentation strategy leveraging large language models (LLMs). Our approach performs well on the low-resource GEM challenges. Extensive experiments show promising advancements of our basic model without information augmentation over existing methods based on moderate-size PLMs (average 5.24%+), and our model with information augmentation achieves comparable performance compared with fine-tuned LLMs, using less than 14% of the API fee.
5/9/2024
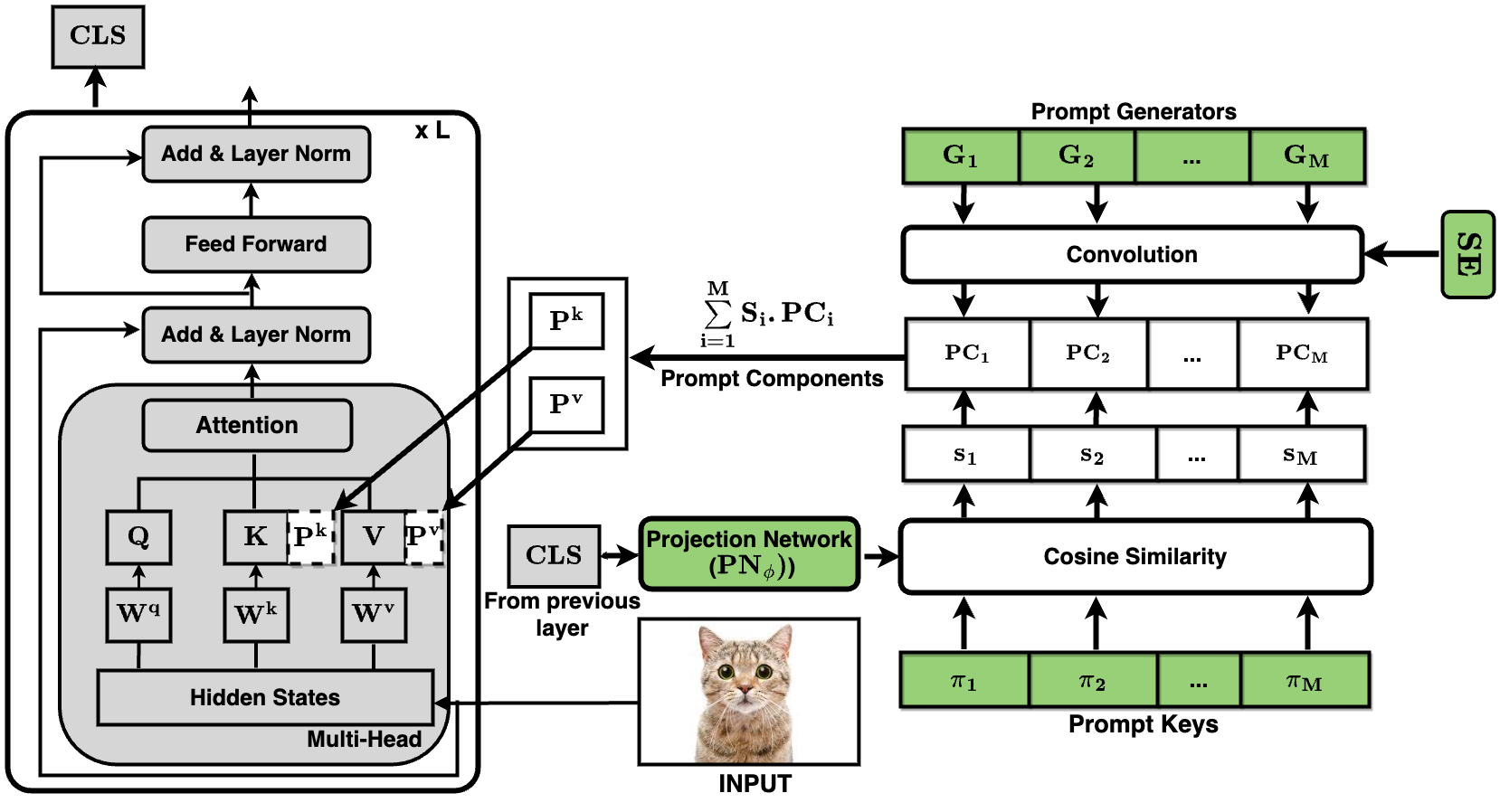
Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy, Riddhiman Moulick, Vinay K. Verma, Saptarshi Ghosh, Abir Das
0
0
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pretrained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by ~3% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components.
4/1/2024